La programmazione dinamica è una tecnica algoritmica che consiste nella memorizzazione delle soluzione di sotto problemi che si incontrano più volte durante il processo di risoluzione di un problema, in modo da non doverli ricomputare quando sono necessari in seguito.
Questa ottimizzazione, in alcuni casi, può riduce le complessità temporali da esponenziali a polinomiali.
Fibonacci
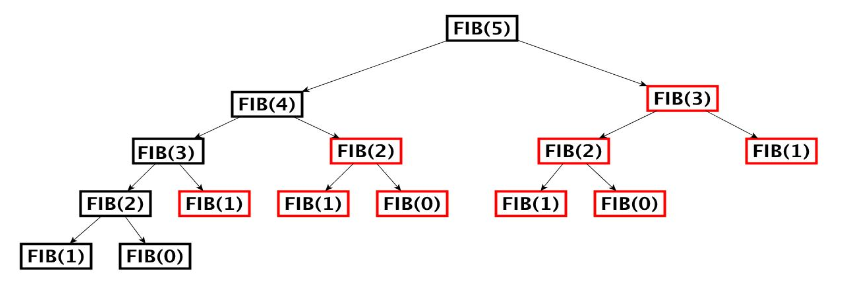
Si può osservare questo fenomeno molto facilmente nel calcolo dei numeri di fibonacci, tramite l’algoritmo ricorsivo:
def Fib(n): if n <= 1: return 1 return Fib(n-1) + Fib(n-2)
Ad esempio per il calcolo di fib(5) verrano computati anche:
Visto che i sottoproblemi in cui viene scomposto il problema non sono disgiunti (overlapping di sottoproblemi) durante della scomposizione in sottoproblemi, stesse quantità vengono calcolate più volte da differenti chiamate ricorsive.
È facile vedere che il costo computazionale questo algoritmo è rappresentato dalla seguente funzione:
T(n)=T(n−1)+T(n−2)+Θ(1)
che viene risolta da:
T(n)≥2T(n−2)+Θ(1)
E questa ricorrenza può essere facilmente risolta (ad esempio col metodo iterativo) ottendendo:
T(n)≥Θ(22n)
Memoizzazione
Una tecnica molto semplice prende il nome di memoizzazione e consiste nel memorizzare i risultati precedenti. Questo permette di ridurre il tempo di calcolo, al costo di un incremento di occupazione di memoria.
Fibonacci
Un algoritmo iterativo, che utilizza la memoizzazione, per risolvere problema del calcolo dei numeri di fibonacci è:
def Fib2(n): F = [-1] * (n + 1) F[0] = F[1] = 1 for i in range(2, n + 1): F[i] = F[i - 2] + F[i - 1] return F[n]
Grazie a questo algoritmo abbiamo ridorro il costo temporale a Θ(n), e il costo spaziale è sempre Θ(n).
La complessità Θ(n) di spazio è a causa della lista da memorizzare ma in realtà dell’intera tabella basta conservare in memoria volta per volta solo gli ultimi due valori calcolati, riducendo il costo spaziale a Θ(1):
def Fib3(n): if n <= 1: return n a = b = 1 for i in range(2, n + 1): a, b = b, a + b return b
Approccio Top-down e Botton-up
Nella versione ricorsiva del algoritmo per il calcolo dei numeri fibonacci, abbiamo utilizzato un approccio top-down al problema. Ovvero si parte dal problema principale scomponendolo via via in sottoproblemi di dimensione sempre più piccola fino ad arrivare a problemi facilmente risolvibili.
Nella versione iterativa, abbiamo utilizzato un approccio bottom-up. Ovvero si comincia col risolvere i sottoproblemi di dimensione sufficientemente piccola per poi passare a quelli di dimensione via via crescente fino ad arrivare alla soluzione del problema originario.
Esempio
Abbiamo n file di varie dimensioni ciascuna inferiore a C e un disco di capacità C, l’obbiettivo è trovare il sottoinsieme di file che può essere memorizzato sul disco e che massimizza lo spazio occupato.
