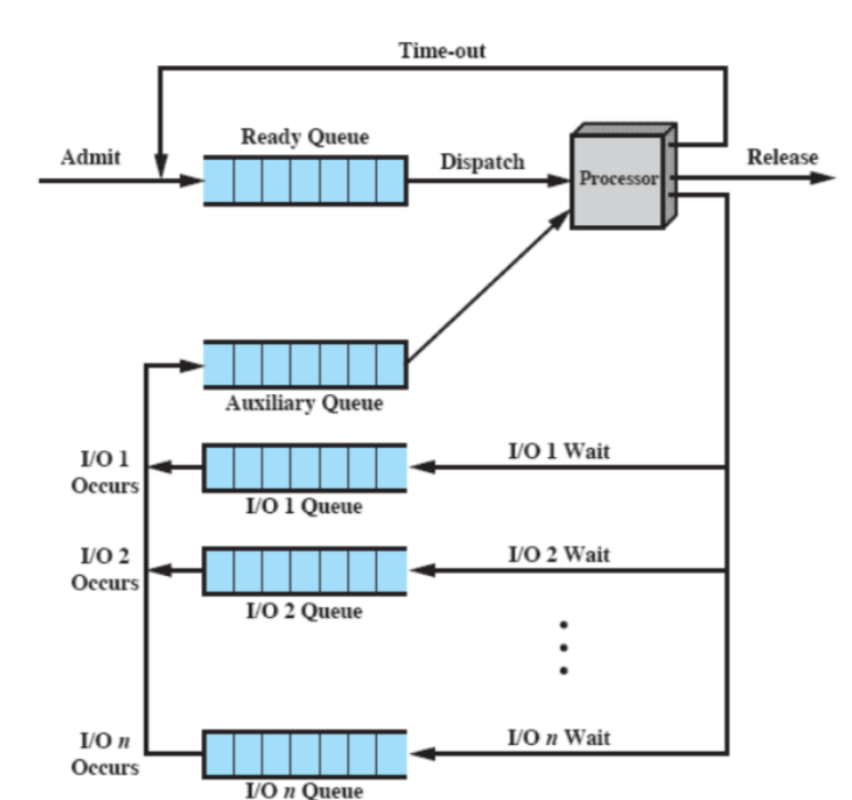
Related
Introduzione
Ci sono diversi tipi di algoritmi che possono essere utilizzati per scegliere quale processo mandare in esecuzione, questo algoritmi variano nelle loro prestazioni e in base su quali parametri utilizzano per effettuare le scelte.
Schema Riassuntivo
- Le colonne indicano il tipo di algoritmo
- Le prime 2 righe indicano i parametri utilizzati per la scelta
- Le restanti righe ci mostrano le caratteristiche e prestazione degli algoritmi
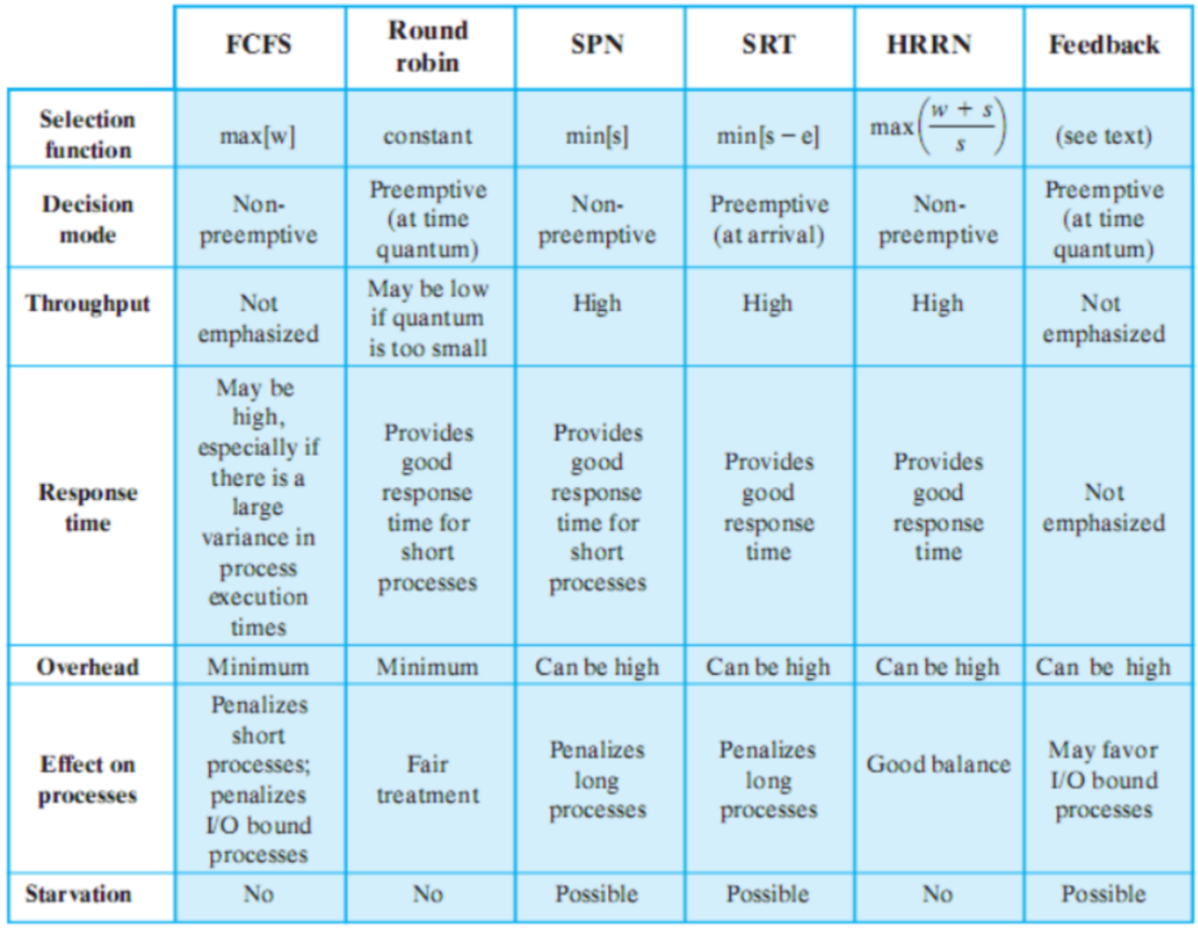
In particolare tutti gli algoritmi, per effettuare effettuare delle scelte utilizzano:
Selection Function
È una formula matematica utilizzata per decidere quale processo mandare in esecuzione, si basa sulle caratteristiche dell’esecuzione come:
w: Tempo trascorso in attesa
e: Tempo trascorso in esecuzione
s: Tempo totale richiestooss: un processo appena creato avrà il tempo di esecuzione a 0 (
e = 0) mentre il tempo totale richiesto (s) può essere calcolato attraverso una stima o viene fornita una deadline.
Decision Mode
Specifica quando viene invocata la funzione di selezione, ci sono due modalità:
Non-Preemptive: Funzione di selezione viene invocata se un processo arriva a terminazione (fine dell’esecuzione) o ad una richiesta bloccante (interrupt)
Preemptive: Il sistema operativo può interrompere un processo in esecuzione e mandarlo in stato di ready. Questo blocco può avvenire o per l’arrivo di nuovi processi o per un interrupt:
- Interrupt I/O: Un processo blocked diventa ready
- Clock Interrupt: Avviene in modo periodico per evitare che un processo monopolizzi il sistema
Algoritmi
Gli algoritmi più noti per la scelta dei processi da eseguire sono:
- FCFS (First Come First Served)
- Round Robin
- SPN (Short Process Next)
- SRT (Shortest Remaining Time)
- HRRN (Highest Response Ratio Next)
- Feedback
Nei sistemi operativi moderni, questi algoritmi non sono solitamente utilizzati direttamente, ma costituiscono la base per quelli utilizzati nel mondo reale. Ad esempio, Linux utilizza una versione migliorata e modificata dell’algoritmo Feedback.
