MPI requires that messages be nonovertaking. This means that if process q sends two messages to processr, then the first message sent by q must be available tor before the second message.
However, there is no restriction on the arrival of messages sent from different processes
First Touch Policy
Modern multi-socket or multi-chiplet CPUs use a Non-Uniform Memory Access (NUMA) architecture. When you allocate memory (e.g., using malloc or new), the operating system doesn’t actually map physical RAM to it immediately. It waits until the memory is written to for the first time—a concept called the First-Touch Policy.
If you use memset: A single master thread initializes the memory. The OS maps all the physical memory pages to the NUMA node (the physical CPU) that the master thread is running on. When other threads try to access this memory later, they suffer high latency because they have to cross the inter-core interconnect to fetch data from the master thread’s node.
If you use OpenMP (parallel for): Multiple threads initialize their respective chunks of the array simultaneously. The OS maps each memory page to the local NUMA node of the specific thread that initializes it. Later, when those same threads process the data, the memory is physically local to them, resulting in massive bandwidth and latency improvements.
Generali
1.1 Cos'è il False Scaring? 🟢
Il false sharing è un “effetto collaterale” dei sistemi di coerenza della cache che porta ad un degradamento delle performance. Si verifica quando due o più thread, in esecuzione parallela su core diversi, modificano variabili logicamente distinte che però risiedono fisicamente all’interno della stessa linea di cache (cache line).
Per comprendere il problema, occorre ricordare che i dati non vengono trasferiti dalla memoria principale alla cache del processore come singole variabili, ma a blocchi di dimensione fissa chiamati, appunto, cache line. Ad esempio, in un’architettura con cache line da 64 Byte, un singolo blocco può contenere fino a 16 interi da 4 Byte adiacenti in memoria.
Il collo di bottiglia prestazionale sorge a causa del meccanismo di coerenza della cache hardware: quando un thread modifica la propria variabile, l’intero blocco di cache viene contrassegnato come “invalido” per tutti gli altri core. Di conseguenza, gli altri thread saranno costretti a ricaricare l’intera linea dalla memoria principale (o da una cache condivisa di livello superiore), anche se stavano lavorando su variabili completamente diverse e non modificate.
Come risolvere il False Sharing?
Per mitigare o eliminare questo problema si utilizzano principalmente tre strategie:
Data Padding (Riempimento): Consiste nell’inserire dello spazio vuoto (byte di padding) tra le variabili utilizzate dai diversi thread. In questo modo si “allontanano” i dati in memoria, costringendoli a risiedere su cache line separate.
Allineamento della memoria (Alignment): Sfruttare direttive del compilatore (come alignas in C++ o @Contended in Java) per allineare l’indirizzo di inizio di una struttura dati esattamente al confine di una cache line.
Localizzazione dei dati (Thread-local storage): Progettare l’algoritmo in modo che ogni thread lavori principalmente su zone di memoria separate o su copie locali dei dati (es. registri o stack privato), accumulando i risultati in una struttura globale solo al termine dell’elaborazione.
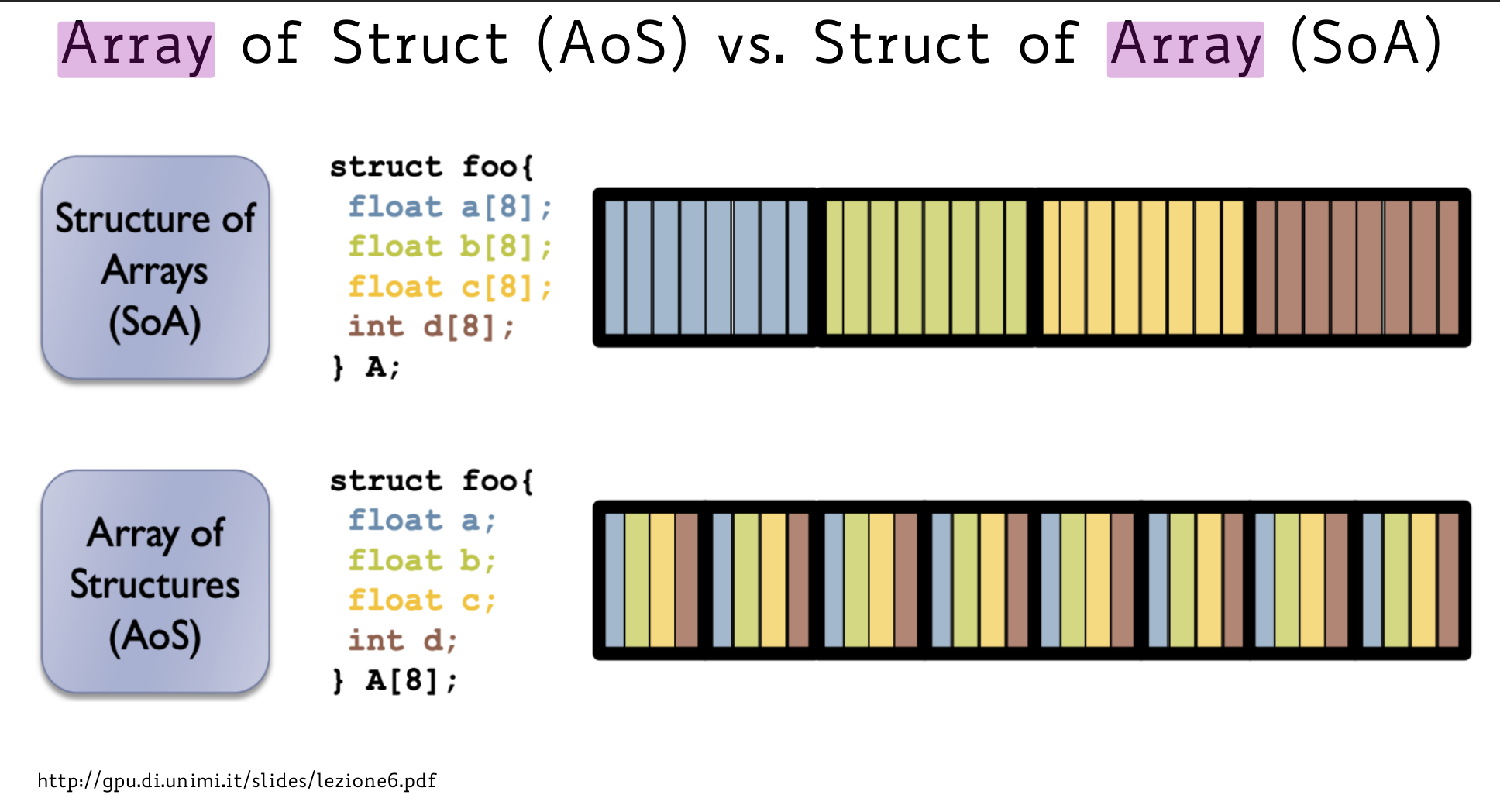
1.2 Differenze tra Array of Structs (AOS) e Struct of Arrays (SOA) 🟢
Ovviamente la principale differenza è come vengono rappresentate in memoria:
Nell’AoS (Array of Struct), dichiariamo un array in cui ogni elemento è una struttura (es. con campi x e y). In memoria, i dati di ogni singola struttura sono alternati e contigui: x y | x y | x y.
Nel SoA (Struct of Array), abbiamo un’unica struttura contenente array separati per ogni campo. In memoria, tutti i valori dello stesso tipo sono raggruppati insieme: x x x x | y y y y.”
