Introduzione
Il protocollo TCP è un servizio affidabile ed orientato alla connessione, per questo è richiesto un setup fra i processi client e server.
Servizi Forniti
Stesse cose fornite dal UDP:
- Comunicazione tra processi utilizzando i Socket
- demultiplexing dei pacchetti
- Incapsulamento e decapsulamento
Inoltre fornisce funzionalità avanzate come:
- Trasporto affidabile fra i processi di invianti e riceventi.
- Controllo di flusso: il mittente cerca di non sovraccaricare il destinatario
- Controllo della congestione: Riduce i dati inviati quando le rete è sovraccaricata
Servizi non Forniti
Non fornisce temporizzazione, garanzie su un ampiezza di banda minima, sicurezza (alcune possono essere implementate, es. SSL)
Flusso di Byte
Una delle differenze con il protocollo UDP è che la comunicazione tra mittente e ricevente può essere vista come un flusso di byte e non come un invio di pacchetti.
Servizio Connection Oriented
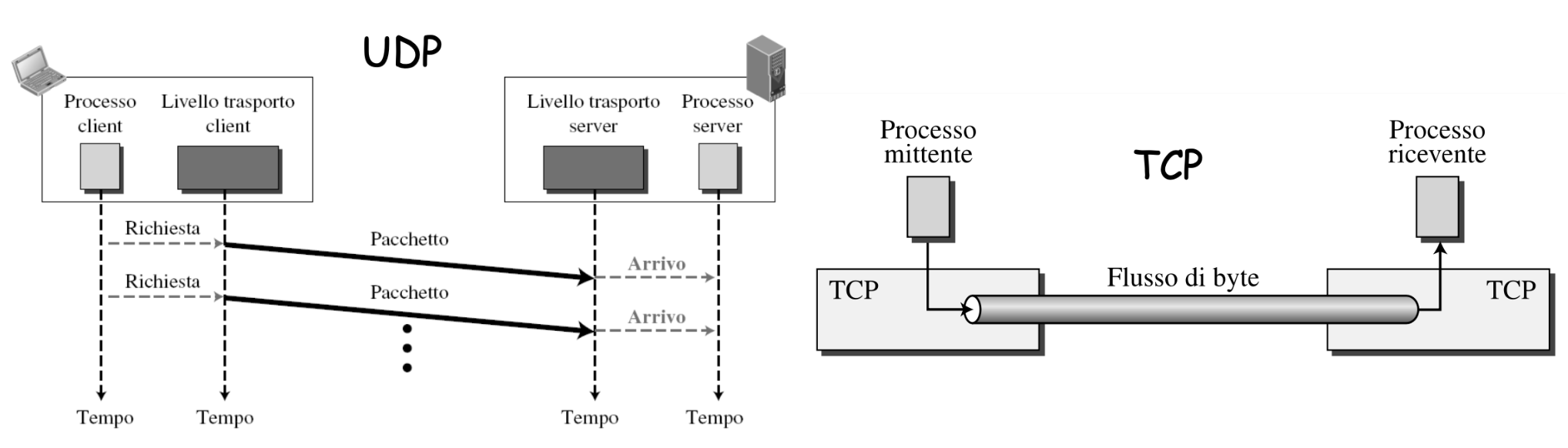
Il TCP è un servizio orientato alla concessione, per questo prima del inizio dell’invio dei dati veri e propri i due terminali devono stabilire una connessione logica.
Questo permette ai due terminali di avere delle comunicazioni bilaterali rendendo possibile implementare:
Rappresentazione mediante Finite State Machine
Demultiplexing (orientato alla connessione)
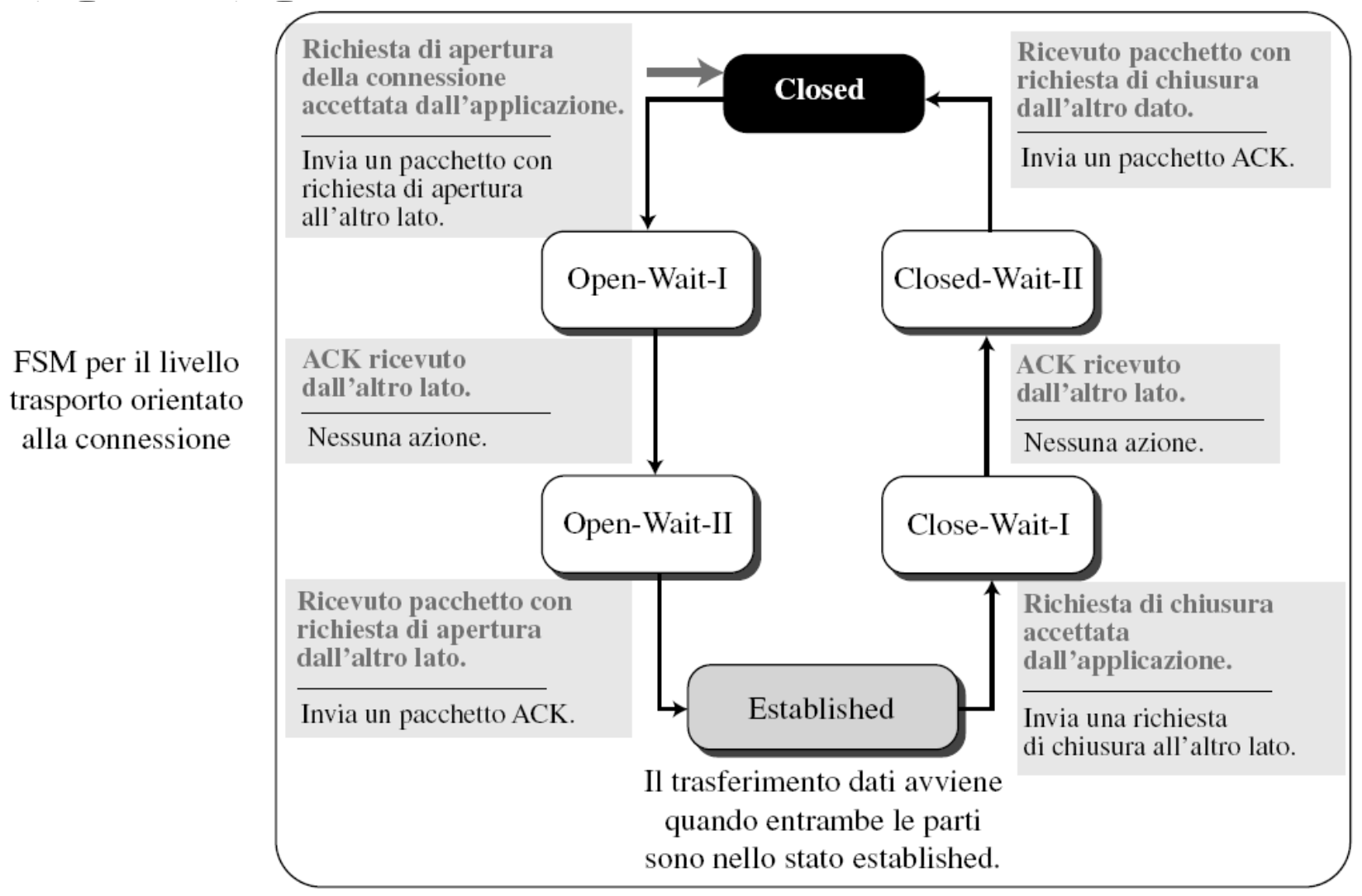
La socket TCP è identificata da 4 parametri:
- Indirizzo IP e porta di origine
- Indirizzo IP e porta di destinazione
Un host server può supportare più socket TCP contemporanee dato che ogni socket è identificata dai 4 parametri. Si avrà una socket differente anche per lo stesso client, ogni richiesta viene trasmessa su una diversa socket.
Essenzialmente il server accetta tutte le connessioni sulla stessa socket e poi le sposta su una porta differente.
Controllo Flusso
Quando un’entità produce dati che un’altra entità deve consumare, deve esistere un equilibrio fra la velocità di produzione e la velocità di consumo dei dati.
- Se
velocità di produzione > velocità di consumo- il consumatore potrebbe essere sovraccaricato e costretto a eliminarne alcuni dati in input - Se
velocità di produzione < velocità di consumo- l consumatore rimane in attesa riducendo l’efficienza del sistema
La soluzione consiste nel utilizzare dei buffer, ovvero zone di memoria che memorizzano pacchetti, questo permette al consumatore (ricevente) di notificare il produttore (mittente) quando il suo buffer è saturo in modo tale da ridurre la produzione ed evitare perdita di dati.