Processi utilizzati per gli esempi
Per tutti gli esempi sottostanti, utilizzeremo 5 processi batch (non interattivi) con queste caratteristiche:
Processo Tempo di arrivo Tempo di esecuzione A 0 3 B 2 6 C 4 4 D 6 5 E 8 2
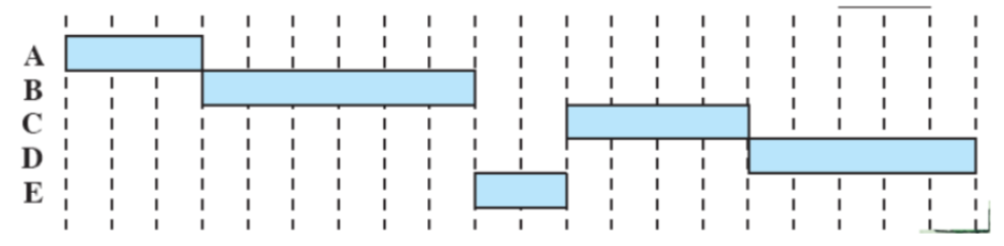
FCFS (First Come First Served)
Tutti i processi vengono aggiunti alla coda dei processi ready e quando un processo smette di essere eseguito si passa a quello che ha aspettato di più in coda. È non-preemptive quindi si passa ad un altro solo se termina o per interrupt.
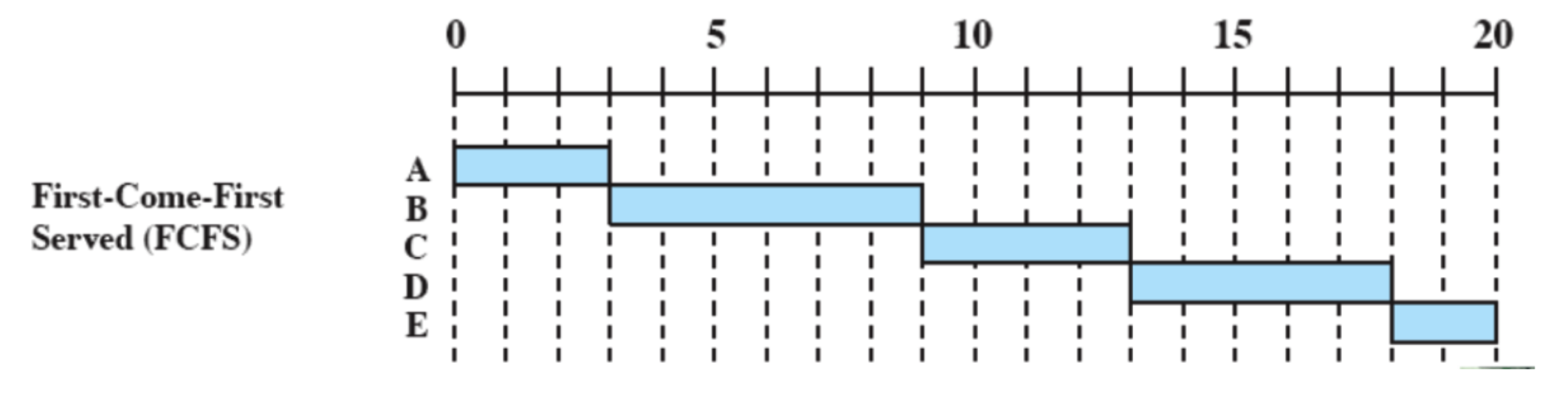
Problemi
- Un processo con poco tempo di esecuzione potrebbe dover attendere molto tempo prima di andare in esecuzione, in questo esempio
E.- Favorisce i processi CPU-Bound infatti dopo che uno di questi prende la CPU non la libera finché non viene interrotto o termina.
Round Robin
Usa la preemption basandosi su un clock, spesso viene anche chiamato time slicing perché ogni processo ha una “fetta” di tempo prestabilita.
Funzionamento
Un’interruzione di clock viene generata ad intervalli periodici. Quando l’interruzione di clock arriva, il processo attualmente in esecuzione viene rimesso nella coda dei ready. Ovviamente, se il processo in esecuzione viene bloccato da un altra interruzione viene comunque spostato nella coda dei blocked. Il prossimo processo ready nella coda viene selezionato.
