OpenMP è un framework di programmazione per i sistemi multicore a memoria condivisa. Costituisce un interfaccia di gestione dei thread ad alto livello rispetto quella fornita da PThread, che permette una parallelizzazione del codice più semplice.
È inoltre portatile e può funzionare anche su Windows altre a permettere di programmare la GPU.
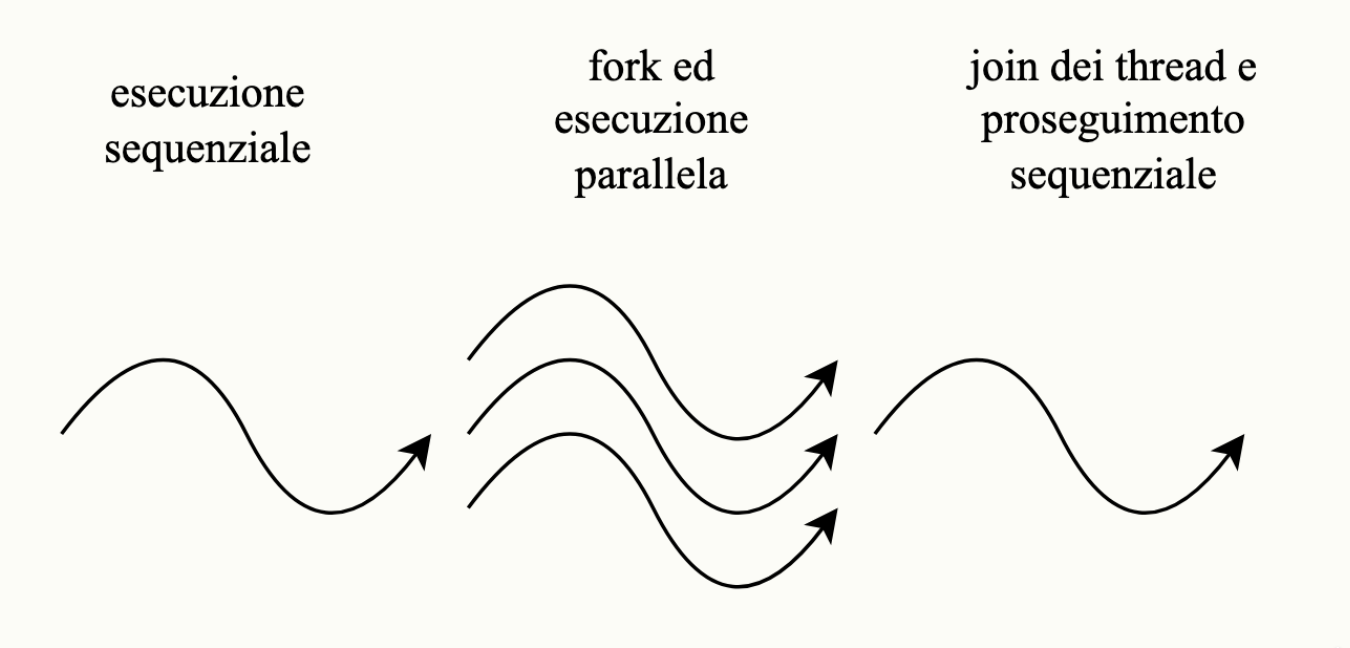
Lo scopo di OpenMP è la decomposizione di alcune porzioni del programma al fine di renderle parallele per svolgere un determinato compito, alla fine di esso i thread possono essere eliminati ed il programma può tornare ad un esecuzione sequenziale.
La parallelizzare un codice sequenziale in maniera semplice avviene attraverso l’utilizzo di alcune direttive, che il compilatore utilizzerà per determina dove e come parallelizzare il codice.
Quindi per utilizzare OpenMP è necessario importare la libreria omp.h , sia avere un compilatore che supporti le direttive, che in caso contrario verranno ignorate ed il codice varrà eseguita parallelamente.