Come vedremo l’utilizzo di un buffer, permetterà al consumatore anche di dati che arrivano in un ordine sbagliato.
Entità
Il sistema è composto da 4 entità:
- processo mittente
- trasporto mittente
- trasporto destinatario
- processo destinatario
E abbia due casi di controllo di flusso:
processo mittente → trasporto mittente
trasporto destinatario → processo destinatario
Il livello trasporto del mittente segnala al livello applicazione di sospendere l’invio di messaggi quando ha il buffer saturo, quando si libera spazio nel buffer segnala al livello applicazione che può riprendere l’invio di messaggi.
Il livello trasporto del destinatario segnala al livello trasporto del mittente di sospendere l’invio di messaggi quando ha il buffer saturo, quando si libera spazio nel buffer segnala al livello trasporto mittente che può riprendere l’invio di messaggi.
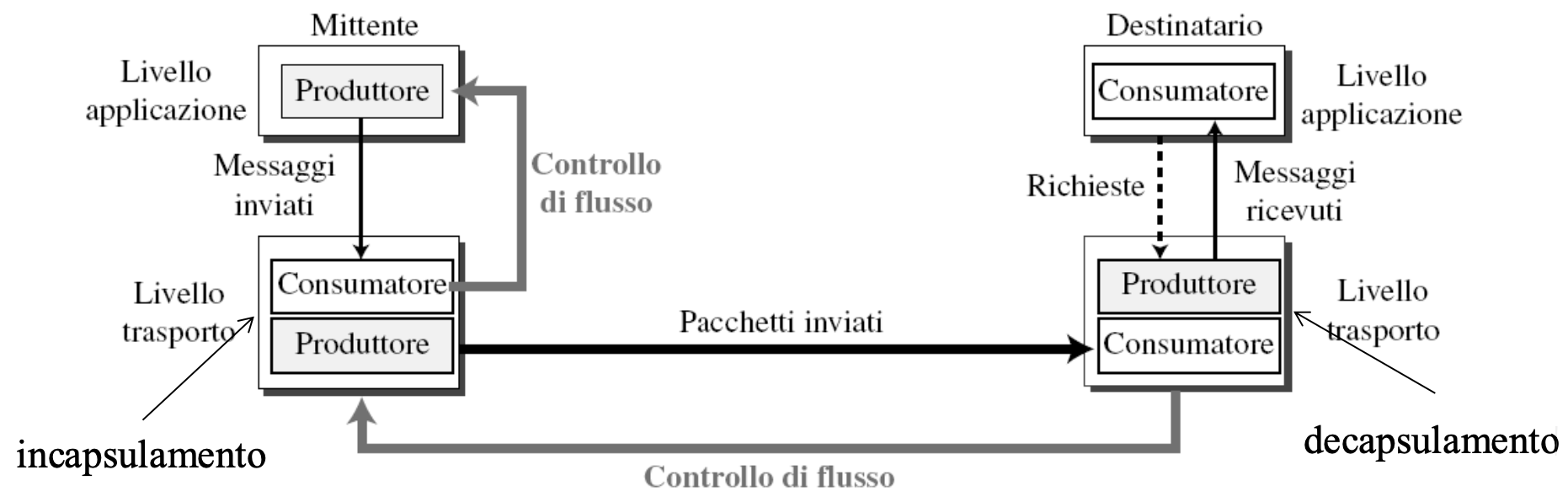
Controllo Errori
Dato che il livello di rete è inaffidabile, l’affidabilità va implementata a livello di trasporto e per farlo abbiamo bisogno di implementare un controllo degli errori che agisce sui pacchetti:
- Rilevare e scartare pacchetti corrotti
- Tracciare i pacchetti persi e il loro rinvio
- Riconoscere pacchetti duplicati
- Bufferizzare i pacchetti fuori sequenza finché non arrivano quelli mancanti
È il livello trasporto del destinatario a gestire il controllo errori e segnalarli al livello trasporto mittente.
Realizzazione
I pacchetti vengono numerati in modo sequenziale attraverso un campo nell’header.
Poiché il numero di sequenza va inserito nell’intestazione, va specificata la dimensione massima:
- Se l’intestazione prevede
mbit per il numero di sequenza questi possono assumere valori da a- I numeri di sequenza sono quindi considerati in modulo (ciclici)
Questo numero di sequenza serve al destinatario per:
- Capire la ordine dei pacchetti in arrivo
- Se ci sono pacchetti persi
- Se ci sono pacchetti duplicati
Ma il mittente come fa a capire che un pacchetto è andato perso?
