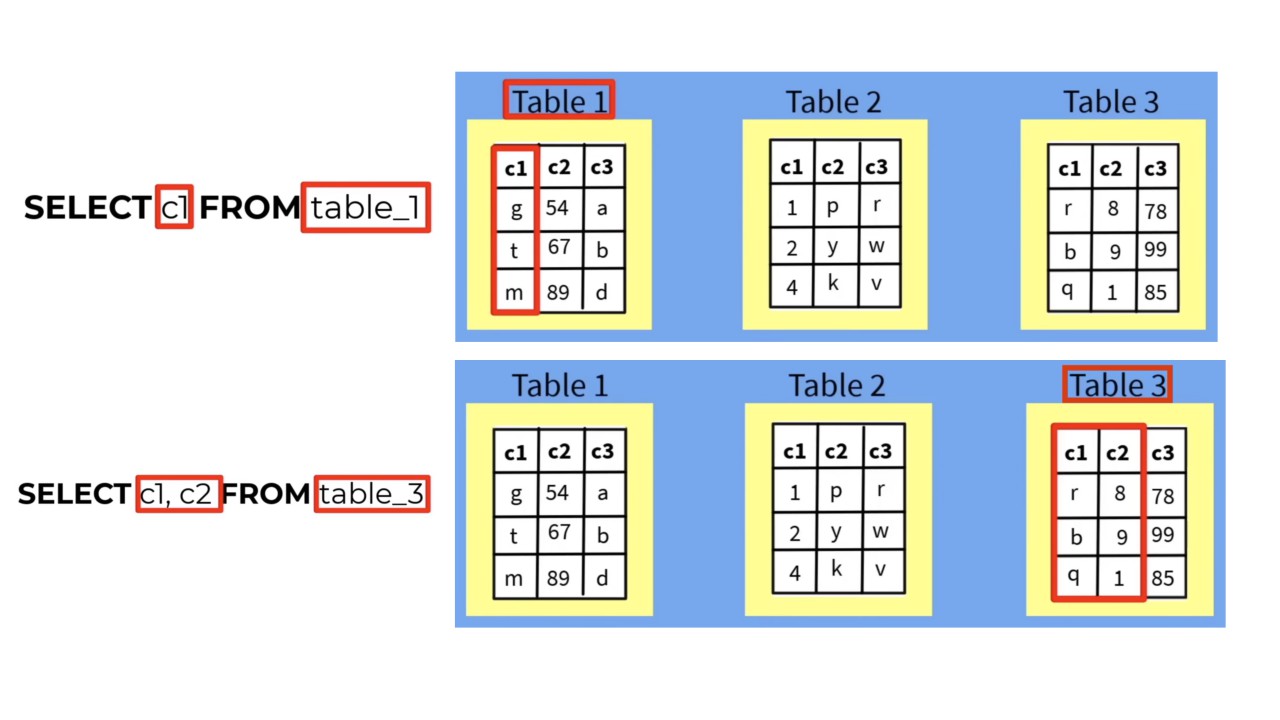
The SELECT statement is used to retrieve data from one or more database tables. It allows you to specify:
the columns you want to retrieve,
the table(s) from which you want to retrieve the data
and also, any conditions that must be met for the data to be included in the result set.
This statement can be combined with others to perform more complex queries.
Sintax
SELECT [columns] FROM [tables] WHERE [conditions]
Note:* con be use in [columns] to select all the columns form the specified tables.
Example
Insight
The result of a SELECT statement in SQL is a result set. This result set can be thought of as a temporary table, but it’s not stored in the database and doesn’t have a name.
This result set can be manipulated as a table using other operation such as WHERE, GROUP BY, ORDER BY, and more.
DISTINCT
The DISTINCT statement is used to remove duplicate rows from a result set.
It’s used to select only one row from a set of rows that have the same values in the specified columns.
SELECT DISTINCT ON (customer_id) customer_id, payment_date, amountFROM payment;
Usually DISTINCT ON is used with an ORDER BY statement to control which row is selected, for example:
SELECT DISTINCT ON (customer_id) customer_id, payment_date, amountFROM paymentORDER BY payment_date DESC;
ORDER BY payment_date DESC sorts the rows in descending order based on the payment_date, so the most recent payments are at the top.
SELECT DISTINCT ON (customer_id) selects only one row per distinct customer_id. The ON clause specifies that the distinctness should be determined based on the customer_id column.
