Introduzione alla Memoria Distribuita con Libreria MPI (MPI_Recv, MPI_Send)
9 min read
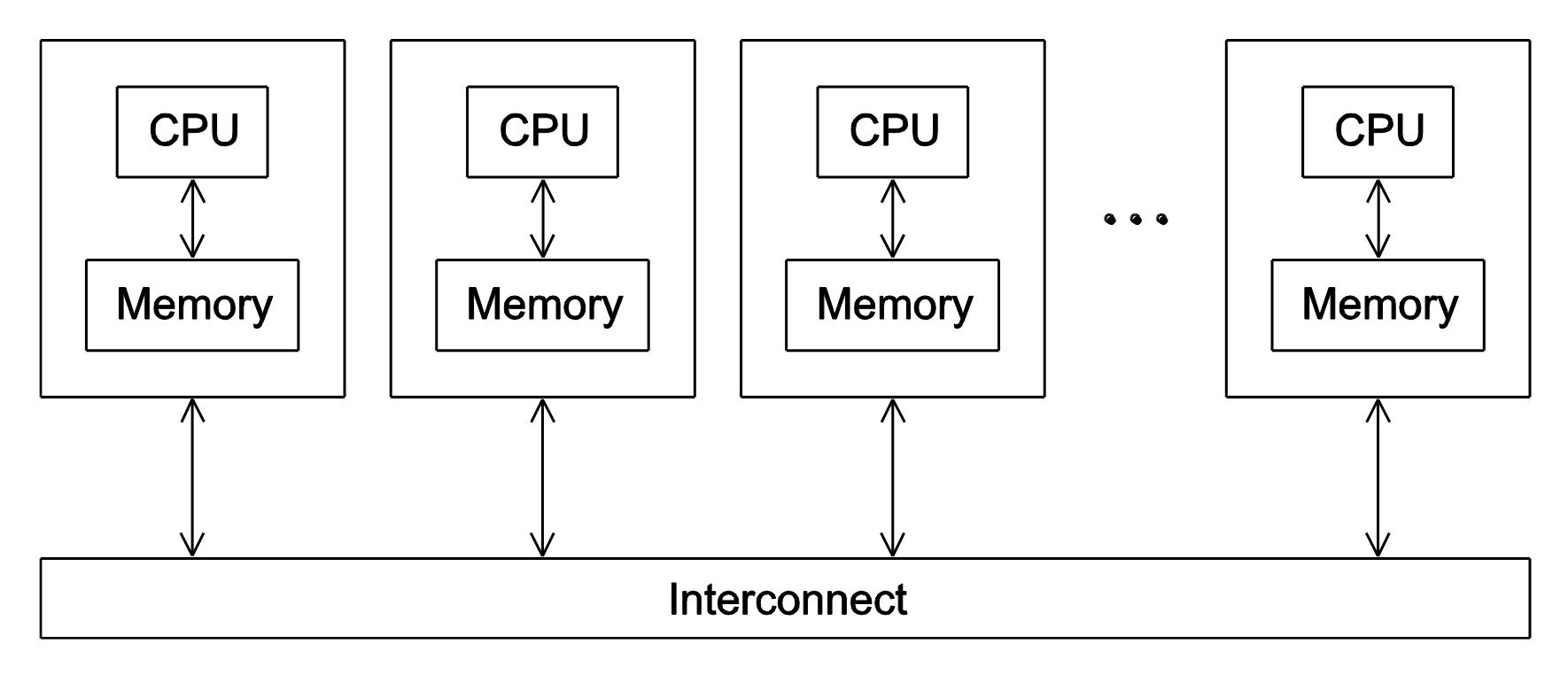
Sistemi a memoria distribuita
I sistemi a memoria distribuita sono composti da più processori, ognuno con la propria memoria “privata” inaccessibile dall’esterno. Dato che le CPU non condividono la memoria, la comunicazione avviene attraverso l’invio di messaggi, una rete di interconnessione.
Questa rete può essere sia interna alla macchina (bus), che collega direttamente i vari processori, oppure potrebbe anche essere una rete cablata se si parla di sistemi composti da più macchine.
Libreria MPI
MPI è una libreria standard (avente varie implementazioni) necessaria allo sviluppo di codice multi-processo a memoria distribuita. In particolare in questo corso utilizziamo OpenMPI, un implementazione open source, scritta in C.
Single-Program Multiple-Data (SPMD)
Questa libreria standard si basa sul principio Single-Program Multiple-Data, ovvero si scrive e compila un singolo programma che viene eseguito su più processori contemporaneamente.
Si utilizzando gli if/if-esle per specificare cosa ogni deve fare.