- Il destinatario ad un ogni pacchetto ricevuto invia un ACK (acknowledgment) con il numero del pacchetto che ha ricevuto che funziona da notifica di ricezione.
Integrazione del controllo degli errori e controllo di flusso
Precedentemente abbiamo visto che:
- Il controllo del flusso richiede 2 buffer uno per il mittente e uno per il destinatario
- Il controllo degli errori richiede un numero di sequenza e dei messaggi ACK
É possibile combinare i due meccanismi tramite dei buffer numerati nel mittente e nel destinatario.
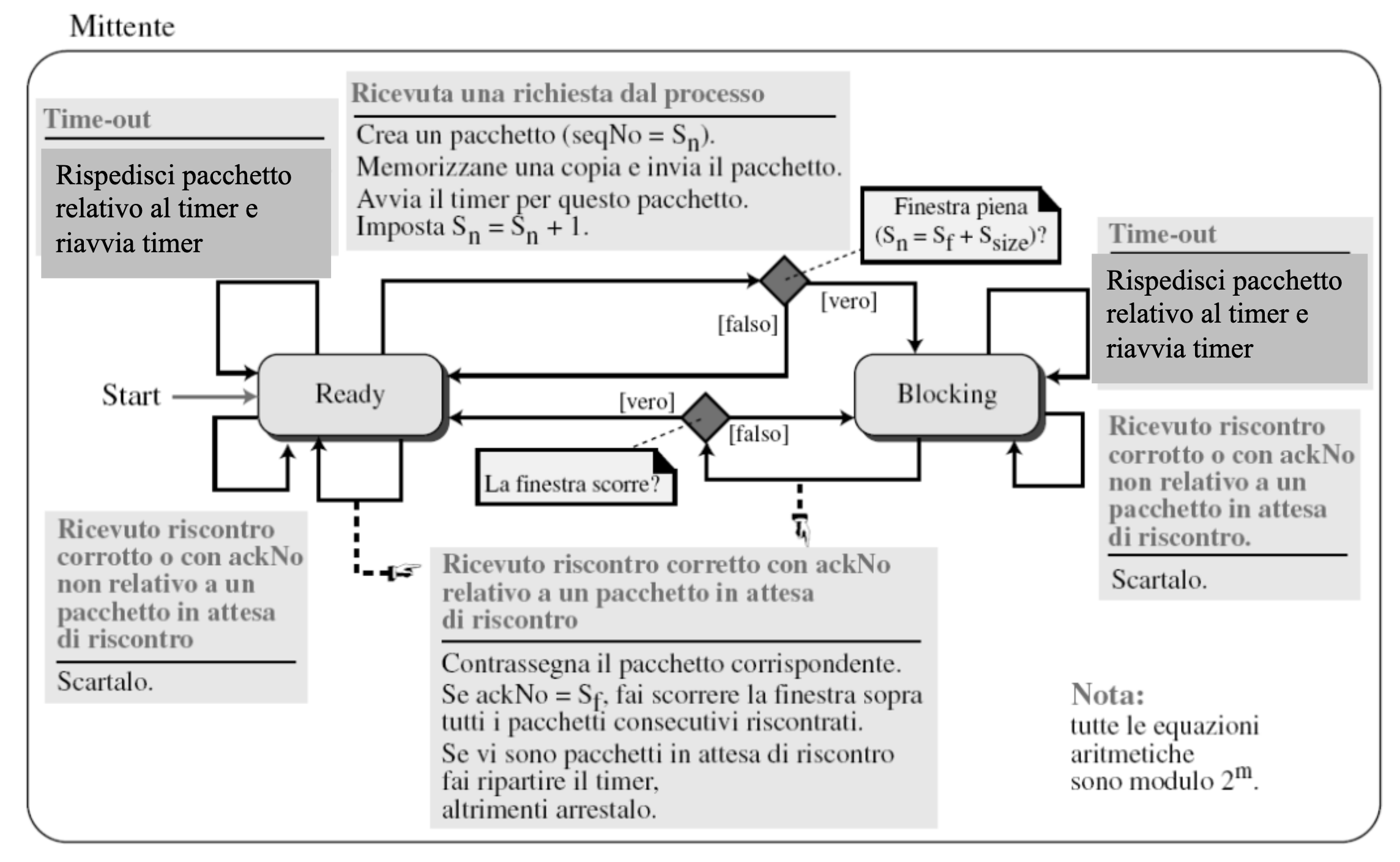
Il mittente:
- Quando prepara un pacchetto usa come come numero di sequenza il numero (
x) - Quando invia il pacchetto ne memorizza una copia nella locazione
xdel buffer - Quando riceve il segnale ACK di un pacchetto libera la posizione di memoria occupata da quel pacchetto
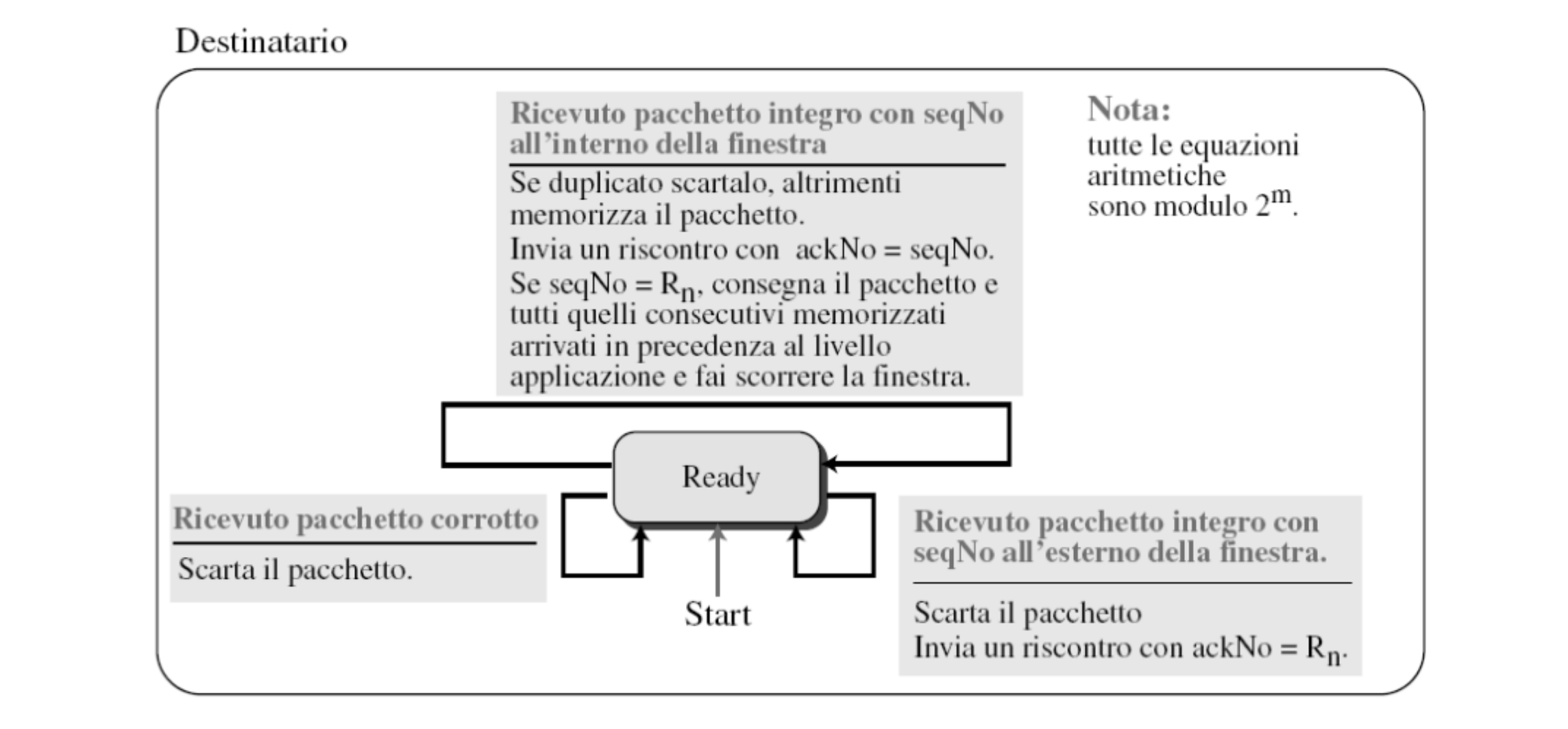
Il destinatario:
- Quando riceve un pacchetto con numero
ylo memorizza nella locazioneyfino a quando il livello applicazione non è pronto a riceverlo - Quando passa il pacchetto al livello applicazione invia ACK al mittente
Sliding Window
Dato che i numeri di sequenza sono calcolati in modulo e quindi ciclici possiamo rappresentarli tramite un cerchio. Il buffer viene rappresentato con un insieme di settori chiamati sliding windows che occupano una parte del cerchio.
Quindi finché il destinatario non svuota il suo buffer non vengono inviati nuovi pacchetti in modo da non sovraccaricare la rete.
Nella realtà per memorizzare i numeri di sequenza del prossimo pacchetto da inviare e dell’ultimo inviato si usano delle variabili e le sliding windows vengono rappresentate in modo lineare:
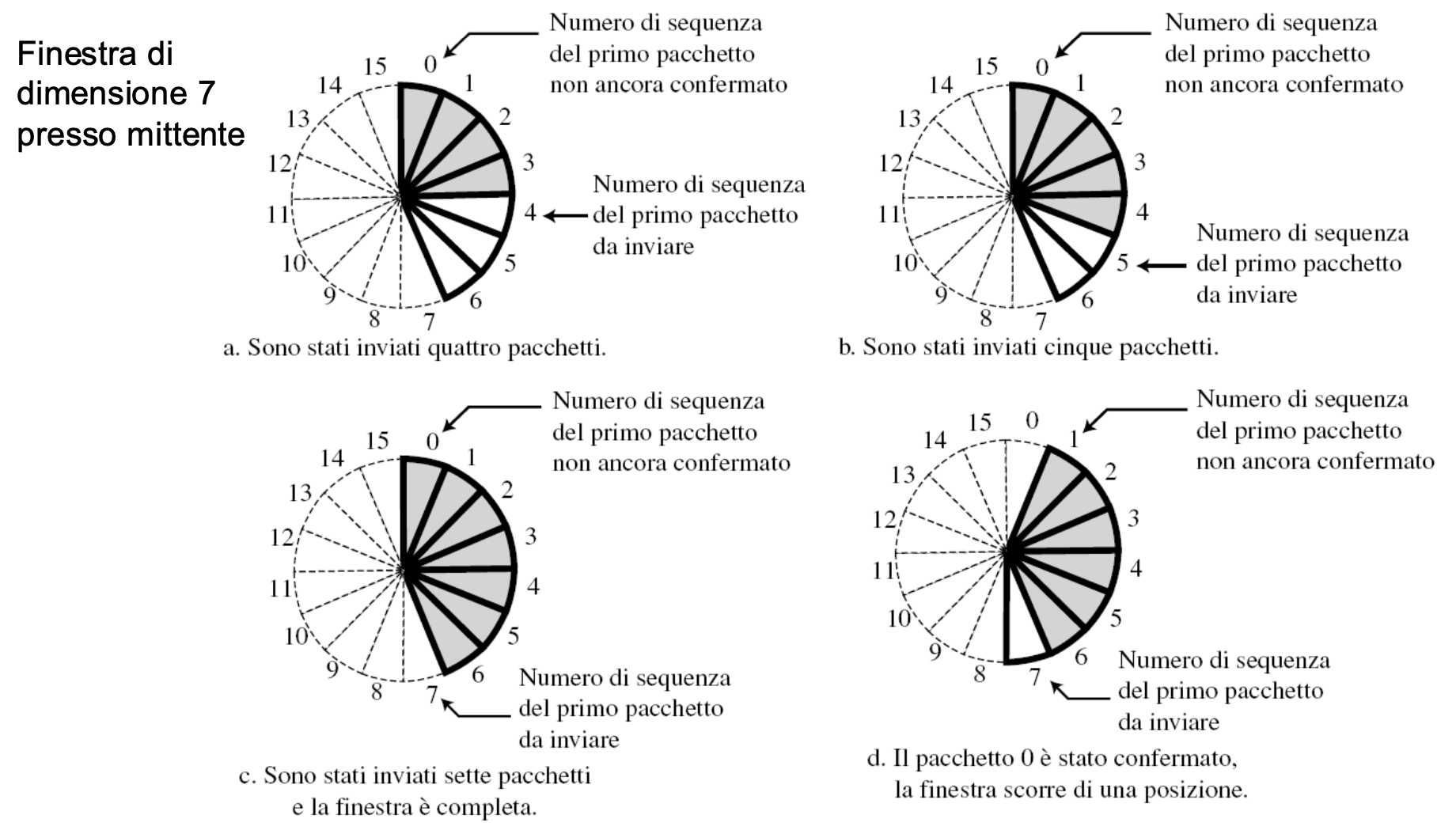

Controllo Congestione
Nella commutazione a pacchetto la congestione avviene se il carico della rete, ovvero il numero di pacchetti su di essa, è superiore alla sua capacità, con il controllo della congestione usiamo delle tecniche per fare in modo che questa situazione non si verifichi mai.