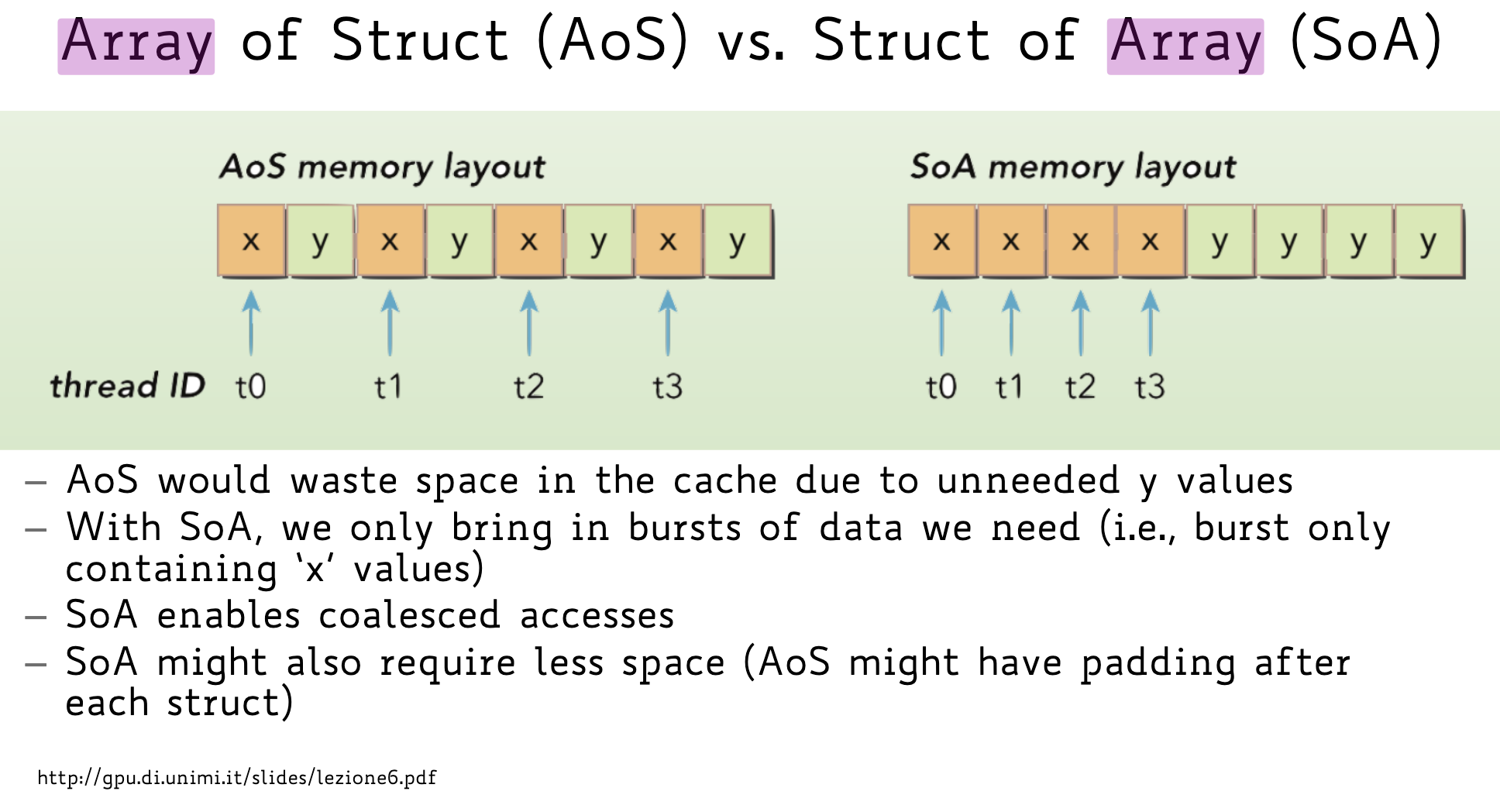
Questi layout hanno differenze quando si vuole ottimizzare la cache locality:
Se usiamo l’AoS, quando il thread porta in cache il dato x, la cache line si riempirà anche dei valori y adiacenti.
Con il SoA, invece, poiché tutte le x sono vicine, il caricamento in cache porta solo i valori x adiacenti .
Quindi se un calcolo utilizza solo dei valori x (e non gli y) allora conviene utilizzare SoA.
Nella programmazione su GPU: il vantaggio principale del SoA è che abilita i cosiddetti coalesced accesses (accessi coalescenti). Poiché i thread paralleli accedono a indirizzi di memoria strettamente contigui (il thread 0 accede a x0, il thread 1 a x1, ecc., che sono uno di fianco all’altro), l’hardware può “combinare” queste richieste in un’unica singola transazione di memoria, massimizzando la banda passante.
Infine, c’è un vantaggio anche in termini di occupazione di memoria grezza. Le strutture in C spesso richiedono l’inserimento di byte vuoti (padding) per mantenere l’allineamento in memoria. Nell’AoS, questo padding potrebbe essere necessario dopo ogni singola struttura dell’array, sprecando molta memoria. Nel SoA, avendo array omogenei di tipi base (come array di soli float), il problema dell’allineamento interno è quasi inesistente, richiedendo complessivamente meno spazio.
In realtà i SOA sono anche meglio per la vettorizazione, in quanto per effettuare operazioni simd i valori devono essere contingui in memoria.
Slides
1.3 Tra AOS e SOA, chi occupa più memoria? 🟢
Un ulteriore vantaggio del SoA è la riduzione dello spreco di memoria dovuto al padding. Nell’AoS, se abbiamo strutture con tipi di dato di dimensioni diverse, il compilatore inserisce byte vuoti di allineamento che vengono ripetuti per ogni elemento dell’array. Nel SoA, raggruppando dati omogenei in array separati, il problema dell’allineamento interno viene eliminato, compattando enormemente i dati in memoria.
Perché la memoria deve essere allineata? (Memory Alignment)
Il motivo è puramente hardware: l’efficienza del bus di memoria.
Lettura a Blocchi: La CPU non comunica con la RAM leggendo un singolo byte alla volta, ma preleva “pacchetti” di dati chiamati Word (tipicamente di 4 o 8 byte, a seconda dell’architettura a 32 o 64 bit).
Accesso Diretto (Single Cycle): Se un dato è memorizzato a un indirizzo che è multiplo della sua dimensione, esso cade perfettamente entro i confini di una “Word”. La CPU può caricarlo nei registri con un’unica operazione di lettura.
Il problema del dato “disallineato”: Se un dato (es. di 4 byte) inizia a un indirizzo non multiplo, esso “sconfina” tra due diverse Word. Per recuperarlo, la CPU deve:
Effettuare due letture separate della memoria.
Eseguire operazioni logiche extra (shift e mask) per unire i pezzi e ripulire i bit in eccesso.
1.4 Data una percentuale di codice sequenziale, qual'è lo speed up massimo ottenibile? 🟢
Secondo la Legge di Amdahl, lo speed-up S(p) di un programma è strettamente limitato dalla sua frazione sequenziale. Se indichiamo con α la percentuale di codice parallelizzabile e con 1−α la percentuale di codice sequenziale, lo speed-up massimo teorico si ottiene calcolando:
1−α1
Per esempio, se abbiamo un’applicazione in cui il 60% del codice è parallelizzabile, significa che α=0.6. La frazione sequenziale sarà 1−0.6=0.4. Lo speed-up massimo che potremo mai ottenere sarà 0.41=2.5.
Come si ottiene questa formula:
Sia Ts il tempo di esecuzione sequenziale, Sia Tp(p) il tempo di esecuzione del programma parallelizzato con p processori.
Tp(p)=(1−α)Ts+αpTs
Dove α∈[0,1] rappresenta la frazione parallelizzabile, e 1−α la frazione seriale.
Lo speed up sarà quindi:
S(p)=Tp(p)Ts=(1−α)Ts+αpTsTs
Il valore dello speed up è limitato superiormente, infatti all’aumentare dei processi:
Sono due leggi che permettono di studiare a livello teorico lo scaling ideale di un programma parallelizzato.
La legge di Amdahl studia lo strong scaling, in cui abbiamo un problema di dimensione fissa n, con Ts definiamo tempo del esecuzione sequenziale, e con Tp(p) il tempo di esecuzione parallela con p processori.