Direttive Pragma
Le pragma sono delle direttive speciali che elabora il pre processore, tali che se openMP non è supportato dal compilatore, queste ultime verranno ignorate. Servono per conferire al sistema funzionalità di parallelizzazione non incluse nel comportamento standard del linguaggio C.
La direttiva più semplice ma anche più importante è:
# pragma omp parallel
Una volta dichiarata nel codice, il blocco successivo verrà eseguito in parallelo.
Numero di Threads
Normalmente # pragma omp parallel utilizza il numero massimo di threads presenti nella macchina per effettuare la parallelizzazione.
Me è possibile specificare il numero di threads utilizzati, utilizzando uno di questi 3 modi:
1) Utilizzando la variabile d’ambienteOMP_NUM_THREADS tramite la bash, ad esempio:
export OMP_NUM_THREADS=4
Questa specifica varrà per tutti i programmi che faranno uso di OpenMP in quell’ambiente.
2) Utilizzando la funzioneomp_set_num_threads() prima di un blocco di codice parallelo.
3) Specificando nella direttiva pragma il numero di thread da utilizzare con num_threads ( thread_count ), esempio:
#pragma omp parallel num_threads (4)
Nota: Come num_threads esistono altre clausole in grado di modificare le direttive pragma, specificando dettagli aggiuntivi sul comportamento.
Sono anche fondamentali le seguenti funzioni:
omp_get_thread_num(): ritorna l’identificatore del thread chiamante.
omp_get_num_threads() : ritorna il numero di thread attivi (se chiamata in una porzione sequenziale, ritornerà 1).
Esempio di codice:
#include <stdio.h>#include <stdlib.h>#include <omp.h>void Hello(void) { int my_rank = omp_get_thread_num(); int thread_count = omp_get_num_threads(); printf("Hello from thread %d of %d", my_rank, thread_count);}int main(int argc, char *argv[]) { int thread_count = atoi(argv[1]); #pragma omp parallel num_threads(thread_count) Hello(); return 0;}
Cosa succede a basso livello
La funzione Hello() essendo preceduta dalla direttiva pragma verrà eseguita in parallelo. OpenMP funziona come Pthreads, vi è un thread main che si occupa di eseguire i fork generando gli altri thread, per poi ricongiungerli (join) ad una sola esecuzione. Per motivi di ottimizzazione, OpenMP potrebbe mantenere i thread sempre attivi in uno stato di “idle” (attesa), per poi richiamarli ed utilizzarli quando necessario, evitando di crearne di nuovi ogni volta.
OpenMp non supportato
Uno dei lati positivi del codice che contiene OpenMP è che può essere seguito e compilato anche da sistemi che non lo supportano (ovviamente il codice non verrà parallelizzato), infatti se compilatore non lo supporta:
Le direttive come #pragma omp parallel vengono interpretate come commenti
Le funzioni di OpenMp come omp_get_thread_num() e include <omp.h> possono essere ignorate in questo modo:
#ifdef _OPENMP# include <omp.h>#endif#if def _OPENMP int my_rank = omp_get_thread_num(); int thread_count = omp_get_num_threads(); #else int my_rank = 0 ; int thread_count = 1 ;#end if
Mutua Esclusione
Quando un programma eseguito con OpenMP, contiene più thread che accedono alle stesse variabili, rischia di entrare in una race condition.
Sezione Critica
Una soluzione a questo problema possiamo creare una sezione critica utilizzando la direttiva:
#pragma omp critical
Nota: Questa direttiva simula l’utilizzo di unalock e poi di unlock, quindi la sezione verrà eseguita in modo seriale da tutti i threads.
Per ridurre l’impatto sulle performance, si deve scrivere meno codice possibile in una sezione critica, ad esempio il seguente codice non è ottimizzato:
global_result = 0.0;#pragma omp parallel num_threads(10){ #pragma omp critical global_result += Local_trap(double a, doble b, int n);}
Questo perché eseguiamo Local_trap(...) all’interno della sezione critica anche se non ce ne è bisogno, una versione ottimizzata è:
global_result = 0.0;#pragma omp parallel num_threads(10){ double my_result = 0.0; //variabile locale di ogni therad my_result += Local_trap(double a, doble b, int n); #pragma omp critical global_result += my_result;}
In questo modo la sezione critica contiene soltanto l’operazione modificano le variabili condivise. Invece local Local_trap( ... ) è un operazione che legge gli input a, b, c e non lo modifica quindi può essere eseguita in modo parallelo.