Si parla di congestione perché arrivano più pacchetti di quelli che router e switch riescono a gestire e quindi si riempiono le loro code portando alla perdita di pacchetti e rallentamenti.
Meccanismi
In questa lezione vediamo meccanismi (non protocolli) per implementare i controlli visti precedentemente:
Stop and Wait
In questo meccanismo sia il mittente che il destinatario hanno una finestra scorrevole di un solo pacchetto e permette di garantire:
- Controllo errori: Tramite il numero di sequenza dei pacchetti, l’ACK e Timer
- Controllo del flusso: Non è possibile inviare più di un pacchetto quindi non possono arrivare in ordine sparso.
Funzionamento
- Il mittente invia un pacchetto e attende il suo ACK prima di inviarne un’altro.
- Quando il pacchetto arriva, il destinatario calcola il suo checksum se:
- Pacchetto non è corrotto ⇒ invio ack al mittente
- Pacchetto corrotto ⇒ scartato senza informare il mittente
- Il mittente capisce che il pacchetto non è stato ricevuto correttamente tramite un timer:
- Scadenza timer senza ricevere ack ⇒ rinvio pacchetto
Questo significa che il mittente deve tenere una copia del pacchetto fino a che non riceve il suo ACK.
Gestione Duplicati
Per gestire i pacchetti duplicati lo stop and wait utilizza i numeri di sequenza, in questo caso bastano due valori
0e1.Quando viene ricevuto un pacchetto si invia un ACK con il numero di sequenza successivo, quindi se ricevo 0 invio ACK 1 e se ricevo 1 invio ACK 0, questo sta ad indicare qualche pacchetto sta aspettando.
FSM (finite state machine)
Quindi il mittente invia un pacchetto e aspetta un riscontro o la fine del timer prima di inviarne un altro.
Quindi il destinatario è sempre pronto a ricevere pacchetti e non va mai in stato di blocked.
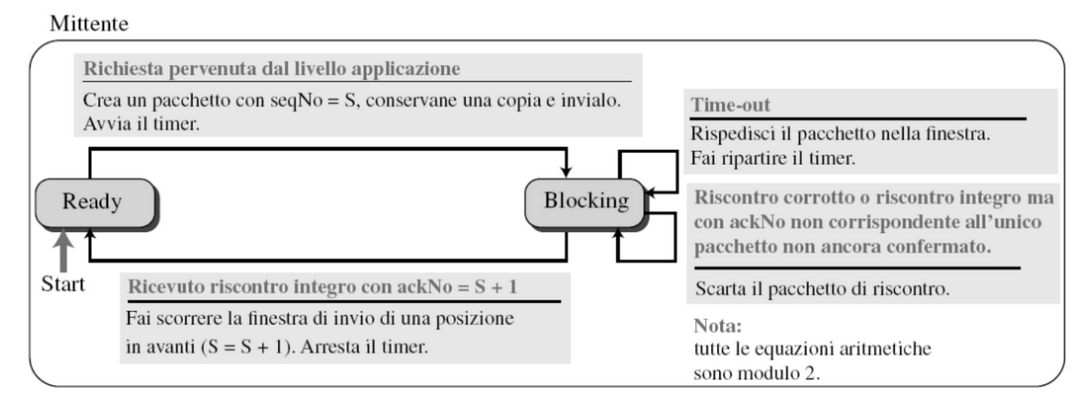
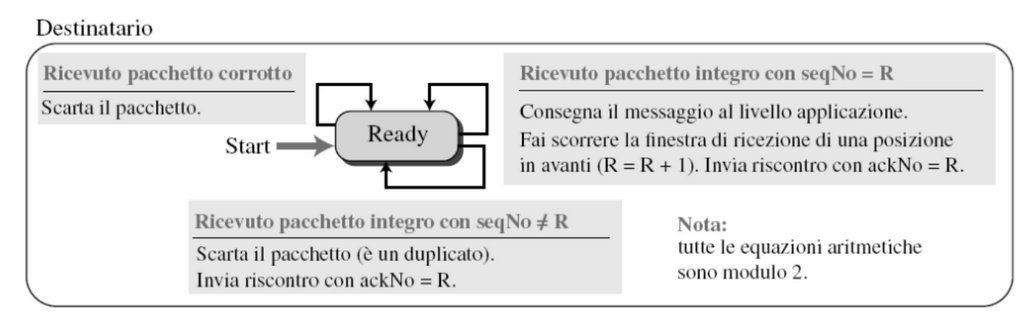
(In)efficenza
Questo meccanismo può essere particolarmente inefficiente quando abbiamo un rate elevato e ritardo consistente.
Prendiamo ad esempio un sistema che ha:
- Rate =
1Mbps- Ritardo di andata e ritorno di 1 bit =
20 msAbbiamo un valore di
rate * ritardo = 20'000 bit/msI pacchetti hanno dimensione
1000bitquindi significa che l’utilizzo del canale è1000 / 20000 = 5%dato che possiamo inviare un solo pacchetto alla volta. Abbiamo quindi una rete molto inefficiente.Soluzione: utilizziamo protocolli con pipeline, ovvero dove il mittente può inviare più di un pacchetto alla volta. Vediamo Go back N e Ripetizione selettiva
oss: modulo
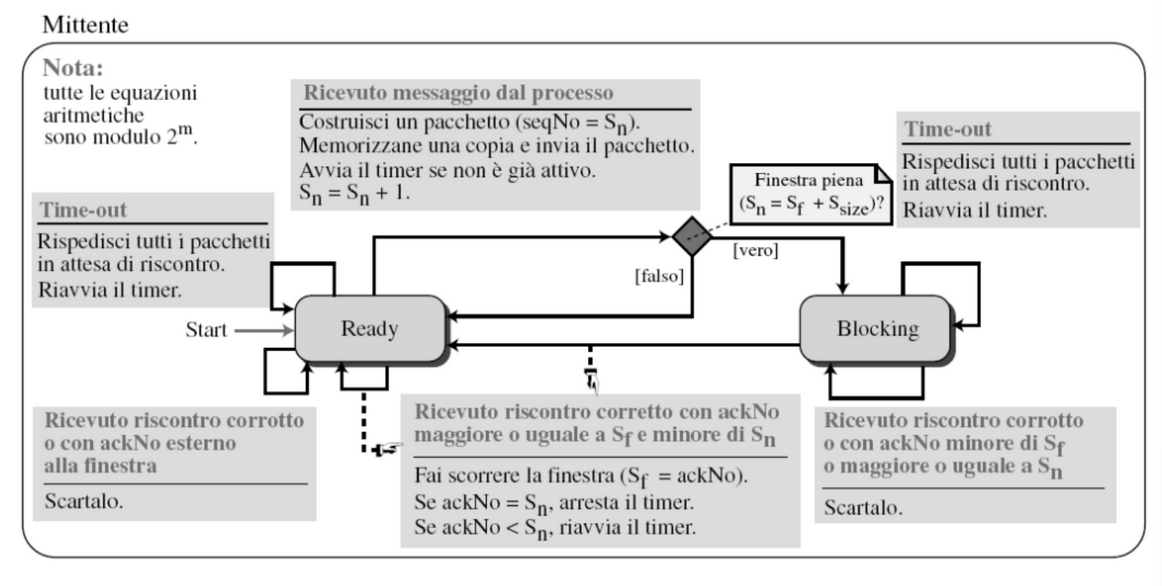
Go back N
In questo meccanismo i numeri di sequenza sono calcolati modulo dove è la dimensione del numero di sequenza in bit.