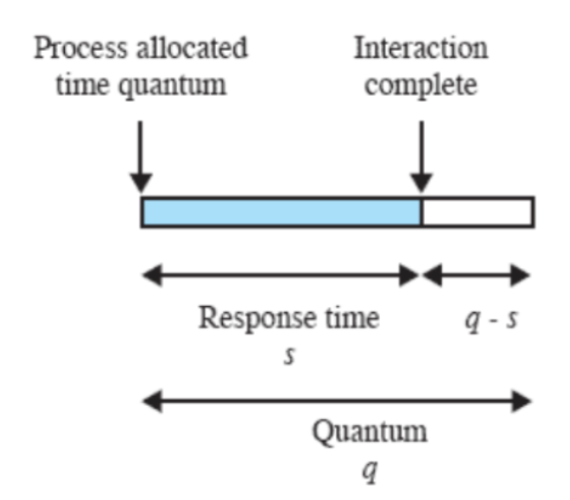
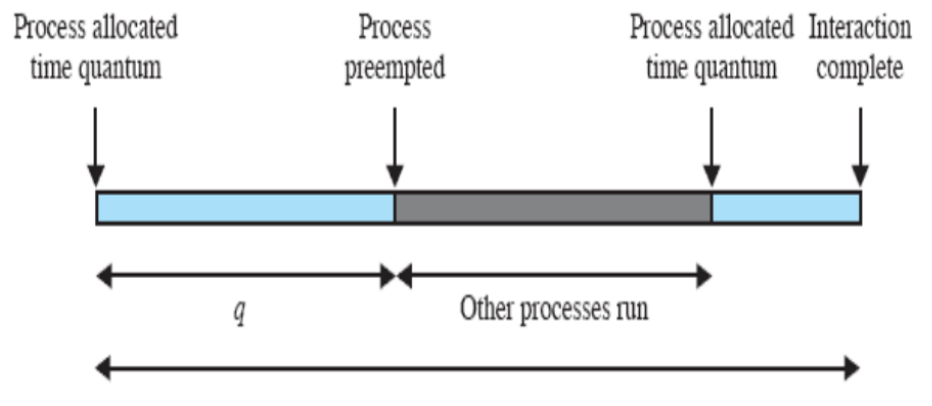
Quanto di Tempo
Il quanto di tempo non è altro che l’intervallo di tempo tra i clock degli interrupt, ovvero il tempe per cui è eseguito un determinato processo prima che venga rimpiazzato.
La durata di un quanto deve essere poco più lunga del “tipico” tempo di interazione per un processo. Ma se lo si fa troppo lungo, potrebbe durare più del tipico processo e il round robin degenera in FCFS
Column
Quanto Ottimale
Se maggiore del tipico tempo di interazione
Quanto NON Ottimale
Se minore del tipico tempo di interazione
Esempio
Inizialmente nel sistema è presente il processo
Aquindi, dopo una clock, interviene lo scheduler ma sceglie di nuovoA. Successivamente, quando altri processi sono ready, notiamo cheA“va e viene” alternando in modo equo i processi.Notiamo che il problema presente in FCFS con il processo
Equi non si presenta, infatti viene eseguito non molto lontano dalla sua richiesta.

Problemi
Con il round-robin, i processi CPU-bound sono favoriti usano tutto il loro quanto di tempo. Invece, gli I/O bound ne usano solo una porzione fino alla richiesta di I/O.
Questo rende il Round Robin:
- non equo
- unpredictable, ovvero aumenta la variabilità della risposta
- inefficiente per i processi I/O bound
Soluzione: Round Robin Virtuale
Round Robin Virtuale
Quando un processo completa l’operazione di I/O, invece d’andare nella normale coda dei Ready, va in una nuova coda che ha priorità su quella dei ready.
Quando verrà eseguito il quanto di tempo sarà uguale alla porzione del quanto che ancora gli rimaneva da completare prima dell’interruzione I/O
SPN (Short Process Next)
SPN sta per “Short Process Next” ovvero il prossimo processo da eseguire è il più breve, per più “breve” si intende quello il cui tempo di esecuzione stimato è minore tra quelli ready.
Caratteristiche
- Processi più brevi hanno la priora
- Algoritmo Non-Preemptive
Problemi
- La predicibilità dei processi lunghi è ridotta ovvero, è più difficile dire quando andranno in esecuzione.
- Se il tempo di esecuzione stimato si rivela inesatto, il sistema operativo può abortire il processo.
- I processi lunghi potrebbero soffrire di starvation.