Che lo speedup massimo è descritto dalla seguente formula: S(p)=limp→∞Tp(p)Ts=1−α1
Dove α è la sezione del problema che è paralellizabile, e 1−α è la sezione di programma non parallelizzabile.
Questo risultato è ottenuto partendo da la formula completa del calcolo dello speedup:
S(p)=Tp(p)Ts=Ts(1−α)+αpTsTs
E poi semplificandola, tenendo conto che vogliamo calcolare lo speed up massimo, ovvero con infiniti processori:
La Gustafson law invece tiene conto dello week scaling, ovvero che all’aumentare del numero di processori, aumenta in modo proporzionale anche la dimensione del programma.
S(p)=(1−α)+α(1−α)+αp=1(1−α)+αp=(1−α)+αp
Limitazioni dell’Amdahl Law e Gustafson Law: danno per scontato che la dimensione della parte seriale rimanga costante all’aumentare del numero di processori, ma questo nel mondo reale raramente è vero.
1.6 Cos'è il Roofline Model? 🟠
Il Roofline Model è un modello grafico e intuitivo utilizzato per stimare le prestazioni massime raggiungibili da un’applicazione su una specifica architettura hardware (come una GPU), basandosi sui limiti fisici del dispositivo.
Il modello mette in relazione la potenza di calcolo con la larghezza di banda della memoria, permettendo di capire se un kernel è limitato dalla velocità del processore o dalla velocità di trasferimento dei dati.
Struttura del Modello
Il grafico del Roofline Model si compone di due assi principali:
Asse X (Intensità Aritmetica): Rappresenta l’intensità operativa, misurata in FLOP/byte. Indica quante operazioni in virgola mobile vengono eseguite per ogni byte di dato trasferito dalla memoria globale.
Asse Y (Prestazioni): Indica le prestazioni raggiungibili misurate in FLOP/s (ovvero quante operazioni in virgola mobile si possono eseguire al secondo).
La forma tipica del grafico ricorda il profilo di un tetto (da cui il nome “roofline”) ed è definita da due bound (limiti) invalicabili:
Limite della Banda (Riga Obliqua): Rappresenta il collo di bottiglia dovuto alla larghezza di banda della memoria globale. In questa zona, l’applicazione è definita bandwidth-bound (o memory-bound): le prestazioni crescono linearmente con l’aumentare dell’intensità aritmetica perché il processore passa molto tempo in attesa dei dati.
Limite del Picco di Calcolo (Riga Orizzontale): Rappresenta la massima potenza computazionale della GPU. Quando l’intensità aritmetica è sufficientemente alta, le prestazioni smettono di crescere e si stabilizzano al livello del picco hardware. In questa zona l’applicazione è definita compute-bound.
Punto di Incontro e Ottimizzazione
Il punto in cui la riga obliqua incontra quella orizzontale definisce l’intensità aritmetica minima necessaria per saturare completamente l’hardware.
Esempio pratico: Se una GPU ha una banda di 200 GB/s e un picco di 1.500 GFLOP/s, per saturare l’hardware è necessaria un’intensità di 30 FLOP/byte (ovvero eseguire 30 operazioni per ogni operando caricato). Se un kernel esegue solo una o due operazioni per operando, le sue prestazioni saranno confinate nella parte bassa della riga obliqua, sfruttando solo una minima frazione (es. 3.3%) della potenza della GPU.
In sintesi, il Roofline Model serve al programmatore per identificare la natura del collo di bottiglia: se l’applicazione è sotto la “linea della banda”, l’ottimizzazione deve puntare a ridurre gli accessi in memoria (es. tramite il tiling); se è sotto la “linea del picco”, bisogna ottimizzare l’efficienza del calcolo.
1.9 Com'è gestito un read-write lock? 🟢
Un read-write lock (RW lock) è un meccanismo di sincronizzazione, simile a una mutex, progettato per gestire l’accesso a strutture dati condivise in modo più efficiente quando le operazioni di sola lettura sono molto frequenti rispetto a quelle di modifica.
Ecco come viene gestito e quali sono le sue regole di funzionamento:
Logica di Accesso
La caratteristica principale di un read-write lock è la distinzione tra l’accesso in lettura e quello in scrittura:
Lettura multipla: Più thread possono ottenere contemporaneamente il lock in lettura e accedere alla risorsa, a patto che nessun thread detenga o abbia richiesto il lock in scrittura.
Scrittura esclusiva: Solo un thread alla volta può ottenere il lock in scrittura. Mentre un thread scrive, nessun altro thread può accedere alla risorsa, né in lettura né in scrittura.
Interazioni tra i Lock
La gestione delle attese segue regole precise basate sullo stato attuale della risorsa:
Se la risorsa è libera: Un thread può ottenere immediatamente sia un lock in lettura che uno in scrittura.
Se c’è un lock in lettura attivo:
Altri thread che richiedono un lock in lettura lo ottengono immediatamente.
Thread che richiedono un lock in scrittura devono attendere che tutti i lettori correnti rilascino la risorsa.
Se c’è un lock in scrittura attivo:
Qualsiasi altra richiesta (sia di lettura che di scrittura) viene messa in attesa fino al rilascio del lock.
2.0 Cosa sono le loop carried dependencies? Come si possono mitigare? 🔴
MPI
Cos'è MPI_Status? 🟢
MPI_Status è una struttura utilizzata in MPI per descrivere l’esito e i dettagli di un’operazione di ricezione di messaggi.
Funzioni e Scopo: Questa struttura viene restituita o aggiornata da funzioni di ricezione o di controllo del completamento, come MPI_Recv, MPI_Wait, MPI_Waitall o MPI_Test. Il suo scopo principale è fornire al ricevente informazioni sul messaggio appena ottenuto, specialmente quando queste non erano note a priori.
Attributi principali: La struttura contiene tre campi fondamentali accessibili dal programmatore:
MPI_SOURCE: indica il rank del mittente. È essenziale quando si utilizza la costante MPI_ANY_SOURCE per ricevere un messaggio da un mittente qualsiasi, permettendo poi di identificare chi lo ha effettivamente inviato.
MPI_TAG: indica il tag del messaggio. È utile quando si utilizza MPI_ANY_TAG per accettare messaggi con qualsiasi etichetta, permettendo di scoprire quale tag sia stato usato dal mittente.
MPI_ERROR: indica se l’operazione di comunicazione ha avuto successo o se si sono verificati errori.
Determinare la quantità di dati: Sebbene la struttura MPI_Status non contenga direttamente un campo con il numero di elementi ricevuti, essa deve essere passata alla funzione MPI_Get_count per estrarre tale informazione. Questo è fondamentale quando il ricevente non conosce in anticipo l’esatta dimensione del messaggio in arrivo.
Ignorare lo Status: Se il programmatore conosce già tutte le informazioni (mittente, tag e dimensione) e non ha bisogno di controllare eventuali errori tramite lo status, può utilizzare la costante MPI_STATUS_IGNORE (o MPI_STATUSES_IGNORE per operazioni multiple come Waitall) per evitare di allocare e gestire la struttura, riducendo l’overhead.
2.1 In quali casi abbiamo bisogno di ottenere il tag o rank (source) usando MPI_Status? 🟢
Identificazione del mittente (MPI_SOURCE): Quando una funzione di ricezione (come MPI_Recv) viene chiamata utilizzando la costante MPI_ANY_SOURCE, il processo ricevente accetta un messaggio da un mittente qualsiasi all’interno del comunicatore. In questo scenario, l’unico modo per scoprire l’identità (il rank) del processo che ha effettivamente inviato il messaggio è accedere al campo MPI_SOURCE della struttura MPI_Status dopo che la ricezione è stata completata.
Identificazione del tipo di messaggio (MPI_TAG): Analogamente, se si utilizza la costante MPI_ANY_TAG, il ricevente accetta messaggi con qualunque etichetta. Poiché il tag viene spesso usato come separatore logico per distinguere diverse tipologie di messaggi o fasi della computazione, il ricevente deve consultare il campo MPI_TAG nello status per capire come interpretare o processare il dato appena arrivato.
