Introduzione
Un processo in esecuzione rimane blocked finché l’operazione di I/O non e terminata.
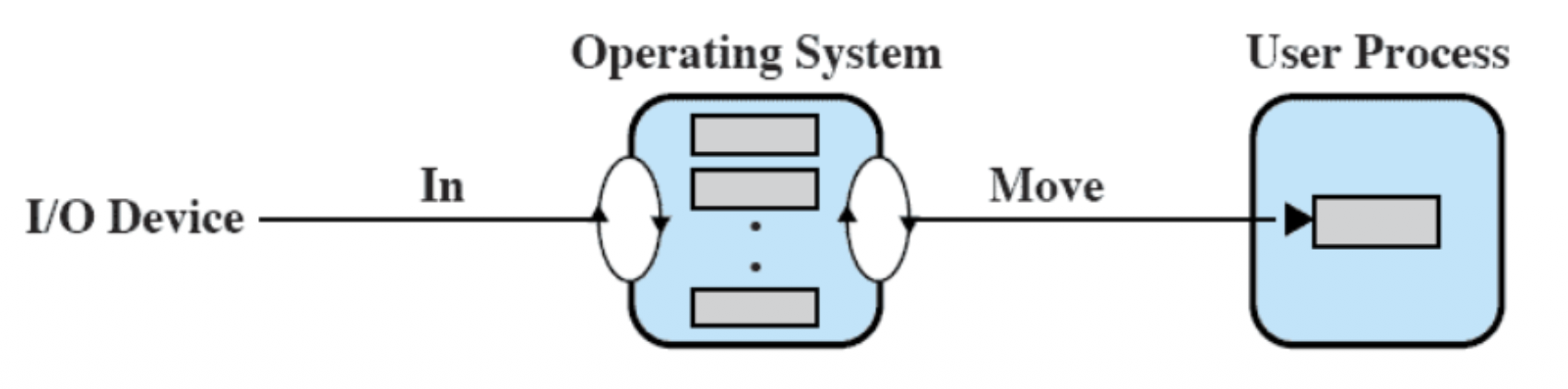
Per questo si utilizza il buffering, ovvero il processo non scrive/legge direttamente dal dispositivo I/O ma da un buffer in memoria.
Questo è più efficiente perché i dispositivi di I/O hanno velocità diverse ma in generale sono sempre più letti della memoria principale.
Trasferimenti di Input in anticipo
Ovvero prima di bloccare il processo si trasferiscono prima i dati dal dispositivo I/O alla memoria e poi il processo legge la memoria.
Trasferimenti in Output in ritardo
Ovvero il processo trasferisce prima i dati sulla memoria principale e poi i ldipositivo di I/O leggera la memoria.
Senza Buffer
Buffer Singolo
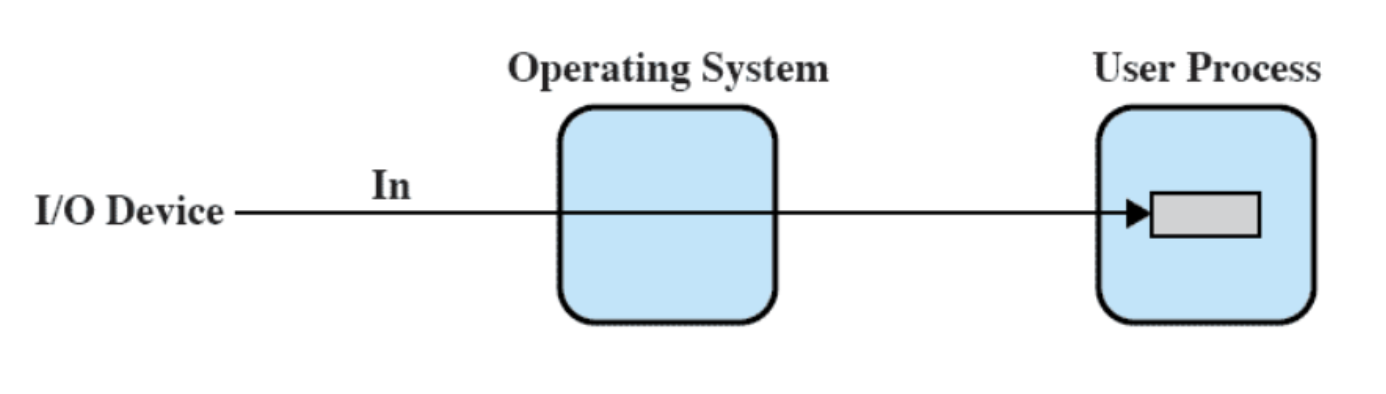
Il SO crea un buffer in memoria principale (kernel space) per una data richiesta di I/O.
Lettura e scrittura nel buffer sono separate e sequenziali.
Orientato ai Blocchi
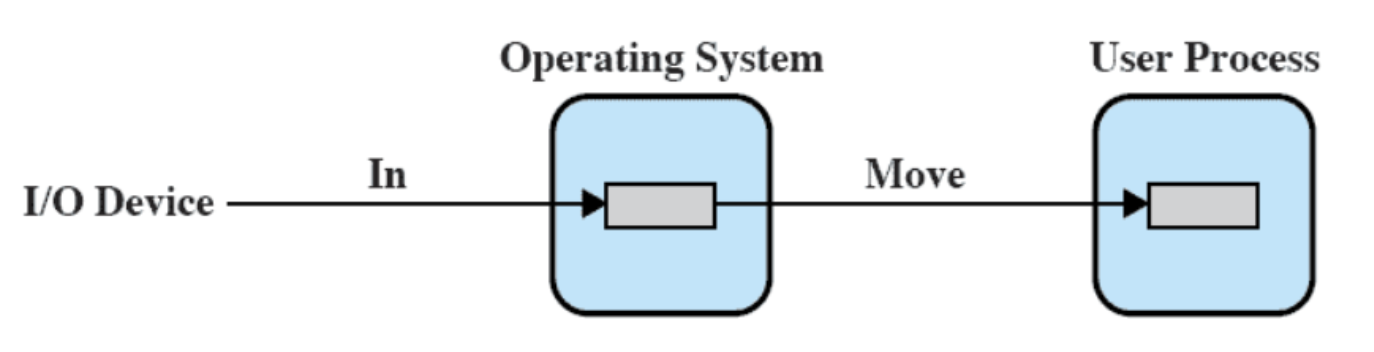
I trasferimenti di input vengono effettuati al buffer nella memoria del sistema e non in quella utente, il blocco viene mandato in quella utente soltanto quando necessario.
Questo comporta un input anticipato e di solito quando viene letto un blocco dal buffer viene letto anche il successivo, dato che solitamente sono letti sequenzialmente (principio di località) quindi c’è una buna probabilità che servirà anche il blocco successivo.
L’output, invece, viene posticipato per questo serve la system call
flush.
Orientato agli Stream
Il “buffer singolo orientato agli stream” è una tecnica utilizzata per gestire i dati che fluiscono in un sistema, sia in input che in output. Questo approccio è particolarmente utile quando si lavora con terminali e dispositivi in cui la comunicazione avviene tramite sequenze di caratteri.
Funzionalità:
- Linee di Input/Output: I terminali gestiscono solitamente linee complete di testo. Questo significa che i dati vengono archiviati in memoria fino a quando una linea viene completata e inviata.
- Byte alla Volta: In casi in cui è necessario elaborare singoli caratteri, come ad esempio nei controllori o nei sensori, il buffer può anche gestire un byte alla volta. Questo permette una maggior flessibilità nel trattamento dei dati, soprattutto quando si utilizzano hardware che richiede risposte immediate.
Problema di Concorrenza (produttore/consumatore):
Il buffering può essere visto attraverso il prisma del problema di concorrenza classico noto come “produttore/consumatore”. Ecco come si struttura:
- Produttore: Questo è il componente che produce dati. Ad esempio, un sensore che rileva temperature o un dispositivo che entra in un input.
- Consumatore: Questo è il componente responsabile della lettura dei dati. Può essere un programma che visualizza i dati sullo schermo o un algoritmo che elabora i valori in tempo reale.
Il buffer funge da intermediario tra produttore e consumatore, garantendo che:
- I dati prodotti non vengano persi nel caso in cui il consumatore non sia pronto a riceverli.
- Gli accessi concorrenti al buffer vengano gestiti in modo efficace per evitare conflitti o perdite di dati.
Buffer Doppio
Il buffer doppio utilizza due buffer per migliorare l’efficienza del trasferimento dei dati. Mentre un processo sta trasferendo dati da o a uno dei buffer, il sistema operativo può riempiere o svuotare l’altro buffer. Questo approccio consente la lettura e scrittura parallele, permettendo così una gestione più fluida dei dati. Quando un buffer è attivamente in uso, l’altro è pronto a ricevere o inviare nuovi dati.
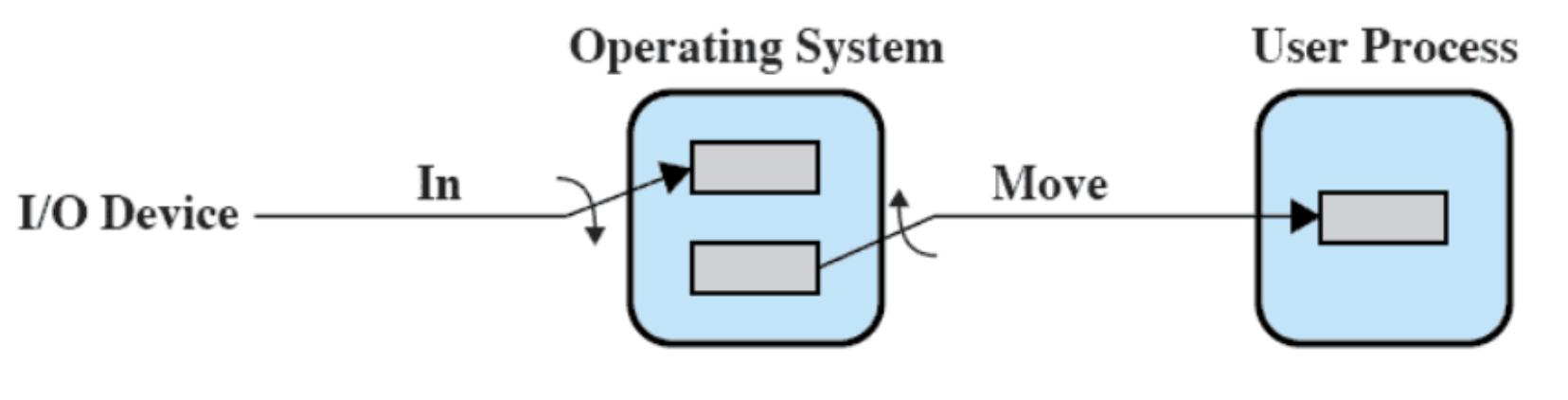
Buffer Circolare
Il buffer circolare è composto da più di due buffer collegati in una struttura circolare. Ogni buffer funge da unità all’interno di questo sistema. Questo tipo di buffering è particolarmente utile quando le operazioni di input/output devono tenere il passo dei processi in tempo reale. Ancora una volta, il modello si rifà al concetto di produttore/consumatore, dove il produttore inserisce dati e il consumatore li legge in modo da massimizzare l’efficienza del flusso di dati.
Buffer: Pro e Contro
Pro:
- Il buffer riesce a mantenere il processore non in idle anche con tanto richieste I/O.
Difficoltà (ne problemi ne contro solo cose da tenere in considerazione):
- Ma se c’è molta domanda i buffer si riempiono e il vantaggio si perde
- Risultati si vedono soprattutto quando ci sono molti e vari dispositivi di I/O da servire
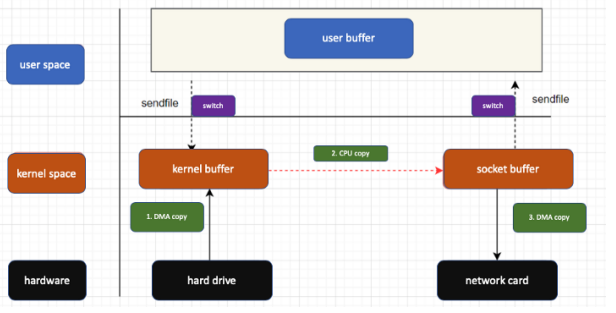
Problemi: overhead a causa della copia intermedia in kernel memory:
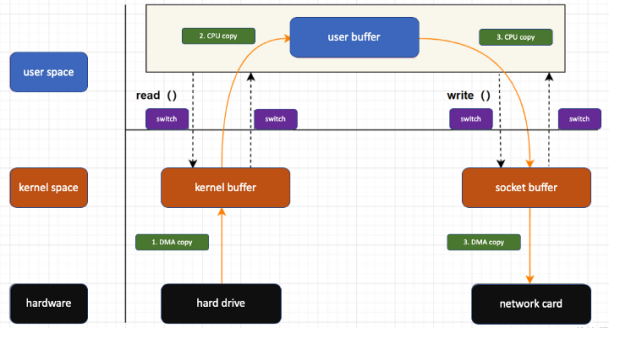
Zero Copy (soluzione)
In questo modo evita copie inutili intermedia facendo trasferimenti da un kernel buffer ad un altro.