Anche con questo meccanismo gli ACK inviati contengono il numero che stiamo aspettando, la differenza è che qui usiamo un ACK cumulativo ovvero tutti i pacchetti fino al numero di sequenza indicato nell’ACK sono stati ricevuti correttamente.
Quindi se ACK = 7 significa che tutti pacchetti ricevuti con numero di sequenza minore uguale (<=) a 6 sono stati ricevuti correttamente e che si sta spettando il pacchetto 7.
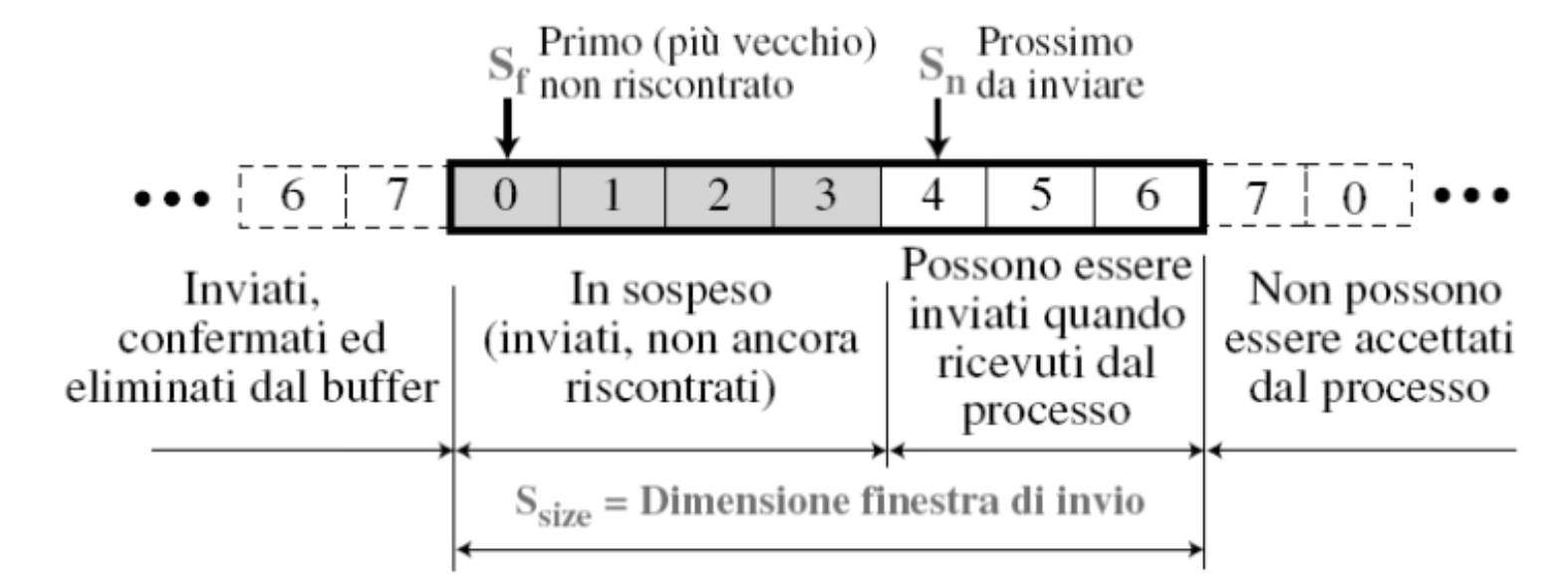
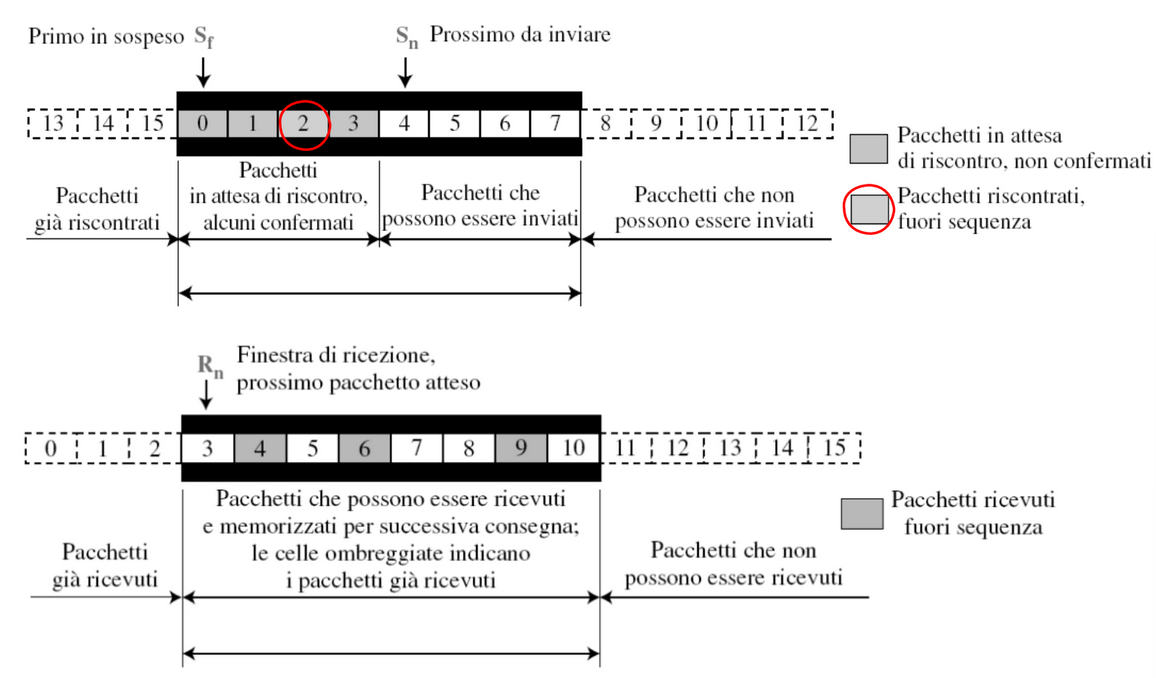
Finestra di Invio
La finestra di invio è un concetto astratto che definisce una porzione immaginaria di dimensione massima con tre variabili , , .
La finestra di invio può scorrere uno o più posizioni quando viene ricevuto un riscontro privo di errori con ack non maggiore o uguale a e, minore di in aritmetica modulare.