– If I am process number 0, do X
– If I am process number 1, do Y
– etc...
OpenMPI “Hello World”
Il codice seguente è un esempio di programma MPI che stampa un messaggio “hello world” su più unità di calcolo:
#include <stdio.h>#include <mpi.h>// Voglia lanciare il programma su più processoriint main(int argc, char** argv) { int p = MPI_Init(NULL, NULL); if (p != MPI_SUCCESS) { printf("qualcosa è andato storto"); MPI_Abort(MPI_COMM_WORLD, p); // Con MPI_Abort tutti i processi su tutti i core avviati verranno terminati } printf("hello world"); MPI_Finalize(); // Serve per terminare la libreria return 0;}
Nota: Da notare che ogni funzione/variabile della libreria MPI inizia sempre con MPI_.
l primo passo per costruire un programma MPI è includere i file di intestazione MPI con #include <mpi.h>, e ogni funzione di libreria deve essere chiamata tra:
MPI_Init - configurazione ed avviamento della libreria
MPI_Finalize - chiusura e deallocazione della memoria
MPI_Init
MPI_Init(int* argc, char*** argv)
Durante MPI_Init, tutte le variabili globali e interne di MPI vengono costruite. Ad esempio, viene formato un comunicatore attorno a tutti i processi che sono stati avviati e vengono assegnati ranghi univoci (rank) a ciascun processo.
Attualmente, MPI_Init accetta due argomenti int* argc e char*** argv, che non sono obbligatori (possono anche essere impostati a NULL).
MPI_Finalize
MPI_Finalize()
Utilizzato per pulire l’ambiente MPI. Non è possibile effettuare altre chiamate MPI dopo questa.
Compilazione ed esecuzione
I programmi MPI non vengono compilati con gcc , ma con mpicc, ad esempio: mpicc hello_world.c -o hello_world.out.
Una volta ottenuto l’eseguibile, è possibile lanciare il programma con mpirun specificando il numero di core sulla quale verrà eseguito il programma, tale numero, se non specificato con apposite flag, deve essere minore o uguale al numero di core fisici presenti sulla macchina, ad esempio: mpirun -n 4 hello_world.out.
Rank e Comunicatore
Un comunicatore è una struttura a cui viene associato un insieme di processi, i quali hanno la possibilità di scambiarsi messaggi.
Avvio di MPI, attraverso MPI_Init() viene sempre definito un comunicatore di default MPI_COMM_WORLD che contiene tutti i processi.
MPI_Comm_size
MPI_Comm_size(MPI_Comm communicator, int* size)
MPI_Comm_size prende in input un comunicatore ed un puntatore ad intero, e restituisce (salvando nell’intero puntato) la dimensione del comunicatore, ovvero il numero di processi che connette.
MPI_Comm_rank
MPI_Comm_rank(MPI_Comm communicator, int* rank)
MPI_Comm_rank prende in input un comunicatore ed un puntatore ad intero, e restituisce (salvando nell’intero puntato) il rango del processo nel comunicatore.
Infatti, durante la fase di inizializzazione, a ciascun processo all’interno di un comunicatore viene assegnato un rango incrementale a partire da zero. I ranghi dei processi vengono utilizzati principalmente per scopi di identificazione durante l’invio e la ricezione di messaggi.
Esempio:
#include <stdio.h>#include <mpi.h>int main(int argc, char **argv) { int ierr; // Initialize MPI ierr = MPI_Init(NULL, NULL); if (ierr != MPI_SUCCESS) { fprintf(stderr, "MPI_Init failed with error code %d\n", ierr); MPI_Abort(MPI_COMM_WORLD, ierr); } // Get communicator size and rank int size; MPI_Comm_size(MPI_COMM_WORLD, &size); int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); // Print message printf("hello world, I'm process %d/%d\n", rank, size); // Finalize MPI MPI_Finalize(); return 0;}
Comunicazione tra processi
La comunicazione tra i processi di uno stesso comunicatore avviene attraverso due principali funzioni MPI_Send e MPI_Recive.