2.2 Cosa sono gli MPI_Errors 🟢
I codici di errore specifici possono essere tantissimi, ma sono tutti raggruppati in macro categorie standard chiamate classi di errore. Puoi estrarre la classe da un codice di errore usando MPI_Error_class.
Ecco le classi più comuni che potresti incontrare:
MPI_ERR_RANKIl rank del processo mittente o destinatario non è valido.
MPI_ERR_TAGIl tag utilizzato è negativo o supera il limite massimo consentito.
MPI_ERR_COUNTIl valore del contatore degli elementi (count) non è valido (es. negativo).
MPI_ERR_TYPEL’argomento relativo al tipo di dato (MPI_Datatype) non è valido.
MPI_ERR_BUFFERIl puntatore al buffer di memoria non è valido o la memoria è insufficiente.
MPI_ERR_COMMIl comunicatore passato alla funzione non è valido.
2.3 Come possiamo ottenere il numero di elementi ricevuti in una comunicazione? Perché è possibile ricevere un numero di elementi minore alla buf_size? 🟢
Per ottenere il numero di elementi effettivamente ricevuti in una comunicazione MPI, è necessario utilizzare la funzione MPI_Get_count. Questa funzione non estrae il dato direttamente dalla struttura MPI_Status, ma richiede lo status come argomento per calcolare il numero di elementi di un determinato tipo che sono stati ricevuti.
Come ottenere il numero di elementi
Quando si effettua una ricezione (ad esempio con MPI_Recv), MPI aggiorna una struttura di tipo MPI_Status. Per conoscere la quantità di dati arrivati, si chiama:
int MPI_Get_count(MPI_Status* status_p, MPI_Datatype type, int* count_p);
status_p: è il puntatore allo status riempito dalla funzione di ricezione.
type: è il tipo di dato MPI degli elementi nel messaggio.
count_p: è la variabile in cui verrà salvato il numero di elementi effettivamente ricevuti.
Perché si possono ricevere meno elementi di buf_size?
È possibile e comune ricevere un numero di elementi inferiore a buf_size per i seguenti motivi:
Capacità vs. Contenuto: Il parametro buf_size in una MPI_Recv (o count in una MPI_Irecv) indica la capacità massima del buffer di ricezione, non l’esatta quantità di dati attesi.
Vincoli di matching: Affinché una ricezione abbia successo, il buffer di ricezione deve essere maggiore o uguale al messaggio inviato (recv_buf_sz >= send_buf_sz). Se il mittente invia un messaggio più piccolo della capacità massima dichiarata dal ricevente, MPI depositerà semplicemente i dati all’inizio del buffer e il ricevente dovrà usare MPI_Get_count per sapere quanti ne sono arrivati effettivamente.
Ricezione flessibile: Questo meccanismo permette al ricevente di accettare messaggi di cui non conosce a priori l’esatta dimensione, purché abbia allocato spazio a sufficienza per il caso peggiore.
2.4 Quali sono i differenti livelli di threading in MPI? (funneled, serialized, ...) Quali sono le differenze? 🟢
Lo standard MPI definisce quattro livelli di supporto al threading (thread safety) che determinano come i thread di un processo possono interagire con la libreria MPI. Per attivare questi livelli, è necessario inizializzare l’ambiente tramite la funzione MPI_Init_thread invece della classica MPI_Init.
Ecco i quattro livelli e le relative differenze:
MPI_THREAD_SINGLE: Il processo è composto da un solo thread di esecuzione. Non è permesso l’uso di multithreading all’interno del rank; questo livello è funzionalmente equivalente alla chiamata di MPI_Init standard.
MPI_THREAD_FUNNELED: Il processo può essere multi-thread, ma vige la restrizione per cui solo il thread principale (quello che ha effettuato la chiamata a MPI_Init_thread) può effettuare chiamate a funzioni MPI. È il modello ideale per programmi ibridi che usano OpenMP, dove le comunicazioni MPI avvengono solitamente all’esterno delle regioni parallele.
MPI_THREAD_SERIALIZED: Il processo può avere più thread che interagiscono con MPI, ma è permesso l’accesso a un solo thread alla volta. Spetta al programmatore garantire che le chiamate MPI siano serializzate (ad esempio proteggendole con una mutex) per evitare conflitti.
MPI_THREAD_MULTIPLE: È il livello di massima flessibilità, in cui qualsiasi thread può effettuare chiamate MPI in qualsiasi momento, anche simultaneamente. La libreria MPI si occupa internamente di garantire che l’accesso sia sicuro (thread-safe), sebbene questa gestione possa rendere le operazioni meno efficienti rispetto ai livelli precedenti.
2.5 Cosa sono i derived datatypes in MPI? 🟢
In MPI, i derived datatypes (tipi di dato derivati) sono tipologie di dati personalizzate utilizzate per rappresentare collezioni di elementi in memoria, memorizzando sia il tipo dei singoli elementi sia la loro posizione relativa (displacement).
Ecco i dettagli fondamentali sul loro funzionamento e scopo:
Scopo e Vantaggi
Rappresentazione di strutture complesse: Permettono di descrivere collezioni di dati non contigui o di tipi differenti, simulando le struct del linguaggio C.
Efficienza: Consentono di inviare un’intera collezione di dati con una singola chiamata (es. MPI_Send), riducendo drasticamente l’overhead rispetto all’effettuare molteplici invii separati per ogni singolo campo.
Portabilità: Gestiscono in modo trasparente le differenze di padding (byte di riempimento) tra diverse architetture (es. sistemi a 32-bit vs 64-bit), garantendo che i dati vengano ricostruiti correttamente sul destinatario.
Creazione e Ciclo di Vita
La creazione di un tipo derivato (tipicamente tramite la funzione generale MPI_Type_create_struct) richiede la specifica di:
Count: Il numero di blocchi di elementi.
Block lengths: Un array che specifica quanti elementi di tipo base ci sono in ogni blocco.
Displacements: Le posizioni relative (offset) in byte di ogni blocco. È fondamentale usare MPI_Get_address per calcolare questi indirizzi in modo portabile, garantendo il corretto funzionamento anche su macchine con spazi di indirizzamento segmentati.
Types: Un array contenente i tipi MPI di base coinvolti.
Per rendere il tipo utilizzabile e gestire le risorse, è necessario seguire questi passaggi:
Commit: Si chiama MPI_Type_commit per permettere all’implementazione MPI di ottimizzare la rappresentazione interna del nuovo tipo per le comunicazioni.
Utilizzo: Il tipo può essere usato nelle normali funzioni di comunicazione (point-to-point o collettive).
Free: Quando il tipo non è più necessario, si usa MPI_Type_free per deallocare la memoria utilizzata per la sua definizione.
Altre Tipologie di Funzioni
Oltre alle strutture generiche, MPI offre circa 40 funzioni per gestire i tipi di dato, tra cui:
MPI_Type_contiguous: Per elementi identici memorizzati consecutivamente.
MPI_Type_vector: Per elementi identici ripetuti con un passo costante (stride) tra loro.
MPI_Type_create_subarray: Per estrarre sotto-porzioni di array multidimensionali.
MPI_Pack / MPI_Unpack: Per impacchettare manualmente dati sparsi in un buffer contiguo.
2.6 Parla dei differenti tipi di MPI_Send 🔴
Come funziona una non bloccante, cosa succede quando di fa una isend?
Quando una send / recv bloccate si comporta in modo non bloccante?
2.7 Come sommeresti due matrici in MPI? 🔴
2.8 Quando è possibile avere un deadlock in MPI? 🟢
In MPI, un deadlock (o stallo) si verifica quando uno o più processi rimangono bloccati in uno stato di attesa indefinita, impedendo al programma di proseguire.