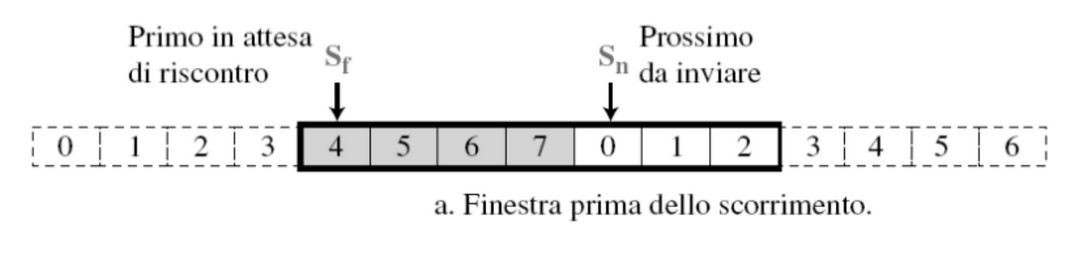
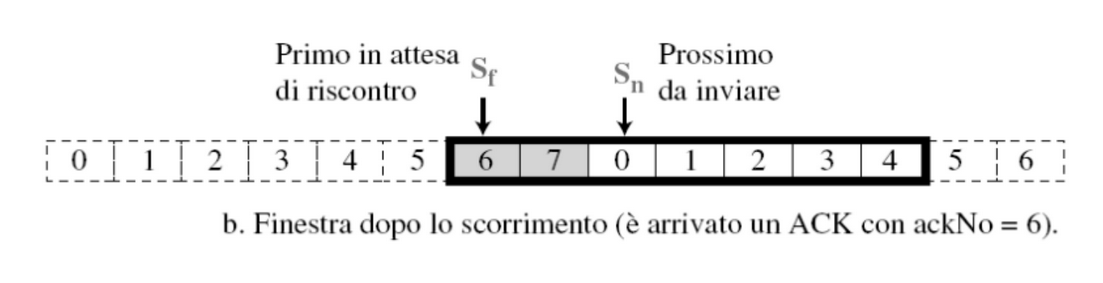
Esempio
Quindi se ad esempio arriva un ACK = 6
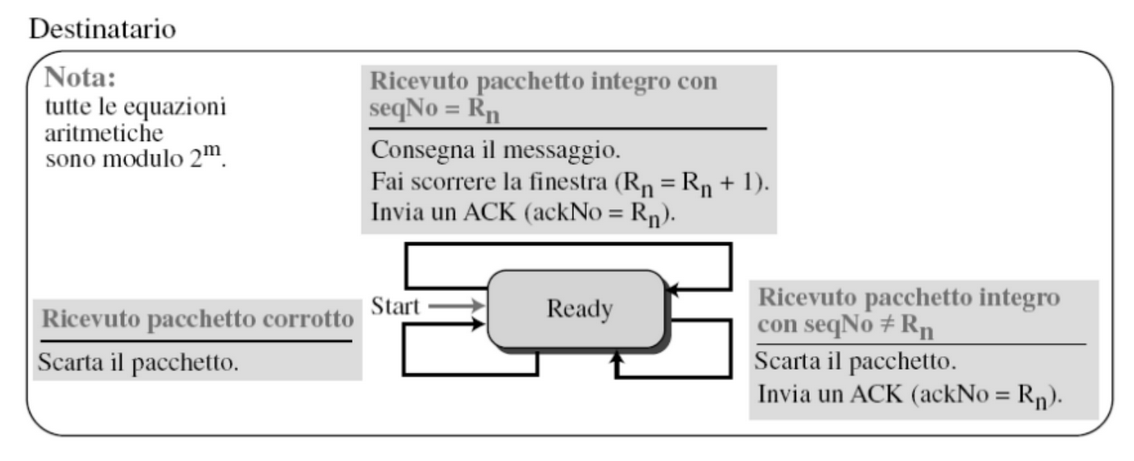
Finestra di Ricezione
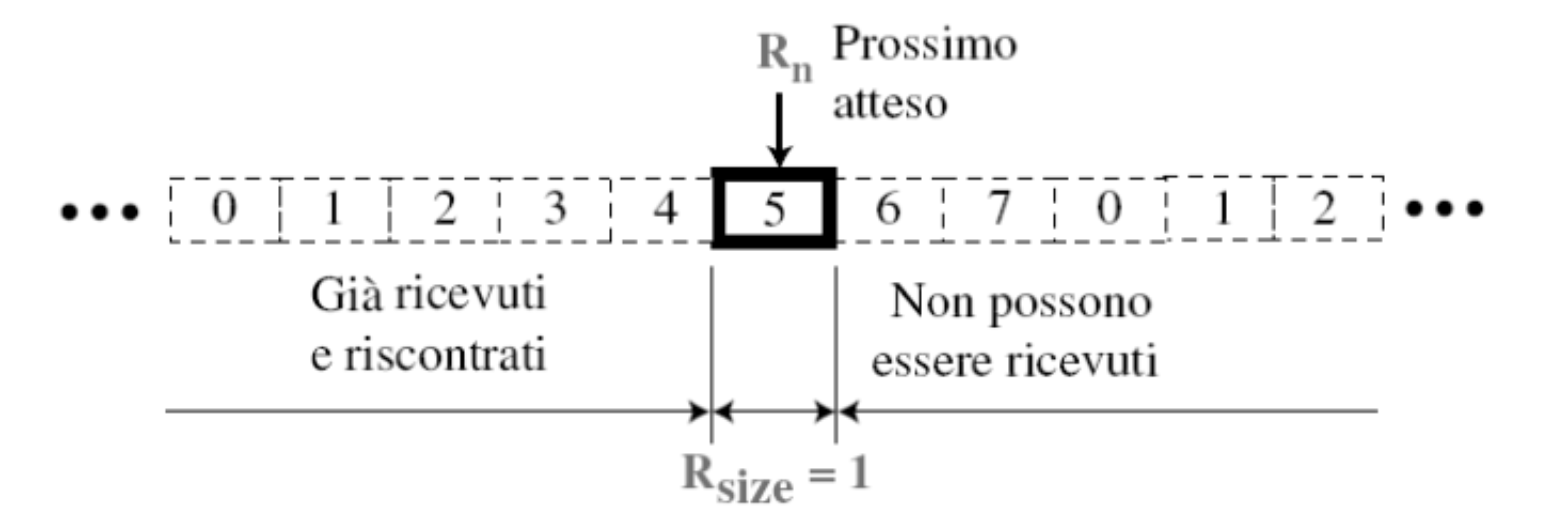
La finestra di ricezione ha dimensione
1per questo il destinatario è sempre in attesa di uno specifico pacchetto, e qualsiasi pacchetto arrivato fuori sequenza viene scartato.
Esempio: siamo in attesa di 5 ed arrivano 6 e 7 questi verranno scartati e dovranno essere rinviati successivamente.
Timer e Rispedizione
Il mittente mantiene un timer per il più vecchio pacchetto non riscontrato dove allo scadere del timer vengono rispediti tutti i pacchetti in attesa di riscontro (il destinatario ha finestra di ricezione pari a 1 e non può memorizzare i pacchetti fuori sequenza).
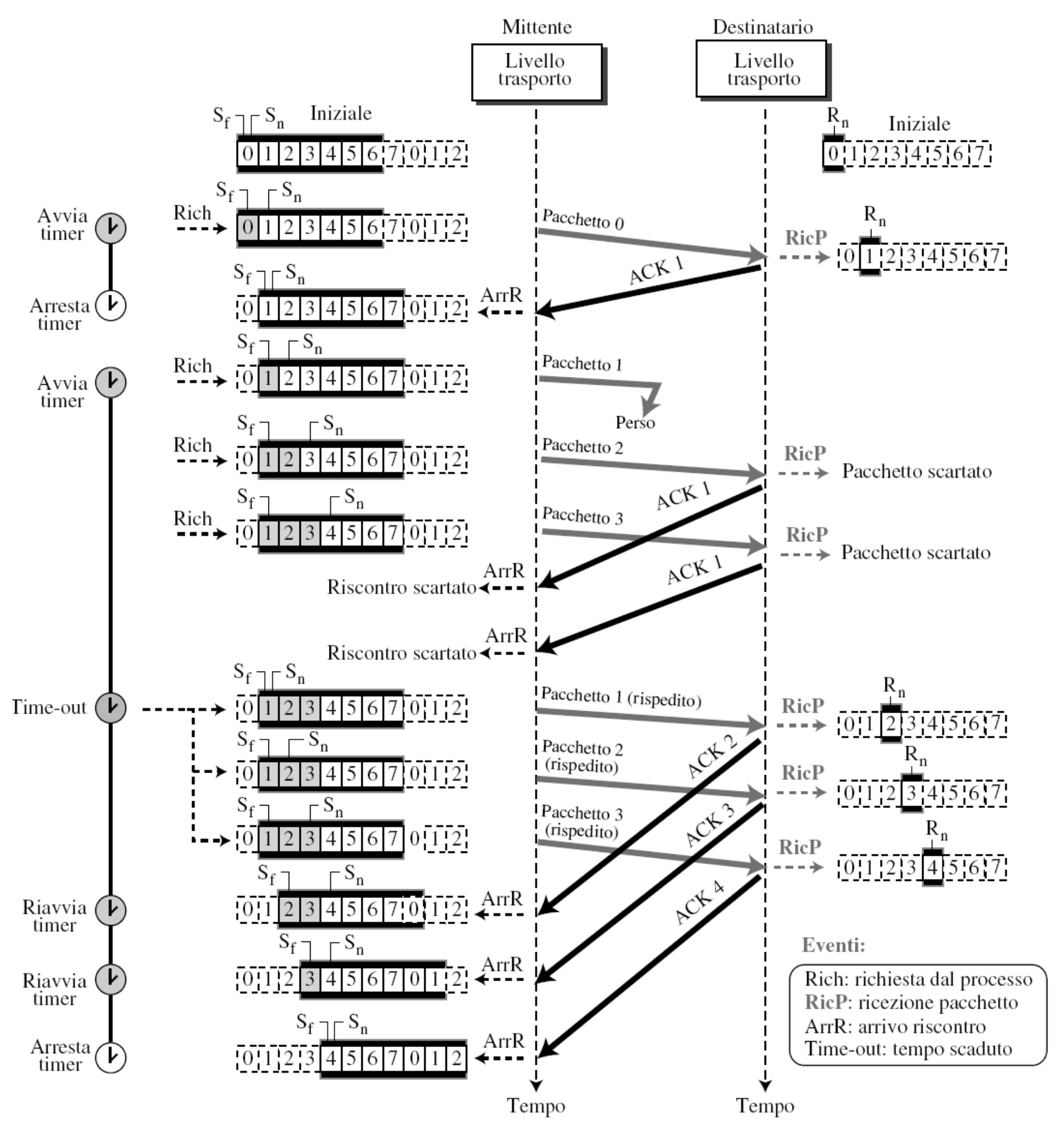
Esempio:
Sf = 3e il mittente ha inviato il pacchetto6(Sn = 7). Scade il timer, allora i pacchetti3,4,5,6non sono stati riscontrati e devono essere rispediti.