Progettare un algoritmo che dati la capacità C e la lista A , dove A[i] è dimensione del file i , risolva il problema.
Osservazioni
Non è difficile rendersi conto che algoritmi greedy del tipo “finché c’è spazio memorizza sul disco il file di massima dimensione” non trovano sempre la soluzione ottima.
Per questo problema non si conoscono algoritmi efficienti, ma soltanto algoritmi che si basano su un qualche tipo di ricerca esaustiva della soluzione.
Per fortuna è altrettanto facile trovare algoritmi d’approssimazione efficienti con rapporti d’approssimazione costante.
Versione Greedy (divide et impera)
def es(A, C): return esR(A, C, len(A)-1)def esR(A, i, C): if i == 0 or C == 0: return 0 # lascio = spazio massimo che si riesce ad occupare lasciando l'ultimo elemento lascio = esR(A, i-1, C) # se la dimensione del file corrente supera la capacità lo scarto if A[i] > C: return lascio # prendo = spazio massimo che si riesce ad occupare prendendo l'ultimo elemento prendo = A[i] + esR(A, i-1, C-A[i]) return max(lascio, prendo)
La funzione che descrive la complessità di questa implementazione è:
T(n,C)=T(n−1,C)+T(n−1,C−A[n−1])+Θ(1)
Che, ad esempio, considerando l’istanza C = n-1 e A[i] = 1 per ogni file i avrà costo:
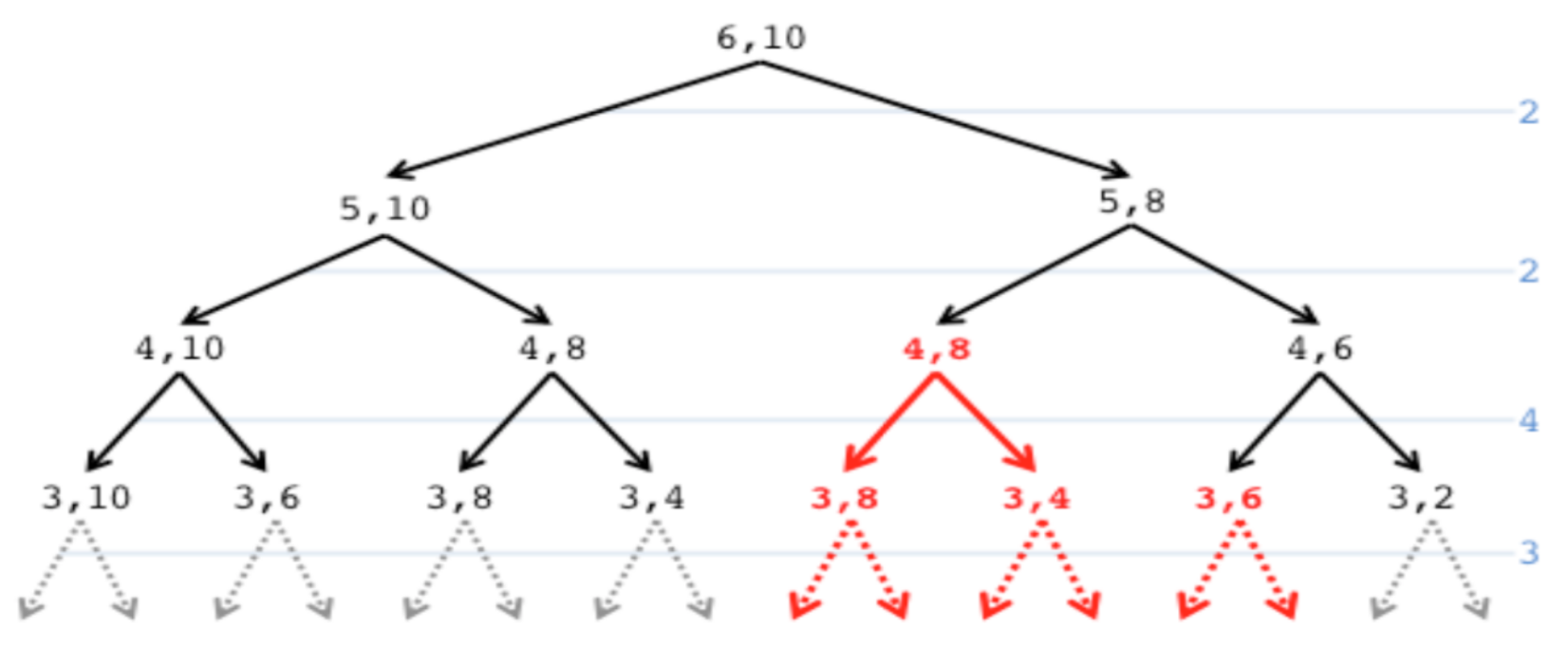
Il il motivo di questi tempo intrattabili è dovuto al overlapping dei sotto problemi, ad esempio Di seguito
l’esecuzione dell’istanza dove C = 10 e A = [1, 5, 3, 4, 2, 2].
Verisone divide et impera memoizzato
def es(A, C): T = [ [-1] * (C+1) for i in range(len(A)+1) ] return esMem(A, len(A)-1, C, T)
def esMem(A, i, C, T): if T[i][c] == -1: if i == 0 or C == 0: T[i][c] = 0 else: lascio = esMem(A, i-1, c, T) T[i][c] = lascio if A[i] <= C: prendo = T[A] + esMem(A, i-1, c-A[i], T) T[i][c] = max(lascio, prendo) return T[i][c]
Il tempo di calcolo di questa versione limitato dalla dimensione della tabella. Infatti, la funzione esMem() ha costo O(1)e il numero totale di chiamate non può superare la dimensione della tabella.