Secondo le fonti, le situazioni principali in cui è possibile riscontrare un deadlock sono:
1. Mancato matching tra invio e ricezione
Ricezione senza invio: Se un processo tenta di ricevere un messaggio (MPI_Recv) ma non esiste una corrispondente operazione di invio da parte del mittente specificato, il processo ricevente rimarrà sospeso (appeso) per sempre.
Invio bloccante senza ricezione: Se una chiamata a MPI_Send è bloccante (comportamento tipico per messaggi grandi) e non c’è una MPI_Recv corrispondente già avviata o pronta sul destinatario, il processo mittente può bloccarsi in attesa che il buffer venga liberato o il messaggio prelevato.
Invio a se stessi: Se un processo imposta il proprio rank sia come sorgente che come destinazione in operazioni bloccanti, rischia di rimanere bloccato in attesa di un’operazione che non può concludersi.
2. Attesa circolare in pattern di comunicazione
Un esempio classico è la configurazione ad anello, dove ogni processo tenta contemporaneamente di inviare un dato al vicino di destra e ricevere dal vicino di sinistra usando funzioni bloccanti. In questo scenario, se tutti i processi eseguono prima la MPI_Send e questa si comporta in modo bloccante, nessuno arriverà mai alla chiamata MPI_Recv, creando uno stallo circolare. Per mitigare questo problema, si consiglia l’uso di comunicazioni non bloccanti (MPI_Isend, MPI_Irecv) o della funzione MPI_Sendrecv, che coordina internamente le operazioni per evitare crash o blocchi.
3. Errori nelle comunicazioni collettive
Le funzioni collettive (come MPI_Reduce, MPI_Bcast o MPI_Barrier) richiedono una sincronizzazione tra tutti i processi di un comunicatore. Il deadlock si verifica se:
Chiamate incomplete: Non tutti i processi appartenenti al comunicatore chiamano la funzione collettiva; quelli che la chiamano rimarranno in attesa infinita degli altri.
Chiamate non corrispondenti: Un programma tenta di far combaciare una collettiva (es. MPI_Reduce) su un processo con una ricezione punto-a-punto (es. MPI_Recv) su un altro.
Argomenti incompatibili: I processi passano parametri incoerenti alla stessa funzione collettiva, come ad esempio rank differenti per il processo di destinazione (dest_process) in una MPI_Reduce.
2.9 Quale problema MPI_SendRecv risolve? 🟢
La funzione MPI_Sendrecv è progettata principalmente per risolvere il problema del deadlock (stallo) nelle comunicazioni punto-a-punto, semplificando al contempo la scrittura del codice.
Ecco i dettagli su come interviene e quali vantaggi offre:
1. Prevenzione del Deadlock
In molti pattern di comunicazione, come la configurazione ad anello o lo scambio di bordi (halo swap), ogni processo deve contemporaneamente inviare un dato a un vicino e riceverne uno da un altro.
Il problema: Se tutti i processi chiamano una funzione di invio bloccante (come MPI_Send) prima della ricezione, potrebbero rimanere tutti in attesa che un buffer venga liberato, senza mai arrivare alla chiamata di ricezione. Questo causa il blocco (hang) del programma.
La soluzione:MPI_Sendrecv esegue un invio e una ricezione in una singola chiamata. MPI pianifica internamente le operazioni in modo che la comunicazione avvenga in sicurezza, garantendo che il programma non vada in stallo o crashi.
2. Semplificazione del Codice
MPI_Sendrecv agisce come un’alternativa più immediata e pulita rispetto a:
Scheduling manuale: Evita al programmatore di dover decidere manualmente l’ordine degli invii e delle ricezioni (ad esempio, facendo sì che i rank pari inviino prima e i rank dispari ricevano prima).
Comunicazioni non bloccanti: Sostituisce la sequenza più complessa composta da MPI_Isend, MPI_Irecv e la successiva MPI_Wait, ottenendo un risultato simile con una sola funzione.
3. Flessibilità
Sorgente e Destinazione: Il mittente (dest) e il destinatario (source) possono essere lo stesso processo o processi diversi all’interno dello stesso comunicatore.
Buffer separati: La funzione utilizza buffer distinti per i dati inviati e quelli ricevuti, permettendo di aggiornare le informazioni (come i bordi di una matrice in un codice CFD) in modo efficiente.
In sintesi, MPI_Sendrecv è lo strumento standard per gestire scambi di dati bidirezionali sicuri, eliminando il rischio di dipendenze circolari che portano al blocco dell’applicazione.
2.10 Come funziona MPI_IN_PLACE? 🟢
La macro MPI_IN_PLACE è un valore speciale utilizzato nelle operazioni di comunicazione collettiva di MPI (come MPI_Scatter, MPI_Gather o MPI_Reduce) per indicare che un processo non deve spostare i dati tra buffer diversi, poiché questi si trovano già nella posizione finale desiderata.
Ecco i dettagli principali sul suo funzionamento basati sulle fonti:
1. Scopo e Utilizzo (Esempio MPI_Scatter)
Nelle fonti, MPI_IN_PLACE viene illustrato specificamente nel contesto della funzione MPI_Scatter applicata al processo root (il mittente).
Senza MPI_IN_PLACE: Normalmente, anche il processo root deve specificare un buffer di ricezione dove MPI copierà la porzione di dati a lui destinata prelevandola dal buffer di invio globale.
Con MPI_IN_PLACE: Se il nodo che condivide il vettore specifica questa macro come buffer di destinazione (recv_buf), MPI capisce che quel processo manterrà i valori direttamente nel vettore originale. In altre parole, la sua porzione di dati non viene copiata altrove, ma rimane “sul posto” nel buffer di invio.
2. Vantaggi
L’uso di questa macro offre due benefici fondamentali:
Efficienza di memoria: Evita di dover allocare un buffer di ricezione separato sul processo root, risparmiando spazio.
Prestazioni: Riduce l’overhead computazionale eliminando un’operazione di copia locale (memoria-a-memoria) che sarebbe altrimenti necessaria per soddisfare i parametri della funzione.
3. Sintassi nel codice
Dalle fonti emerge che la macro viene passata come argomento al posto del puntatore al buffer. Ad esempio, per un rank 0 che effettua uno scatter:
if (rank == 0) { // Il root usa MPI_IN_PLACE come buffer di ricezione MPI_Scatter(buff, 3, MPI_INT, MPI_IN_PLACE, 3, MPI_INT, 0, MPI_COMM_WORLD);} else { // Gli altri processi usano un buffer di ricezione normale MPI_Scatter(buff, 3, MPI_INT, dest, 3, MPI_INT, 0, MPI_COMM_WORLD);}
2.11 Come funziona la comunicazione tra MPI e la GPU? 🔴
OpenMP
3.1 Come funzionano i nested loop e come li gestiamo in OpenMP? 🔴
3.2 Come funziona lo scoping delle variabili in OpenMP? 🟠
Lo scoping delle variabili in OpenMP definisce la visibilità e l’accessibilità dei dati da parte dei thread all’interno di un blocco parallelo. A differenza della programmazione sequenziale, dove lo scope riguarda le parti del programma in cui una variabile è utilizzabile, in OpenMP indica quale set di thread può accedere a una determinata variabile.
Esistono due categorie principali di scope:
1. Scope Condiviso (Shared)
Una variabile con scope shared risiede in un’unica locazione di memoria accessibile da tutti i thread del team.
Comportamento di default: Le variabili dichiarate prima di un blocco parallelo sono considerate condivise per impostazione predefinita. Anche le zone di memoria allocate sullo stack del thread master sono solitamente accessibili ai figli.
2. Scope Privato (Private)
Una variabile con scope private è accessibile esclusivamente da un singolo thread. Ogni thread riceve una propria copia locale della variabile, distinta dalle altre.
Clausole di Modifica dello Scope
Il programmatore può controllare esplicitamente lo scope utilizzando diverse clausole:
private: Crea una copia locale non inizializzata per ogni thread. Il valore della variabile originale esterna non viene copiato all’interno.
firstprivate: Simile a private, ma ogni copia locale viene inizializzata con il valore che la variabile aveva prima dell’ingresso nel blocco parallelo.
lastprivate: Al termine del blocco, il valore calcolato dall’ultimo thread (quello che esegue l’ultima iterazione logica di un ciclo o l’ultima sezione) viene copiato nuovamente nella variabile originale esterna.
reduction: Utilizzata per operazioni di aggregazione. Ogni thread lavora su una copia privata (inizializzata all’elemento neutro dell’operatore) e, alla fine, OpenMP coordina la fusione di questi risultati parziali nella variabile condivisa finale.
shared: Specifica esplicitamente che una variabile deve essere condivisa. Viene usata principalmente quando è attiva la clausola default(none).
Gestione Avanzata e Persistenza
Per un controllo più granulare, OpenMP offre strumenti aggiuntivi:
default(none): Forza il programmatore a dichiarare esplicitamente lo scope di ogni variabile usata nel blocco che sia stata dichiarata esternamente. È considerata una buona pratica per evitare errori e ambiguità.
threadprivate: Crea uno storage specifico per il thread che persiste per tutta la durata del programma. Si applica a variabili globali o statiche, permettendo loro di mantenere il valore tra diverse sezioni parallele.
copyin: Utilizzata con threadprivate per inizializzare le copie locali di tutti i thread con il valore presente nella variabile del thread master.
2.4 Come funziona lo scheduling in OpenMP? 🟠
Lo scheduling in OpenMP determina come le iterazioni di un ciclo parallel for vengono distribuite tra i thread del team. Questa gestione avviene principalmente attraverso la clausola schedule(tipo, chunksize).
Ecco i diversi meccanismi di scheduling previsti dallo standard:
1. Scheduling Statico (static)
È la modalità predefinita in molte implementazioni.
Funzionamento: Le iterazioni vengono suddivise in blocchi di dimensione chunksize e assegnate ai thread in modo deterministico (spesso ciclico) prima dell’esecuzione del ciclo.
Esempio: Con 3 thread e 12 iterazioni, schedule(static, 1) assegna l’iterazione 0 al thread 0, la 1 al thread 1, la 2 al thread 2, la 3 al thread 0, e così via (partizionamento ciclico).
Vantaggio: Ha il minor overhead possibile.
Utilizzo: Ideale quando le iterazioni sono omogenee, ovvero hanno tutte lo stesso costo computazionale.
2. Scheduling Dinamico (dynamic)
Funzionamento: Le iterazioni sono divise in blocchi di dimensione chunksize. Ogni thread esegue un blocco e, una volta terminato, richiede dinamicamente un nuovo blocco al sistema di runtime.
Vantaggio: Garantisce un eccellente bilanciamento del carico (load balancing).
Svantaggio: Comporta un overhead maggiore dovuto alla gestione delle richieste durante l’esecuzione.
Utilizzo: Consigliato quando il costo computazionale delle iterazioni è irregolare o imprevedibile.
3. Scheduling Guidato (guided)
È una variante sofisticata dello scheduling dinamico.
Funzionamento: I thread richiedono nuovi blocchi, ma la dimensione dei blocchi diminuisce progressivamente (partendo da numero_iterazioni / numero_thread) fino a raggiungere il valore chunksize (o 1 se non specificato).
Vantaggio: Riduce l’overhead rispetto al dinamico puro e aiuta a prevenire il problema degli “straccioni” (stragglers), ovvero thread che rimangono indietro rallentando la barriera finale.
4. Altri tipi di Scheduling
auto: Lascia che sia il compilatore o il sistema di runtime a scegliere la strategia più appropriata per quel ciclo specifico.
runtime: La decisione viene posticipata al momento dell’esecuzione. Il sistema consulta la variabile d’ambiente OMP_SCHEDULE (es. export OMP_SCHEDULE="static,1") o la funzione omp_set_schedule().
Concetti chiave e Clausole aggiuntive
Chunksize: È un numero intero positivo che indica quante iterazioni consecutive compongono un singolo blocco di lavoro.
Efficienza: Se il carico è sbilanciato (ad esempio, le ultime iterazioni sono molto più pesanti delle prime), lo scheduling di default può portare a prestazioni scarse; in questi casi, uno scheduling ciclico o dinamico offre uno speedup decisamente migliore.
Clausola ordered: Se inserita in un for parallelo, permette di specificare blocchi di codice che devono comunque essere eseguiti rispettando l’ordine sequenziale delle iterazioni.
In sintesi, la scelta dello scheduler dipende dalla natura del calcolo: statico per lavori uniformi, dinamico o guidato per carichi variabili.
2.5 Parallelizza un loop che calcola l'element wise product di due array in OpenMP 🔴
2.6 Parallelizza questi due cicli: 🔴
for(int i = 2; i < N; i++) { A[i] = A[i - 2] + A[i] * 0.5; }//-------------------------------for(int i = 1; i < N; i++) { for(int j = 1; j < M; j++) { d[i][j] = d[i][j-1] + d[i-1][j-1] + d[i-1][j]; }}
Response
kjfhskd
CUDA
Differenza tra SM, Warp, Block, Grid? 🟢
Organizzazione Logiche:
La grid rappresenta l’intera struttura di thread lanciata per un determinato kernel CUDA.
È composta da uno o più blocchi.
Può essere strutturata in 1, 2 o 3 dimensioni.
Il blocco è un gruppo di thread che collaborano tra loro all’interno della griglia.
Sincronizzazione: I thread dello stesso blocco possono sincronizzarsi tramite la barriera __syncthreads().
Memoria condivisa: I thread di un blocco condividono una porzione di shared memory.
Vincolo hardware: Ogni blocco viene assegnato ed eseguito interamente su un singolo Streaming Multiprocessor (SM), un blocco non può essere diviso tra più SM.
Dimensioni: La dimensione massima di un blocco è solitamente di 1024 thread, a seconda della Compute Capability della GPU.
Organizzazione Fisiche:
Il warp è un sottogruppo di thread all’interno di un blocco:
Dimensione: Attualmente, un warp consiste in 32 thread consecutivi dello stesso blocco.
Modello SIMD: Tutti i thread in un warp eseguono la stessa istruzione simultaneamente su dati diversi.
Divergenza: Se i thread di un warp prendono percorsi diversi (ad esempio in un ramo if/else), si verifica una warp divergence, che serializza l’esecuzione dei rami riducendo le prestazioni.
L’SM (Streaming Multiprocessor) è l’unità hardware fisica che esegue effettivamente i thread della GPU.
Composizione: Ogni SM contiene molteplici CUDA core (o Streaming Processors)
Gestione blocchi: Un SM può ospitare ed eseguire più blocchi contemporaneamente, a patto che ci siano abbastanza risorse hardware (registri e shared memory).
Quali sono tutte le memorie utilizzabili in CUDA? E quali sono le loro differenze? 🟢
Memorie On-Chip (Velocissime)
Queste memorie si trovano direttamente all’interno dei core o dei multiprocessori streaming (SM):
Registri (Registers): È la memoria più veloce in assoluto. Ogni thread ha i propri registri privati per memorizzare variabili locali. I registri fisicamente appartengono al SM, e vengono logicamente suddivisi tra i thread attivi nel SM (quindi l’occupancy influisce sul numero di registri per processo).
Cache L1/L2: Sono memorie trasparenti al programmatore che operano automaticamente per ridurre la latenza degli accessi alla memoria globale. Ogni SM ha solitamente una L1 privata, mentre la L2 è condivisa tra tutti gli SM.
Shared Memory (Memoria Condivisa): È una memoria gestita dal programmatore tramite il decoratore __shared__. È condivisa tra tutti i thread di uno stesso blocco e ha prestazioni simili a una cache L1.
Constant Memory (Memoria Costante): Memoria in sola lettura per i thread della GPU, utile per memorizzare dati costanti definiti dall’host. È dotata di una cache dedicata e supporta il broadcasting, ovvero l’invio simultaneo di un valore a tutti i thread di un warp.
Nota: la cache L1 e la Shared Memory condividono in realtà la stessa memoria fisica, e CUDA decide come suddividere lo spazio tra queste due funzionalità.
Memorie Off-Chip (Alta Capacità)
Queste memorie risiedono nella DRAM della scheda video:
Global Memory (Memoria Globale): È la memoria principale della GPU (VRAM/HBM), accessibile da tutti i thread e dall’host tramite funzioni come cudaMemcpy. Ha una latenza molto più alta rispetto alle memorie on-chip, ma una capacità elevata.
Local Memory: Nonostante il nome, risiede fisicamente nella memoria globale. Viene utilizzata per variabili private di un thread che non possono essere contenute nei registri (ad esempio, a causa di un numero eccessivo di variabili o per array automatici).
Texture e Surface Memory: Memorie gestite da hardware specifico che facilita operazioni rapide di filtraggio e interpolazione, tipiche del rendering grafico.
Altre Tipologie e Concetti Chiave
Memoria Pinnata (Pinned Memory): Si tratta di memoria sulla RAM dell’host che è stata “bloccata” (page-locked). Poiché non può essere spostata dal sistema operativo, permette al controller DMA di eseguire trasferimenti dati verso la GPU molto più velocemente rispetto alla memoria host standard.
Unified Memory: Dalla versione 6 di CUDA, permette di avere un unico spazio logico di indirizzamento per host e GPU, gestendo i trasferimenti in modo trasparente.
In sintesi, per ottimizzare le prestazioni, un programma CUDA cerca di massimizzare l’uso di registri e shared memory per ridurre i costosi accessi alla memoria globale.
3.1 Cos'è il tiling? 🟢
Il tiling è una tecnica di ottimizzazione per gli accessi in memoria per la programmazione GPU.
Consiste nel suddividere grandi strutture dati (tipicamente matrici) in blocchi più piccoli, chiamati “tiles”.
Le tile vengono shared memory invece di continuare a leggerle dalla memoria globale, il titiling è necessario in quanto la shared memory solitamente non è abbastanza grande per contenere i dati per intero.
In un’implementazione con tiling, i thread di uno stesso blocco collaborano: ogni thread carica una piccola porzione della “tile” dalla memoria globale alla shared memory. Poi vengono effettuati i calcoli sulla tile e una volta finito si caricano in shared la nuova tile.
3.2 Cos'è la Pinned Memory? 🟢
La Pinned Memory (o Page Locked Memory) è una porzione di memoria virtuale dell’host (CPU) che viene contrassegnata in modo da non poter essere “paginata” (ovvero spostata dalla RAM al disco rigido) dal sistema operativo.
In ambito CUDA, questa tecnica è fondamentale per ottimizzare i trasferimenti di dati tra l’host e il device (GPU), in quanto permette di sfruttare il DMA (Direct Memory Access) che effettua i trasferimenti senza l’utilizzo della CPU.
Approfondimento: il DMA opera utilizzando gli indirizzi fisici della memoria, è necessario che i dati rimangano bloccati in una posizione fisica fissa per tutta la durata del trasferimento. Senza il “pinning”, il sistema operativo potrebbe spostare quelle pagine di memoria, causando errori durante l’accesso del DMA.
Vantaggi:
Riduzione dell’overhead: Se si tenta di copiare dati da una memoria host standard (non-pinned), CUDA deve prima copiare i dati in un buffer “pinned” temporaneo prima di avviare il trasferimento DMA, creando un passaggio intermedio lento.
Velocità: Utilizzando direttamente la memoria pinnata, si evita questa copia extra, ottenendo incrementi prestazionali che vanno dal 10% fino a 2,5 volte a seconda della dimensione dei dati.
Latenza: È considerata una strategia comune di gestione della memoria per fornire riferimenti stabili e rapidi per i trasferimenti.
Svantaggi:
Sebbene velocizzi i trasferimenti, un uso eccessivo di memoria pinnata può essere dannoso per le prestazioni globali dell’host, poiché riduce la quantità di RAM che il sistema operativo può gestire liberamente per la memoria virtuale.
3.3 Cosa sone le memory banks? Quando avvengono i bank conflicts e le bank broadcast? 🟢
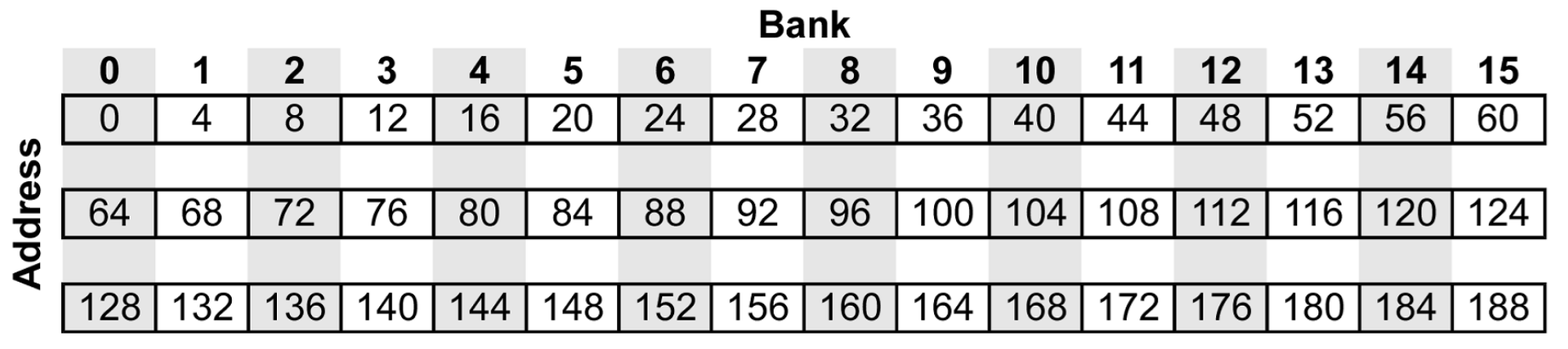
La shared memory è organizzata in banchi di memoria di uguale dimensione per consentire accessi simultanei e ad alta velocità.
Organizzazione: gli indirizzi di memoria sono interallacciati (interleaved) tra i banchi, il che significa che indirizzi consecutivi appartengono a banchi diversi.
Capacità di servizio: Ogni banco può servire un solo accesso per ciclo di clock.
Quando avvengono i Bank Conflicts?
Un bank conflict si verifica quando più thread all’interno di un warp tentano di accedere contemporaneamente a indirizzi diversi che risiedono nello stesso banco.
Serializzazione: Poiché il banco può gestire solo una richiesta alla volta, gli accessi vengono serializzati. Se, ad esempio, 8 thread accedono allo stesso banco, l’operazione richiederà 8 cicli invece di uno, con una conseguente perdita di prestazioni.
Condizione di assenza di conflitti: Se tutti i thread accedono a banchi diversi (ad esempio con un accesso lineare e stride = 1), l’accesso è istantaneo.
3.7 Cosa sono i coalesced memory accesses? 🟢
I coalesced memory accesses (accessi alla memoria coalizzati) permettono di combinare molteplici richieste di memoria effettuate dai thread di un warp in un’unica transazione di memoria, riducendo l’utilizzo della banda.
Quando i thread di un warp eseguono un’istruzione di caricamento (load) o memorizzazione (store), l’hardware rileva se gli indirizzi richiesti dai singoli thread sono tra loro consecutivi nella memoria globale.
Esempio: thread 0 accede alla locazione N, il thread 1 alla locazione N+1, il thread 2 alla N+2 e così via, l’hardware “coalizza” queste 32 richieste individuali in un’unica transazione.
Perché l’accesso sia pienamente coalizzato, devono essere rispettate alcune condizioni:
Consecutività: I thread del warp devono accedere a una raffica (burst) contigua di elementi in memoria.