Operazioni Atomiche
Alcuni processori moderni implementano le operazioni di incremento come un unica istruzione atomica:
load+sum+store
In tal caso è possibile utilizzare la direttiva pragma:
#pragma omp atomic
che risulta più efficiente rispetto ad usare critical in quanto copre la mutua esclusione solo dell’aggiornamento della variabile e non di tutto il blocco.
Riduzione
OpenMP permette di eseguire le collettive di riduzione, come, ad esempio la chiamata MPI_Reduce.
La clausola di riduzione viene aggiunta ad una direttiva pragma ed è definita come segue:
reduction(<operator>:<reduction variable>)
Dove:
gli operatori disponibili sono: + * - & | ^ && || (o è possibile definire operazioni custom).
reduction variable è la variabile che verrà ridotta, e deve essere dichiarata prima della reduction.
Quando si utilizza una reduction in ogni thread viene inizializzata una variabile privata, che verrà poi utilizzata per effettuare i calcoli interni al therad.
Alla fine della blocco parallelo le variabili private dei thread, verranno accumulate nella reduction variable, utilizzando l’operatore specificato .
Nota: le variabili private verranno inizializzate ad un valore di default che dipende dall’operatore di riduzione che si sta utilizzando, ad esempio:
per la somma (+) le variabili vengono inizializzate a 0
per il prodotto (*) le variabili vengono inizializzate a 1
Esempio Integrazione Numerica
lkfdjlkasfjlksjfdgklfjsd
Scoping
Normalmente con scope di una variabile, si intende le porzione di codice in cui quella variabile è accessibile e può
essere utilizzata.
Nei programmi paralleli con OpenMP, con scope ci si riferisce all’insieme di thread che può accedere la specifica variabile nel blocco parallelo.
Una variabile può essere:
Shared
Ovvero una variabile che è accessibile da ogni thread del blocco.
Le variabili dichiarate prima di un blocco parallelo rientrano in questa categoria. Inoltre anche le zone di memoria allocate sullo stack del thread master sono accessibili dai suoi figli.
Private
Ovvero una variabile accessibile da un singolo thread, le variabili dichiarate all’interno di un blocco parallelo sono private, ed ogni thread ne avrà una sua copia distinta dalle altre.
È possibile specificare la visibilità delle variabili utilizzando le seguenti clausole:
shared(...)
È il comportamento di default delle variabili al di fuori del blocco parallelo, va quindi specificata per queste ultime solo se presente anche la clausola default(none).
reduction(...)
Specifica che una variabile dovrà essere soggetta ad un operazione di riduzione. Ci saranno delle copie di quest’ultima private per ogni thread, ma il risultato finale sarà condiviso.
La variabile avrà una copia privata per ogni thread nel blocco. Le variabili private di default non sono inizializzate.
Ad esempio:
int x = 5;#pragma omp parallel private(x){ x = x+1;}printf(" x is %d, x)
Nel blocco di codice mostrato, la chiamata di funzione printf stamperà in output “x is 5” in quanto x è privata ed inoltre l’incremento di x all’interno del blocco parallelo può causare errore in quanto x non inizializzata di default.
Esistono altre 4 clausole per specificare lo scope di una variabile:
firstprivate: come private ma la copia locale viene inizializzata con il valore della variabile originale (quella “esterna” al blocco) prima che il blocco venga eseguito.
lastprivate: come private ma sl termine dell’esecuzione del blocco parallelo, il valore della copia locale dell’ultimo thread che ha completato il ciclo viene copiato nella variabile originale (quella “esterna” al blocco).8