So the result is the most recent payment for each customer.
Example
For example, if the payment table contains the following data:
The WHERE clause is typically used in combination with the SELECT statement to filter rows based on specific conditions. The basic syntax is as follows:
AND, OR, NOT: logic operators for combining multiple conditions
Bit it also supports more advanced operations such as:
BETWEEN: Between a range of values (inclusive)
LIKE: Pattern matching using wildcards (often used with % and _)
IN: Matches any value in a list
IS NULL Checks for null values
Basic Operators
The equal to operator is used to filter rows where the specified column is equal to a given value.
SELECT * FROM employeesWHERE department = 'sales';
The not equal to operator is used to filter rows where the specified column is NOT equal to a given value.
SELECT * FROM employeesWHERE department != 'sales';
The greater than operator is used to filter rows where the specified column is greater than a specified value:
SELECT * FROM employeesWHERE salary > 50000;
Advanced Operators
The operator BETWEEN is used to filter rows where the specified column is within a range.
SELECT * FROM employeesWHERE age BETWEEN 25 AND 50;
It can be used also with dates, days, hours, ecc:
WHERE oder_date BETWEEN '2023-01-01' AND '2023-06-30';
NOTE: It is inclusive, meaning it includes both the specified start and end values in the range.
The operator IN is used to filter rows where the specified column’s values is contained in a “list” of given values.
SELECT * FROM employeesWHERE department IN ('HR', 'IT', 'Finance');
Better Optimization: PostgreSQL’s query optimizer can often optimize IN queries more effectively than complex combinations of OR conditions.
The operator IS NULL is used to filter rows where the specified column’s values is null.
SELECT * FROM employeesWHERE phone_number is NULL;
The operator LIKE is used for pattern matching, like can uses normal symbols such as letters and numbers, but it also can use with wildcard chars %, _, and [chars] that can be used to match flexible patterns in text searches.
% represents zero, one or multiple characters
_ represents a single character
[chars] matches exactly ONE character that is within the specified set of characters
-- Matches any name starting with 'John'WHERE name LIKE 'John%';-- Matches any 5-letter name starting with 'A'WHERE name LIKE 'A____';-- Matches any 5-letter name starting with 'A' or 'B' or 'C'WHERE name LIKE '[ABC]____';-- Matches names containing 'an' anywhereWHERE name LIKE '%an%';
Note:LIKE is case-sensitive, if you want it be be case-insensitive you can use ILIKE.
ORDER BY
The ORDER BY clause is used to sort the result set in a specified order. The syntax is as follows:
ASC & DESC: The ASC (ascending) and DESC (descending) option are optional, when not specified the default is ascending (ASC).
Data Type: the sorting works on chars, varchars, numbers and dates.
NULL: NULL is considered the lowest possible value when sorting. In ascending order, NULL values appear first; in descending order, they appear last.
One Column Ordering
When ordering by a single column, you can specify the sorting direction:
-- Sort names in ascending order (default)SELECT * FROM employees ORDER BY name; -- Sort names in descending order SELECT * FROM employees ORDER BY name DESC;-- Sort salaries from highest to lowestSELECT * FROM employees ORDER BY salary DESC;`
Multiple Column Ordering
You can order by multiple columns, with each subsequent column used as a tiebreaker:
-- First sort by department in ascending order, -- then sort salaries within each department from highest to lowestSELECT name, department, salary FROM employees ORDER BY department ASC, salary DESC;
LIMIT
The LIMIT command is used to restrict the number of rows returned by a query by specifying the maximum number of rows.
SELECT * FROM paymentORDER BY payment_dateLIMIT 10
SQL Standard (FETCH FIRST)
LIMIT isn’t a SQL standard, but FETCH FIRST n ROWS ONLY is the standard SQL alternative to LIMIT.
SELECT * FROM paymentORDER BY payment_dateFETCH FIRST 10 ROWS ONLY
OFFSET
The OFFSET clause allows you to skip a specified number of rows before starting to return results. It’s typically used with ORDER BY or LIMIT.
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 20;`
Skips the first 20 rows
Returns the next 10 rows
Aggregation Operations
In PostgreSQL, aggregation operations are statements that perform calculations on a table or result set and return a single result (tuple).