Allineamento: L’indirizzo iniziale della transazione (N) deve essere tipicamente un multiplo della granularità della cache (ad esempio 32 byte per la cache L2 o 128 byte per la cache L1).
Vantaggi e Impatto sulle Prestazioni
Efficienza del Bus: L’obiettivo principale è massimizzare l’utilizzo della banda passante della memoria globale. Un accesso coalizzato e allineato permette un’utilizzazione del bus del 100%, poiché ogni byte trasferito viene effettivamente utilizzato da un thread.
Riduzione delle transazioni: Senza coalescing, l’hardware dovrebbe emettere molteplici transazioni separate per soddisfare un singolo warp, aumentando drasticamente la latenza e riducendo il throughput.
Organizzazione dei dati: Per favorire il coalescing, è spesso preferibile utilizzare strutture dati di tipo Struct of Arrays (SoA) invece di Array of Structs (AoS), poiché la SoA garantisce che i thread che accedono allo stesso campo (es. la coordinata ‘x’) trovino i dati consecutivi in memoria.
In sintesi, i coalesced accesses trasformano molte piccole letture potenzialmente lente in un unico trasferimento rapido e massiccio, permettendo all’applicazione di non essere limitata eccessivamente dalla banda di memoria (memory-bound).
3.2 Quando è utile disabilitare la cache L1 in CUDA? 🟢
In generale è conveniente disabilitare la memora cache L1 quando si effettuano accessi in memoria con pattern irregolari, non coalizzati e non allineati.
La differenza fondamentale tra un caricamento tramite cache L1 e uno che la esclude risiede nella granularità del dato prelevato dalla memoria globale:
Con cache L1 abilitata: Ogni richiesta carica una linea intera da 128 byte.
Con cache L1 disabilitata (caricamento non-cached): La granularità si riduce a segmenti di 32 byte (tipici della cache L2).
Disabilitare la L1 è consigliabile quando l’applicazione presenta:
Accessi non coalizzati: Se i thread di un warp richiedono indirizzi di memoria molto distanti tra loro, il caricamento di una linea da 128 byte per ogni singolo thread risulterebbe estremamente inefficiente, poiché verrebbero spostati molti byte inutilizzati sul bus, riducendo drasticamente la banda effettiva.
Accessi non allineati: In caso di accessi disallineati, l’utilizzo della cache L1 potrebbe costringere l’hardware a caricare due linee da 128 byte (totale 256 byte) per servire una singola richiesta del warp, mentre senza L1 potrebbero bastare meno segmenti da 32 byte, ottimizzando l’uso del bus.
Rischio di Thrashing: Disabilitare la L1 riduce il rischio di overhead o di “thrashing” (ovvero quando i dati utili vengono continuamente espulsi dalla cache prima di essere riutilizzati) in presenza di pattern di accesso irregolari.
3.3 Perché le GPU non hanno il problema del false sharing? 🟢
Le GPU non soffrono del problema del false sharing grazie al modo specifico in cui gestiscono le operazioni di scrittura (store) e la coerenza della memoria tra i diversi Streaming Multiprocessor (SM).
Ecco i motivi principali spiegati dai materiali:
1. Gestione delle Scritture (Write Policy)
Nelle architetture CPU, il false sharing si verifica quando più thread modificano variabili indipendenti che risiedono nella stessa linea di cache, costringendo l’hardware a invalidare e aggiornare continuamente le cache L1 private degli altri core per mantenerle coerenti.
In CUDA, la gestione della memoria globale per le operazioni di scrittura segue una logica diversa:
Invalidazione della L1: Quando viene eseguita una scrittura nella memoria globale, l’hardware invalida la linea nella cache L1 locale e procede con un write-back verso la cache L2 (punto di coerenza comune per tutti gli SM).
Assenza di Coerenza Hardware L1-L1: A differenza delle CPU, il sistema di memoria CUDA non tenta di mantenere automaticamente la coerenza tra le cache L1 private dei vari SM. Spostando la responsabilità della coerenza e della visibilità dei dati sul programmatore.
3.4 Scrivi un CUDA kernel che effettua la somma di due array 🟢
__gobal__ void arrSum(int* d_A, int* d_B, int* d_C, int n) { int gid = (blockDim.x * blockIdx.x) + threadIdx.x; if (gid < n) { d_C[gid] = d_A[gid] + d_B[gid] }}
3.5 Scrivi un CUDA kernel che calcola l'(element-wise) product between two arrays. 🟢
__gobal__ void arrMult(int* d_A, int* d_B, int* d_C, int n) { int gid = (blockDim.x * blockIdx.x) + threadIdx.x; if (gid < n) { d_C[gid] = d_A[gid] * d_B[gid] }}
3.6 Write a CUDA kernel that computes the product between two matrices 🔴
3.8 Nella programmazione GPU conviene utilizzare Array of Structs o Struct of Arrays? 🟢
In ambito GPU, l’organizzazione dei dati Struct of Arrays (SoA) è più conveniente rispetto alla Array of Structs (AoS).
Questa preferenza è dovuta principalmente a come la GPU gestiscono gli accessi alla memoria.
1. Coalescing della memoria (Accesso Coalizzato)
Il motivo principale è favorire il coalescing. Per sfruttare quest’ultimi è necessario che i treads di un warp accedano contemporaneamente ad indirizzi di memoria contigui tra loro.
In una SoA: Tutti i valori x sono memorizzati consecutivamente. Pertanto, se il thread 0 accede a x, il thread 1 a x e così via, gli indirizzi sono contigui e l’accesso viene coalizzato perfettamente.
In una AoS: Tra un valore x e il successivo (ad esempio tra AoS.x e AoS.x) sono presenti altri campi della struttura (come y e z). Questo rende gli indirizzi richiesti dai thread non contigui, impedendo il coalescing e costringendo l’hardware a emettere molteplici transazioni separate per servire un singolo warp.
2. Utilizzo efficiente del Bus e della Cache
L’uso della SoA massimizza l’efficienza della banda passante e della cache:
Riduzione degli sprechi: Con la SoA, vengono caricati dalla memoria globale solo i dati effettivamente necessari per il calcolo corrente (es. solo i valori x). Nella AoS, per leggere x, l’hardware caricherebbe intere linee di cache contenenti anche y e z, che verrebbero sprecate se il kernel non le utilizza immediatamente, saturando inutilmente il bus.
Spazio in memoria: La SoA può risultare più compatta, poiché la AoS spesso richiede del padding (riempimento) tra le strutture per garantire l’allineamento corretto dei campi, aumentando l’occupazione di memoria.
3.9 Come cudaMemcpy() funziona tra CPU e GPU? 🟢
La funzione cudaMemcpy() è il meccanismo principale fornito da CUDA per trasferire dati tra l’Host (CPU e RAM) e il Device (GPU e VRAM).
cudaMemcpy() utilizza l’hardware DMA (Direct Memory Access), questo permette alla CPU di non occuparsi fisicamente del trasferimento, lasciando che l’unità DMA gestisca lo spostamento dei dati.
Il DMA opera utilizzando indirizzi fisici di memoria. Poiché i sistemi operativi moderni usano la memoria virtuale, le pagine di dati potrebbero essere spostate o rimosse dalla RAM fisica proprio durante un trasferimento, causando errori.
Per questo ecessario utilizzare la memoria pinnata:
Requisito di Pinning: Il DMA richiede che la memoria host coinvolta sia “pinnata” (o page-locked), ovvero bloccata in una posizione fisica fissa e non soggetta a paging.
Overhead della memoria standard: Se i dati dell’utente si trovano in una memoria host standard (non pinnata), CUDA deve prima copiarli internamente in un buffer pinnato temporaneo prima di avviare il DMA, introducendo un passaggio extra lento.
Ottimizzazione: È più veloce allocare i dati direttamente in memoria pinnata (usando cudaMallocHost()) per evitare questa doppia copia, ottenendo guadagni prestazionali dal 10% fino a 2,5 volte.