Stima del tempo di esecuzione
In sistemi dove alcuni processi sono eseguiti più volte è possibile stimare il tempo di esecuzione guardando alle precedenti esecuzioni, ed esistono due tecniche
oss: Si indica il tempo passato con e futuro con si indica la stima, e l’indice indica il numero di volte che è stato eseguito il processo
Questa formula non fa altro che prendere tutti i tempi di esecuzione precedenti e ne calcola la media. È
Importante notare che se si utilizza la seconda formula non serve salvare tutti i tempi di esecuzione ma semplicemente l’ultimo tempo tempo () e l’ultima stima ().
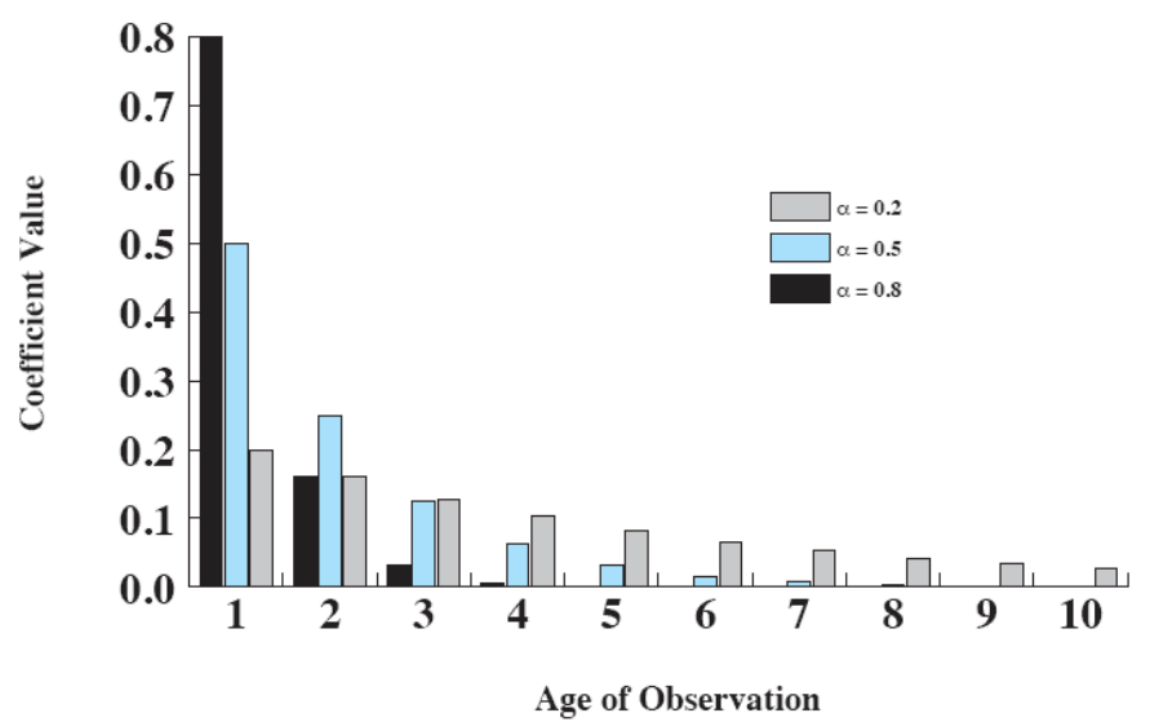
Esiste anche una formula più avanzata che da maggiore importanza ai tempi di esecuzione delle esecuzioni più recenti (Exponential averaging)
oss: è un valore compreso tra e dove mettendo valori alti permette di dare più importanza alle esecuzioni più recenti.
