CPU
La CPU è progettata per ridurre la latenza (quindi alte frequenze di clock, gradi cache per ridurre accessi a memoria, breach prediction per avvantaggiare)
Nella CPU ogni core ha una propria unità di controllo, permettendo ad ogni core di eseguire codice diverso da gli altri.
Queste funzionalità portano ad avere (poche) grandi ALU
GPU
La GPU è progettata in modo da massimizzare la banda (throughput).
La GPU punta ad avere ALU più semplici e piccole, ma di conseguenza ad averne molte di più.
Questo porta ad avere:
- frequenze di clock più basse
I core delle GPU spesso condividono le ALU questo permette di risparmiare spazio ma ne consegue che gruppi di core devono eseguire lo stesso blocco di codice.
CPU vs GPU
Dipende dal contesto:
- Le GPU sono estremamente performanti in casi in cui il programma contiene pochissime part sequenziali, e non ha brenching (if else)
- Le CPU, altrimenti
Memoria e APU
La CPU utilizza la memoria RAM connessa attrvaerso un bus PCIEexpress
La GPU è collegata direttamente ad una memoria ram molto veloce, senza nessun bus intermedio.
Le APU sono una tipologia una tipologia di chip che dove la CPU e la GPU condividono la memoria ram, tutto collegato attraverso un bus PCIE.
Floating Point
La CPU e la GPU potrebbero avere risultati differenti quando si effettuano calcoli con floating point, infatti potrebbero utilizzare sistemi di approssimazione e rappresentazione diversi per i numeri floating-point.
CUDA vs HIP
CUDA:
HIP:
OpenCL: non viene più utilizzato (almeno per HCP e IA)
OpenACC: framework ad alto livello che utilizza delle pragma (simile a OpenMP) che permette di eseguire sia su AMD che NVIDIA
CUDA
In CUDA i thread sono organizzati in blocchi
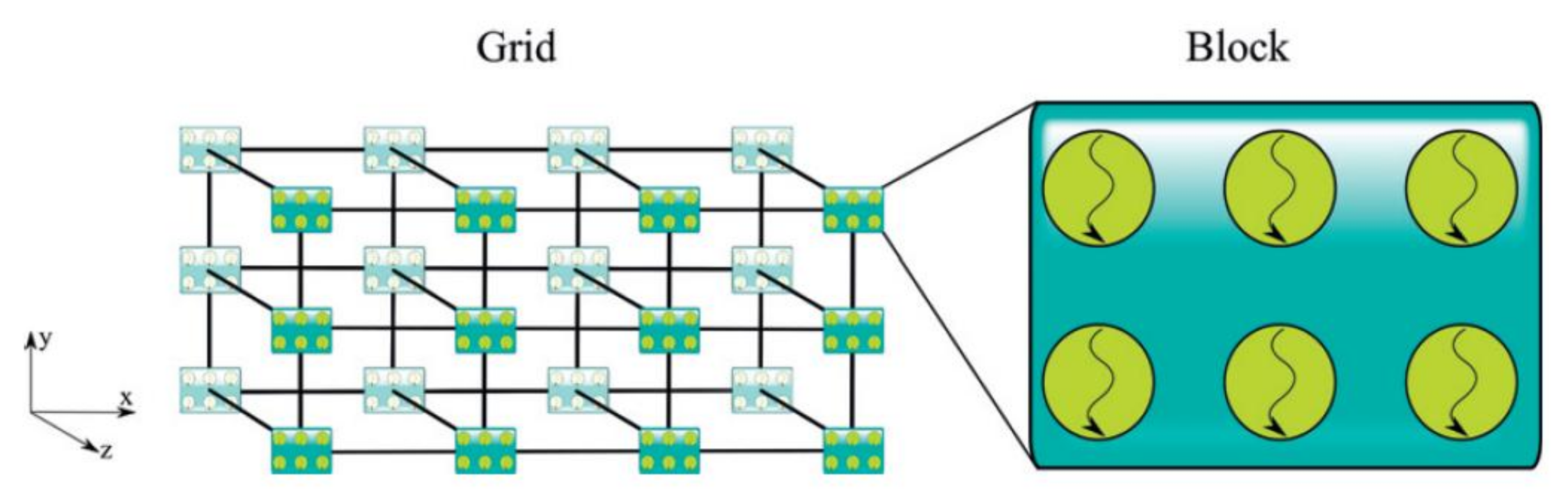
Come scrivere un programma
Utilizziamo il modello SIMD (single instruction multiple data) a da nvidia viene chiamato SIMT (single instruction multiple threads).
Prima di tutto dobbiamo definire:
- La dimensione dei blocchi, es:
dim3 block(3,2); - La dimensione delle griglie, es:
dim3 grid(3,2);
Dove dim3 è un tipologia di dato che equivale ad una tripletta.
Decoratori di funzione
global:
device: una funzione che viene eseguita solamente sulla GPU e può essere chiamata nel kernel (ovvero dalla GPU)
host:
NOTE
- Non chiamare mai una print fa dentro il kernel
- al esame potrebbe chiedere come si calcola l’id di un thread in 2D
Thread Scheduling
Lo scheduling su GPU è praticamente gratuito rispotto alla scheduling su CPU.
Questi perché … (qualcosa riguardante i registri, non ho capito bene)
Warp
Una delle limitazione delle GPU è che tutti i threads contenuti nello stesso warp eseguono la stessa istruzione su dati diversi.
**Problema:
il caso in cui 2 o più threads provano a divergere ovvero che provano ad eseguire codice diverso degli altri (es brenching dovuto a if).
Nel caso in cui ci dovesse essere un branch nel codice, si ha che una parte dei threads esegue il primo ramo e l’altra parte non fa nulla, alle fine dell’esecuzione del ramo 1, si passa all’altro possibile ramo che verrà eseguito dai restati threads.
Conseguenze: questo porta alla riduzione dell’utilizzo del warp.
…
Context Switching
Come abbiamo detto uno dei svantaggi della gpu è l’alta latenza, per risurre questo problema è stato sono state proggette in modo tale da poter fare un contex switching a costo praticamente nullo.
Questo permetto che quando un warp fa una chiamata alla memoria e deve espettare i dati, durante l’attesa viene sfruttato il basso costo del context switching per fare il context switching con un nuovo warp, il warp precedente verrà eseguito quando arriveranno i dati rchiesti alla memoria.
Per questi che utile avere più sm rispetto al numero di core della cpu.
Questo permette di fare latency hiding, esempio:

Device Properties
Memory Hierarchy
Memori Access
Se facciamo malloc “normalmente” questi tati allocati non saranno accessibili alla GPU, in quanto non ha accesso alla stessa memoria della CPU.
Per allocare la memoria sulla GPU si deve utilizzare cudaMalloc;
he prende un parametro che è la dimenzione in bite della memoria da allocare.