The most common and simple aggregation operations are:
COUNT(): Counts the number of rows
SUM(): Calculates the total of numeric values
AVG(): Calculates the average of numeric values
MAX(): Finds the maximum value
MIN(): Finds the minimum value
Single Tuple Output
When using aggregate functions in a SELECT statement, any non-aggregated columns must be part of a GROUP BY clause, for example:
This cases are allowed:
SELECT MAX(cost) from filmSELECT MAX(cost), MIN(cost) from film
This is not:
SELECT title, MAX(cost) FROM film; -- Error: column "film.title" must appear in the GROUP BY clause
This is because aggregate functions produce a single value (or one value per group), while non-aggregated columns can have multiple values.
How to SELECT title, MAX(cost) with out error:
In this case if we want to get the title of the films with the higher replacement cost we have two options:
WITH min_val AS ( SELECT MAX(replacement_cost) AS max_replacement_cost FROM film)SELECT *FROM film, max_valWHERE film.replacement_cost = max_val.max_replacement_cost;
SELECT *FROM filmWHERE replacement_cost = (SELECT MAX(replacement_cost) FROM film);
COUNT
The COUNT function counts the number of rows that match a specified condition within a table or a result set.
It returns a single value representing the count of rows that meet the criteria.
COUNT(*)
Use COUNT(*) to count the total number of rows in a table, irrespective of whether there are NULL values.
COUNT(column_name)
The COUNT(column_name) counts the number of non-NULL values in the specified column.
So It ignores NULL values in that particular column and only counts the rows where the specified column has a non-NULL value.
COUNT + DISTINCT
The DISTINCT keyword is used to eliminate duplicate rows from the result set. When combined with the COUNT function, it allows you to count the number of unique values in a specific column.
For example: count the name of the departments in the “employees” table:
To get the output 1 we can use: SELECT COUNT(department) FROM employees
To get the output 2 we can use: SELECT COUNT(DISTINCT department) FROM employees
GROUP BY
The GROUP BY clause divides the result set into groups based on common values present in the defined columns, then a Aggregate Function operates on each group separately, producing a single row for each group.
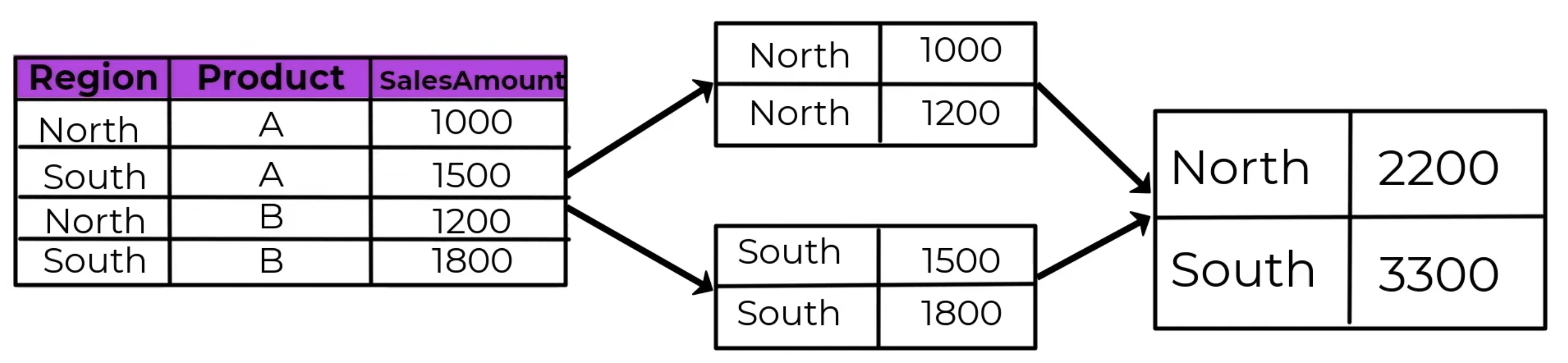
The GROUP BY operation follows a Split, Apply, Combine process. Let’s consider a hypothetical sales table with columns “Region,” “Product,” and “SalesAmount.” To analyze total sales for each region, we apply the following steps:
Split: The dataset is divided into groups based on unique values in the “Region” column.
Apply: Aggregate functions, such as SUM(SalesAmount), are applied to the “SalesAmount” column within each region group.
Combine: The aggregated results are combined, creating a summary table that displays the total sales for each region!
HAVING (filtering)
HAVING it’s a clause that uses a condition to filter the resulting groups resulted from group by.