Column
Esempio con diversi calori di alpha
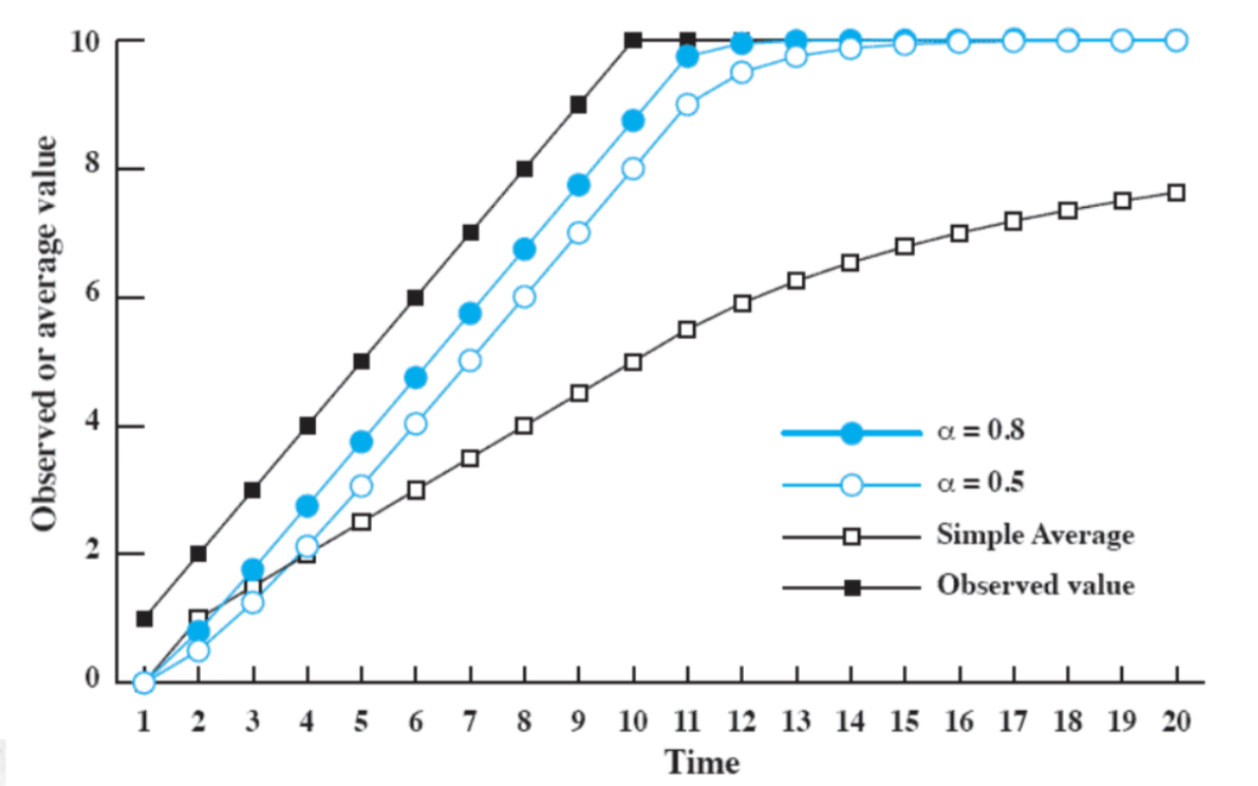
Esempio tra media normale ed esponenziale
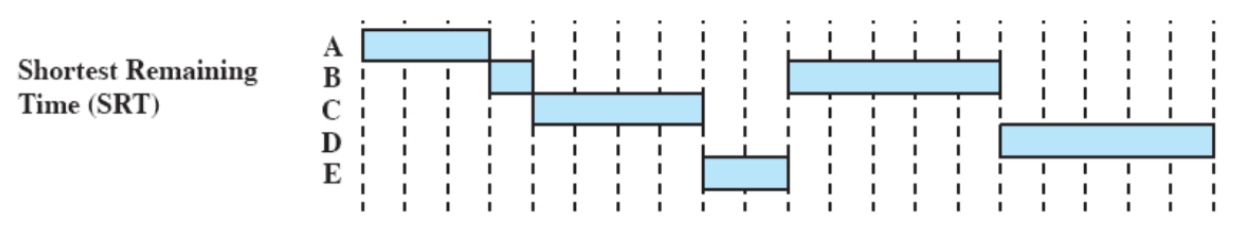
SRT (Shortest Remaining Time)
Come SPN esegue il processo più corto presente nel sistema, ma è preemptive, quindi non ha una time quantum ma si basa sul fatto che esegue un controllo per scegliere il processo più corto ad ogni arrivo di un nuovo processo appena creato, o alla fine del processo in esecuzione.
HRRN (Highest Response Ratio Next)
Anche questo algoritmo necessita di conoscere il tempo di risposta di un processo, in questo caso non può avvenire starvation e non è preemptive.
Questo algoritmo esegue il processo che ha come valore più alto:
Quindi non prende in considerazione soltanto il tempo di esecuzione del processo ma anche da quanto tempo sta aspettato.