MPI_Send
int MPI_Send(const void *send_buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
Dove i parametri in input sono:
void* send_buf: puntatore all’inizio del buffer (area di memoria) che contiene il messaggio da inviare
int count: numero di elementi contenuti nel send_buf (intero non negativo)
MPI_Datatype datatype: tipo di elemento da trasferire (usa i datatype di MPI)
int dest: rank del processo destinatario
int tag: un tag da dare al messaggio per identificarlo
MPI_Comm communicator: comunicatore su cui avviene la comunicazione
MPI_Recive
int MPI_Recv(void *recv_buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
void *recv_buf: puntatore all’inizio del buffer di ricezione dove verranno copiati i dati ricevuti
int count: numero massimo di elementi che possono essere ricevuti
MPI_Datatype datatype: tipo di dati che verrano ricevuti (usa i datatype di MPI)
int source: rank del processo mittente, per ricevere da qualsiasi mittente utilizzare MPI_ANY_SOURCE
tag: etichetta del messaggio da ricevere, per ricevere qualsiasi messaggio indipendentemente dall’etichetta, utilizzare MPI_ANY_TAG
comm: comunicatore su cui avviene la comunicazione
status: punta ad un area di memoria in cui verrà salvato l’MPI_Status (esito della comunicazione)
MPI Data Types
OpenMpi definisce i seguenti di tipi con MPI_Datatype:
MPI datatype
C datatype
MPI_CHAR
signed char
MPI_SHORT
signed short int
MPI_INT
signed int
MPI LONG
signed long int
MPI LONG LONG
signed long long int
MPI_UNSIGNED_CHAR
unsigned char
MPI_UNSIGNED_SHORT
unsigned short int
MPI UNSIGNED
unsigned int
MPI_UNSIGNED_LONG
unsigned long int
MPI_FLOAT
float
MPI_DOUBLE
double
MPI_LONG_DOUBLE
long double
MPI BYTE
MPI_PACKED
^b38a1a
Esempio:
#include <stdio.h>#include <mpi.h>int main(int argc, char **argv) { int ierr; // Initialize MPI ierr = MPI_Init(NULL, NULL); if (ierr != MPI_SUCCESS) { fprintf(stderr, "MPI_Init failed with error code %d\n", ierr); MPI_Abort(MPI_COMM_WORLD, ierr); } int size; MPI_Comm_size(MPI_COMM_WORLD, &size); int str_size = 256; int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); if (rank == 0) { printf("Hello world, I am process 0. I will receive and print.\n"); char str[str_size]; for (int i = 1; i < size; i++) { MPI_Recv(str, str_size, MPI_CHAR, i, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("(STRING RECIVED): %s", str); } } else { char str[str_size]; sprintf(str, "Hello world, I am process %d of %d\n", rank, size); MPI_Send(str, str_size, MPI_CHAR, 0, 0, MPI_COMM_WORLD); } MPI_Finalize(); return 0;}
Quando un processo esegue una MPI_Recv, fra i vari messaggi, viene cercato quello di cui matchano il tag, il comunicatore, ed il mittente, lo scopo del tag è quello di essere un ulteriore separatore logico per la comunicazione. Anche i tipi dei messaggi devono combaciare, inoltre il numero di byte da ricevere deve essere maggiore o uguale al numero di byte inviati
ByteRecv≥ByteSent
Nella chiamata MPI_Recv, i campi source e tag possono essere riempiti con, rispettivamente, MPI_ANY_SOURCE e MPI_ANY_TAG per non eseguire il controllo su mittente e tag nel ricevimento. È comunque possibile sapere qual’è il mittente, dato che tale informazione è salvata nel campo MPI_Status.
Svantaggi di MPI_Send
L’utilizzo di una MPI_Send è dispendioso dal punto di vista computazionale, in quanto sono
coinvolte operazioni di scrittura e chiamate di sistema, è quindi buona regola, eseguire il minor numero di MPI_Send possibile.
In particolare dato che MPI_Send ha dei costi fissi relativamente alti, è conveniente raggruppare molteplici messaggi più piccoli in un unica operazione MPI_Send.
Inoltre MPI_Send può comportarsi in modo bloccante o non in base alla grandezza del buffer di invio, in particolare se il messaggio da trasferire è:
piccolo, è probabile che venga immediatamente trasferito venendo salvato su un buffer del destinatario
grande, la chiamata sarà bloccante in quanto MPI deve assicurarsi che il destinatario abbia allocato la memoria sufficiente per riceverlo
In entrambi i casi, MPI si assicura che il messaggio da inviare non vada perso, il programma riottiene il
controllo solo quando il buffer utilizzato per contenere il messaggio è di nuovo disponibile, si dice che la MPI_Send è locally blocking.
Oltre la comunicazione standard, vi sono altri modi di inviare messaggi:
Buffered: Tramite la chiamata MPI_Bsend, l’operazione è sempre locally blocking, ma l’utente deve fornire manualmente un buffer in cui salvare il messaggio da inviare.
Sincrona: Tramite la chiamata MPI_Ssend, l’operazione è globalmente bloccante, il controllo viene restituito esclusivamente quando il destinatario ha ricevuto il messaggio chiamando MPI_Recv. Risulta utile per far si che un processo attenda che un altro arrivi ad un certo punto della computazione.