It’s important to net get confused with where, that filters the result of the select.
WHERE
HAVING
Filters before grouping
Filters after grouping
Works on individual rows
Works on grouped results
Cannot use aggregate functions
Can use aggregate functions
Comes before GROUP BY
Comes after GROUP BY
Example
SELECT department, AVG(salary) as avg_salary, COUNT(*) as employee_countFROM employeesGROUP BY departmentHAVING AVG(salary) > 50000 AND COUNT(*) > 5;
In this example:
Groups employees by department
Calculates average salary and employee count per department
Filters to show only departments with:
Average salary over $50,000
More than 5 employees
AS
The AS statements is uses to give “nicknames” to tables, columns, or calculations within you queries.
Giving Simpler Names
SELECT first_name AS fname, last_name AS lname, email_address AS contact_emailFROM employees;
Renaming Columns from Aggregate Functions
SELECT department, AVG(salary) AS average_department_salary, COUNT(*) AS total_employees, SUM(bonus) AS total_bonus_payoutFROM employee_compensationGROUP BY department;
Disambiguating Tables with Same Column Names
SELECT e.id AS employee_id, e.name AS employee_name, d.name AS department_nameFROM employees eJOIN departments d ON e.department_id = d.id;
Calculations with Aliases
SELECT product_name, price, price * 1.1 AS price_with_taxFROM products;
Subquery Aliases
SELECT department, avg_salaryFROM ( SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department) AS dept_salariesWHERE avg_salary > 50000;
Arithmetic Operations
PostgreSQL supports standard arithmetic operations in SELECT queries:
SELECT column_name, column1 + column2 AS sum, column1 - column2 AS difference, column1 * column2 AS multiplication, column1 / column2 AS division, column1 % column2 AS moduloFROM table_name;
Operations work with numeric data types
Can be used in SELECT, WHERE, and ORDER BY clauses
Example
Apply a 10% discount to car prices
SELECT id, maker, model, price, ROUND(price * .10, 2) AS discount, ROUND(price - price * .10, 2) as final_priceFROM car
Note:ROUND() is a function used to round a numeric value to a specified number of decimal places.
PostgreSQL follows standard mathematical order of operations (PEMDAS):
Parentheses ()
Exponents ^
Multiplication *, Division /, Modulo %
Addition +, Subtraction -
SELECT (2 + 3) * 4 AS result; -- Result is 20, not 14
COALESCE
COALESCE returns the first non-NULL value in a “list”, if all arguments are NULL, returns NULL.
COALESCE(value1, value2, ..., valueN)
Example
SELECT COALESCE(email, 'Email not provided')
output:
coalesce
------------------------------------
fdickson0@unc.edu
jgiraldo1@independent.co.uk
Email not provided
NULLIF (division by zero)
NULLIF returns NULL if the two input value are equal, otherwise returns the first value.
NULLIF(val1, val2)
This operation can be really useful for handling potential division by zero.
Division by Zero
In PostgreSQL a division by zero will return an error:
SELECT 10 / 0; --ERROR: division by zero
But a division by NULL is allowed and will return a “empty” (null) value.
SELECT 10 / NULL;
Output:
?column?
----------
Handling division by zero using NULLIF
When performing division where the denominator might be zero, use NULLIF to prevent division by zero errors. This ensures that instead of raising an error, the result becomes NULL when the denominator is zero.
Note: It’s always possible to use COALESCE to replace null values with a default value, such as zero or another meaningful placeholder.
-- Check if date is within a specific rangeSELECT * FROM employees WHERE hire_date BETWEEN '2020-01-01' AND '2022-12-31';
Functions
There are specific function that can be used on date and time types:
EXTRACT
extract()is used to pull specific components form date ore time, for example:
-- Extract year, month, day form a dateEXTRACT(YEAR FROM current_date)EXTRACT(MONTH FROM current_timestamp)EXTRACT(DOW FROM current_date) -- Day of week
-- Extract hour, minute, second from current timeEXTRACT(HOUR FROM current_time)EXTRACT(MINUTE FROM current_time)EXTRACT(SECOND FROM current_time)-- Additional time-related extractionsEXTRACT(EPOCH FROM current_time) -- Seconds since midnight
There are also the MILLISECONDS and MICROSECONDS components for TIME.
Day of the week rap presentation
Days of the week use a numeric representation, this means that: