Introduzione
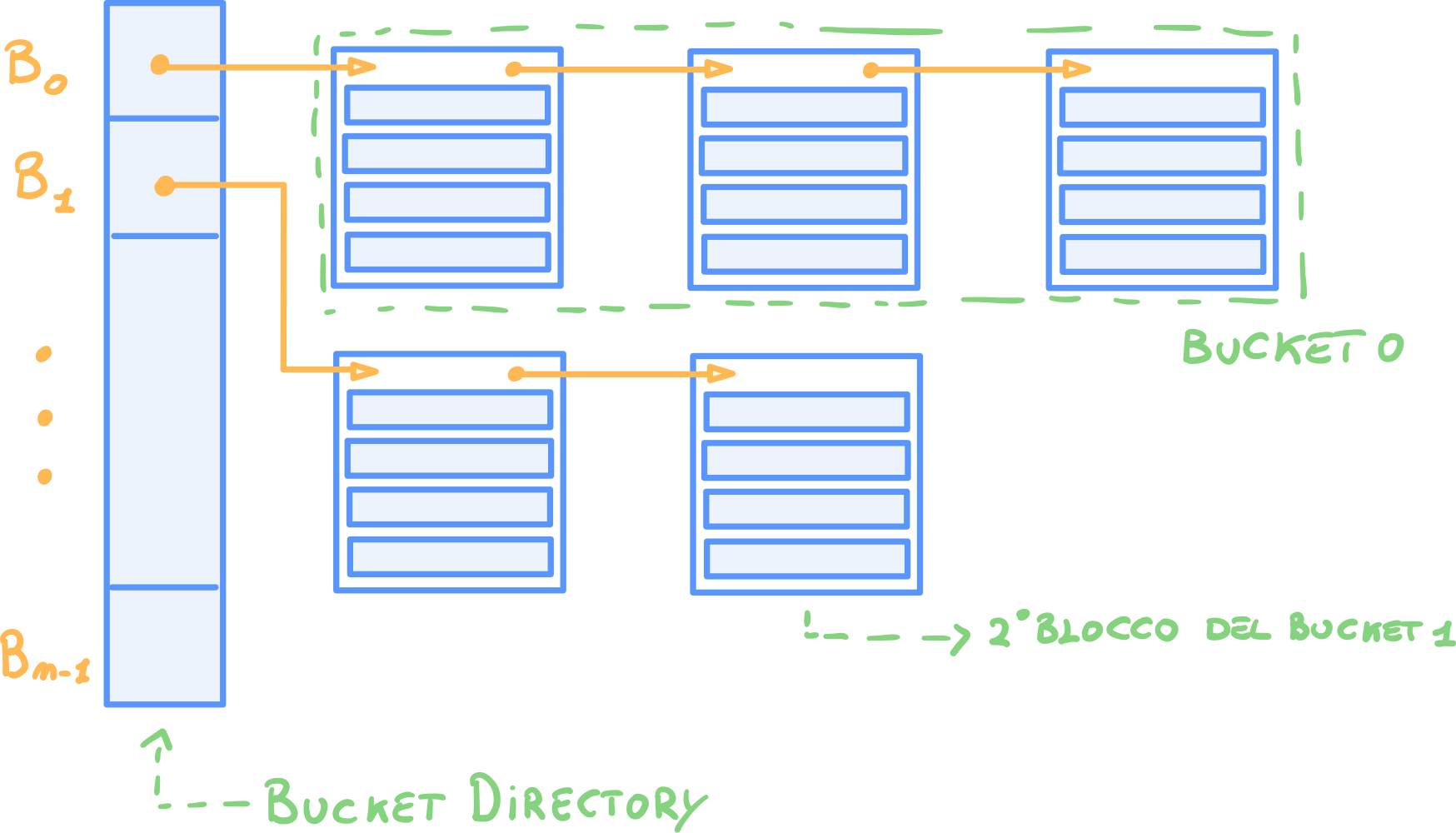
Il file hash è suddiviso in bucket numerati da a , ciascun bucket è costituito da uno o più blocchi collegati fra loro tramite puntatori e organizzati come un heap.
In cima al file c’è la bucket directory che contiene tutti i puntatori per i bucket, la lunghezza della directory è uguale al numero di bucket ().
Funzione Hash
Dato un valore v per la chiave, il numero del bucket in cui deve trovarsi un record con chiave v è calcolato mediante una funzione chiamata funzione hash.
Una funzione di Hash per essere “buona” deve suddividere in modo equo i record nei vari bucket, quindi al variare della chiave tutti i bucket devono avere la stessa probabilità di “uscita”.
Funzionamento: In genere una funzione hash trasforma la chiave in un numero, lo divide per B e fornisce il resto della divisione come numero del bucket (in modo da rimanere limitati al numero di bucket), questo resto è il bucket dove andrà inserito il record.
Esempio
Trattiamo il valore v della chiave come una sequenza di bit, ad esempio , dividiamo tale sequenza in gruppi di bit uguali fra loro e sommiamo tali gruppi come se fossero interi:
Adesso dividiamo questo risultato per il numero di bucket e prendiamo il resto della divisione, questo sarà il bucket. Ad esempio se allora calcoliamo , quindi il record che ha questa chiave andrà inserito nell’ultimo blocco del bucket 2.
Chiave
Quando ci rifermiamo a chiave di hash non intendiamo sempre la chiave relazionale dell’attributo. La chiave di hash può anche essere un insieme di attributi su cui facciamo spesso operazioni.
Operazioni
Una qualsiasi operazione su un file hash richiede:
- Valutazione della funzione di hash per v,
h(v), per individuare il bucket su cui eseguire l’operazione (per noi questo ha costo 0 dato che ci interessano soltanto gli accessi in memoria.) - Esecuzione dell’operazione sul bucket che è organizzato come un heap.
Puntatore alla fine del bucket
Dato che l’inserimento di nuovi record viene effettuato sull’ultimo bucket, a volte la bucket directory può contenere anche un puntatore all’ultimo record di ogni bucket (oltre che il puntatore all’inizio).
Costo Operazioni
Definiamo:
- è numero di record
- è numero di bucket
Se la funzione di hash distribuisce uniformemente i record nei bucket allora ogni bucket è consistito da blocco.
Il costo di ricerca è pari al costo di ricerca su bucket ottunuto attraverso alla funzione hash. In particolare se descriviamo il costo come numero di accessi in memoria avremo che:
Differenza con File Heap
Di conseguenza, il costo di qualsiasi operazione può essere approssimato a del costo della stessa operazione se il file fosse stato organizzato come una heap.
Ciò è dovuto al fatto che, una volta trovato il bucket corretto (il cui costo è trascurabile grazie alla funzione di hash), dobbiamo eseguire l’operazione sul bucket stesso come se fosse una heap, ma con una dimensione ridotta di record invece di .
Dimensione massima della bucket directory
Ovviamente più bucket abbiamo più è basso il costo delle operazioni, ma dobbiamo ci sono dei fattori che limita il numero di bucket che possiamo utilizzare:
- Ogni bucket deve avere almeno un blocco.
- La bucket directory deve avere una dimensione tale da essere mantenuta in memoria principale altrimenti effettueremo accessi per leggere i blocchi della bucket directory.