FSM (finite state machine)
In questo esempio gli ACK non vengono mai ricevuti dal mittente,
Esempio Funzionamento
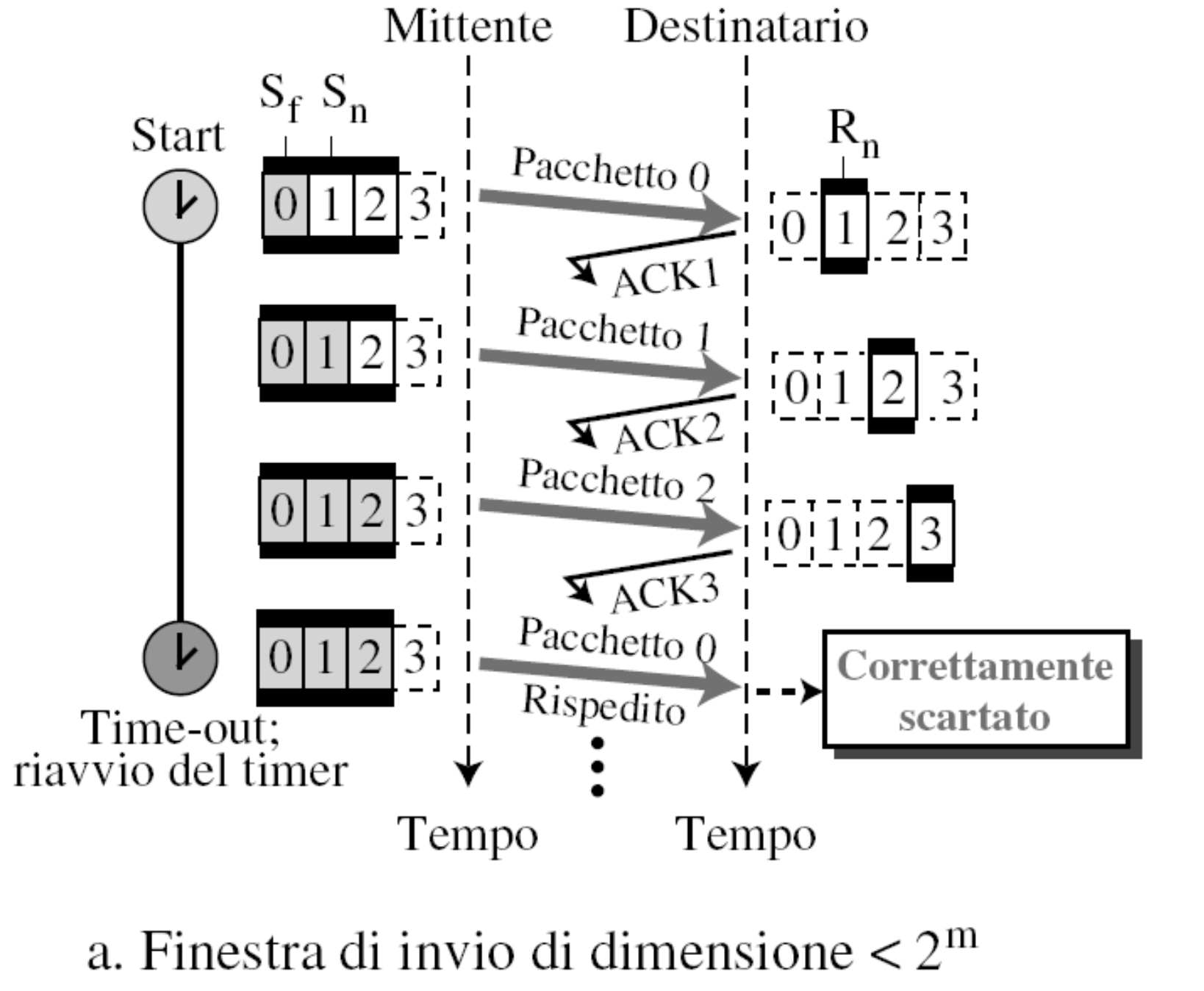
Perché Finestra di Invio < 2^m
La finestra di invio deve essere sempre minore di di , infatti se la finestra di scorrimento fosse troppo grande, il ricevitore potrebbe ricevere un pacchetto con un numero di sequenza che è già stato utilizzato in precedenza, ma che non è ancora stato confermato (ACK).
Esempio
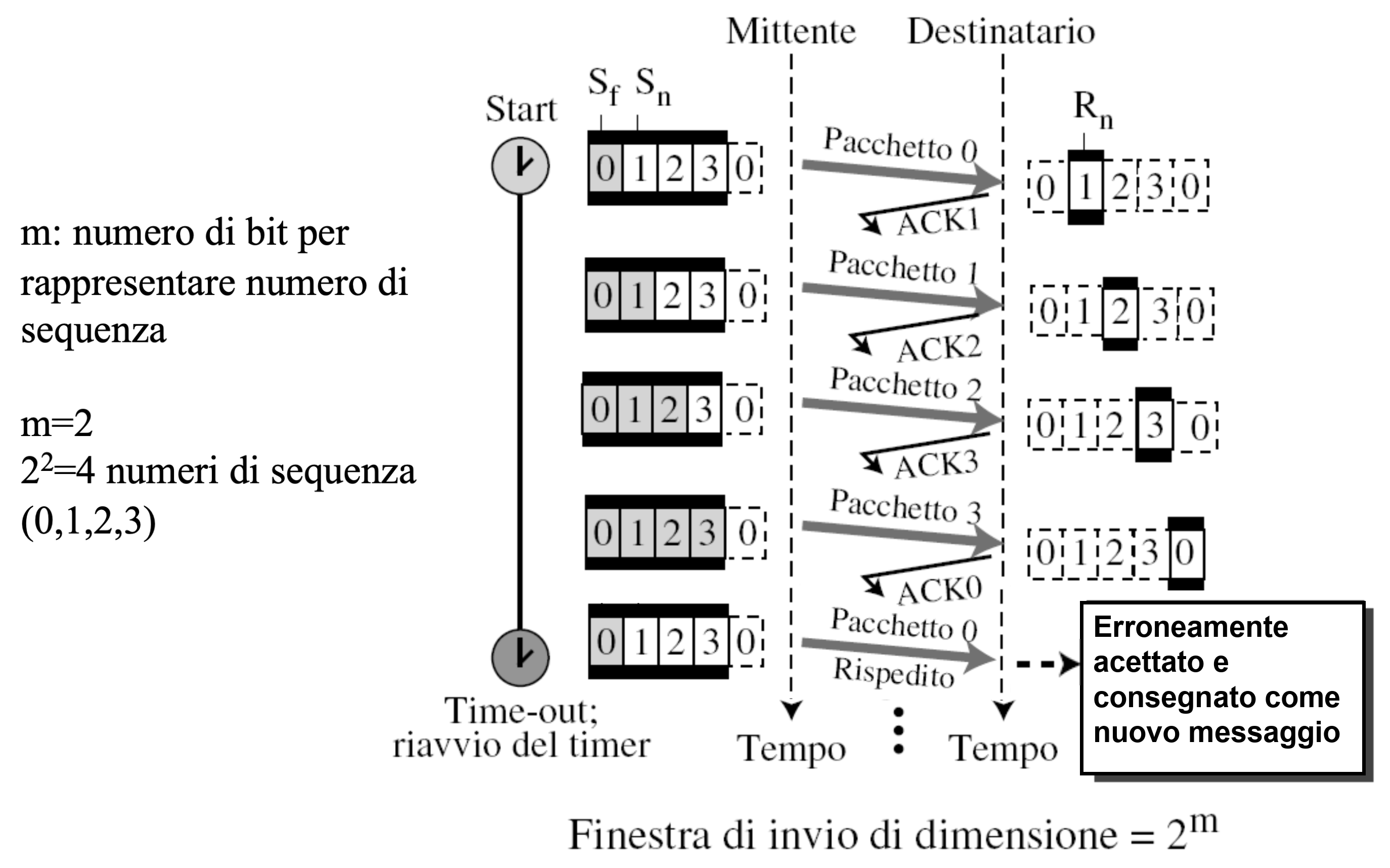
Selective Repeat
Come abbiamo visto, nel meccanismo Go back N quando un pacchetto non è ricevuto correttamente tutti i pacchetti presenti nella finestra vengono rinviati, e questo può portare a due problematiche:
- Non è efficiente rispedire cose che abbiamo erano già state spedite correttamente
- Se il motivo della non corretta ricezione dei pacchetti è dovuto ad una congestione della rete allora questo meccanismo va ad ulteriormente sovraccaricare il sistema.