Ready: Tramite la chiamata MPI_Rsend, se il destinatario non ha già effettuato una MPI_Recv, tale chiamata fallisce, è quindi necessario che esso sia già in attesa di ricevere.
Svantaggi MPI_Recv
MPI_Recv è sempre bloccante, questo significa che quando un processo chiama MPI_Recv per ricevere un messaggio, si blocca fino a quando non riceve effettivamente il messaggio.
MPI Send e Recv non bloccanti (immediate)
Le chiamate MPI_Recv e MPI_Send sono considerate poco performanti in quanto potrebbero bloccare l’esecuzione, in alcuni casi può essere utile una chiamata non bloccante per la trasmissione dei dati, soprattutto quando il mancato ricevimento di essi non causa errori nell’esecuzione del programma.
Le funzioni non bloccanti messe a disposizione da MPI sono dette funzioni immediate, e permettono l’overlap fra computazione e comunicazione. Se al momento di una chiamata di ricevimento
non ci sono dati da leggere, il programmatore dovrà gestire esplicitamente la situazione.
MPI_Isend
La chiamata MPI_Isend ha gli stessi parametri della funzione non immediata, eccetto un parametro aggiuntivo, MPI_Request *req , necessario per avere informazioni sullo status della chiamata.
MPI_Irecv
La chiamata MPI_Irecv ha gli stessi parametri della funzione non immediata, eccetto per l’assenza del parametro sullo status originario, e l’aggiunta del parametro MPI_Reques *req, necessario per avere informazioni sullo status della chiamata.
MPI_Wait
La funzione int MPI_Wait(MPI_Request *request, MPI_Status *status) fa si che il processo si blocchi finché un invio o una ricezione non è andato a buon termine. È una chiamata bloccante.
MPI_Test
La funzione int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) controlla se una chiamata di invio o ricezione è andata o no a buon fine, salvando l’esito del risultato nel campo flag .
Esistono altre varianti di Wait e Test
• Waitall
• Waitany
• Testany
• etc…
Loop con chiamate non bloccanti (MPI)
Esempio Loop con chiamate non bloccanti
Il seguente esempio mostra un programma in cui n processi (in questo caso 4) si scambiano informazioni in una configurazione “ad anello”, in cui ognuno invia e riceve a/da i suoi vicini, l’utilizzo di chiamate non bloccanti è utile per evitare situazioni di deadlock.
#include "mpi.h"#include "stdio.h"int main(int argc, char *argv[]) { int num_task, rank, next, prev, buf[2], value_to_send; MPI_Request reqs[4]; MPI_Status stats[4]; MPI_Init(NULL, NULL); MPI_Comm_size(MPI_COMM_WORLD, &num_task); MPI_Comm_rank(MPI_COMM_WORLD, &rank); // Calculation of neighbors in the ring prev = (rank - 1 + num_task) % num_task; next = (rank + 1) % num_task; // Each process sends rank * 10 value_to_send = rank * 10; // Non-blocking communication with neighbors MPI_Irecv(&buf[0], 1, MPI_INT, prev, 0, MPI_COMM_WORLD, &reqs[0]); MPI_Irecv(&buf[1], 1, MPI_INT, next, 0, MPI_COMM_WORLD, &reqs[1]); MPI_Isend(&value_to_send, 1, MPI_INT, prev, 0, MPI_COMM_WORLD, &reqs[2]); MPI_Isend(&value_to_send, 1, MPI_INT, next, 0, MPI_COMM_WORLD, &reqs[3]); // --- Do computation here to overlap with communication --- int result = 0; for (int i = 0; i < 1000000; ++i) { result += rank * i; // Example: simulate computational work } // --------------------------------------------------------- // Wait for all non-blocking communications to finish MPI_Waitall(4, reqs, stats); // Print received values printf("Process %d received %d from prev (rank %d), %d from next (rank %d)\n", rank, buf[0], prev, buf[1], next); MPI_Finalize(); return 0;}
Output
Dopo aver eseguito il codice con mpirun -np 4 ./a.out, otteniamo in output:
Process 2 received 10 from prev (rank 1), 30 from next (rank 3)Process 0 received 30 from prev (rank 3), 10 from next (rank 1)Process 3 received 20 from prev (rank 2), 0 from next (rank 0)Process 1 received 0 from prev (rank 0), 20 from next (rank 2)
Nota
In questo esempio mostriamo anche che, grazie all’utilizzo delle chiamate non bloccanti MPI_Irecv e MPI_Isend, è possibile effettuare operazioni di calcolo tra l’avvio della comunicazione e la sincronizzazione finale (MPI_Waitall). In questo modo si può sovrapporre comunicazione e calcolo, ottimizzando l’efficienza del programma parallelo.