Questi problemi sono risolti del meccanismo selective repeat (ripetizione selettiva), che permette di rispedire soltanto i pacchetti per i quali non è stato ricevuto un ACK.
Funzionamento
In questo meccanismo abbiamo che la finestra di invio e ricezione hanno la stessa dimensione.
In particolare non deve superare , leggi approfondimento dimensioni finestre per capire il perché.
Il mittente mantiene un timer specifico per ogni pacchetto inviato di cui non ha ancora ricevuto l’ACK e li rinvia se il timer scade.
Il ricevente invia un ACK specifico per ogni pacchetto che riceve correttamente e può anche memorizzare i pacchetti fuori sequenza.
oss: se
ACK = 7non significa più che stiamo aspettando il 7 e abbiamo ricevuto il 6 ma significa che abbiamo ricevuto correttamente il 7.
Finite State Machine
Approfondimento dimensione finestre
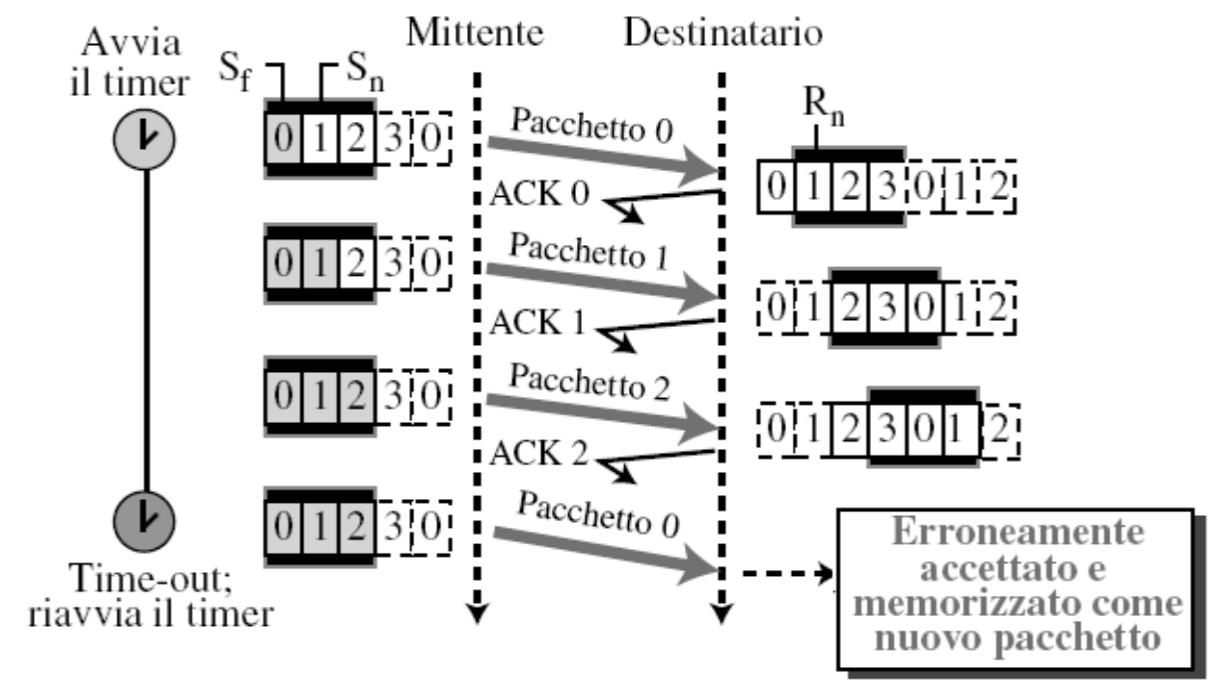
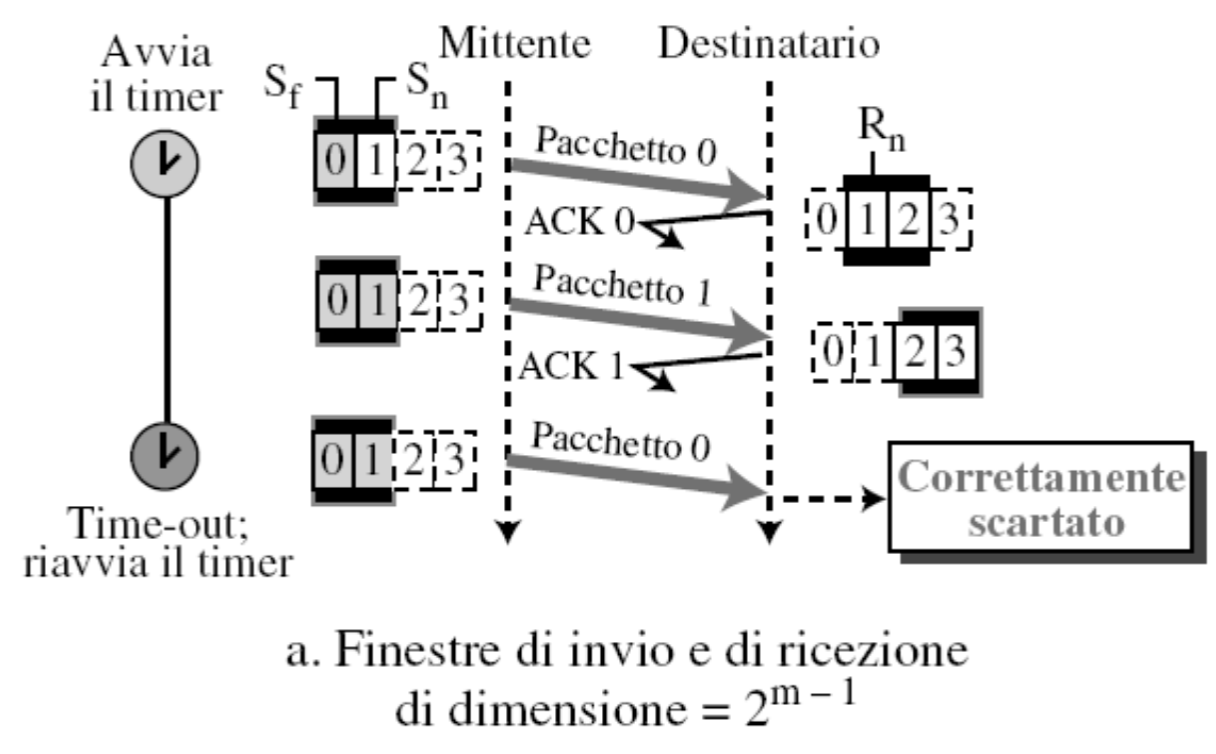
Le dimensione delle finestre abbiamo detto essere uguali e in questo meccanismo sono calcolate modulo .
Perché non possiamo usare ?
In questo caso scade il timer per
0e viene rispedito, il destinatario lo prende come nuovo pacchetto ma in realtà è un duplicato.Se usiamo :
Altro
Protocolli Bidirezionali: Piggybacking
I meccanismi che abbiamo visto li abbiamo presentati in modo unidirezionale ovvero i pacchetti vengono spediti in una direzione e gli ACK in un’altra ma in realtà questi viaggiano in entrambe le direzioni, sia pacchetti che ACK. Per migliorare l’efficienza dei protocolli bidirezionali si usa la tecnica piggybacking ovvero quando un pacchetto trasporta dati da A a B può trasportare anche gli ACK relativi ai pacchetti ricevuti da B e viceversa.