Quindi in es() la creazione di T ha costo Θ(nC) e tutte le chiamate ad esMem() possono avere al massimo un costo combinato di Ω(nC) quindi il costo totale di questo algoritmo è Θ(nC).
Conviene utilizzare la versione memoizzata o non?
Abbiamo visto che la versione memoizzata ha costo Θ(nC) molto minore rispetto al costo di (2n) della versione non memoizzata, dove n è il numero di file.
Nota: Se C è molto grande, ad esempio quando supera 2n, la versione memoizzata è peggiore.
Però se C non è così grande, allora la versione memoizzata può essere enormemente più efficiente. Consideriamo un caso realistico, abbiamo:
1000 file (n = 1000)
Disco di capacità di 1 Terabyte (C = 1.000.000 se l’unità di misura è MB)
Tutti i file di dimensione 1000 byte (1GB) in modo tale che qualsiasi sottoinsieme dei 1000 file possa essere memorizzato sul disco.
L’algoritmo non memoizzato eseguirà tutte le chiamate ricorsive (cioè sarà sempre possibile scegliere il k-esimo file) almeno relativamente ai 1000 primi file (da n = 100.000 a 99.000 ). Quindi la complessità in questo caso è di 21000
L’algoritmo memoizzato in questa situazione ha una complessità di 100.000 x 1.000.000 = 100.000.000.00.
Quindi un computer con sufficiente memoria (dell’ordine delle centinaia di GB) può eseguire l’algoritmo memoizzato in meno di un’ora. Mentre con l’algoritmo non memoizzato, dovendo eseguire almeno 21000 operazioni, il che anche utilizzando i computer del pianeta richiederebbe miliardi di anni.
Versione Iterativa
Sia nella versione greedy che nella versione memoizzata abbiamo utilizzato la ricorsione insieme ad un approccio top-down, l’utilizzo della ricorsione ha degli svantaggi:
rischio di errori di tipo maximum recursion depth exceeded
consumo di memoria (stack) dovuto alle chiamate ricorsive
Per questo una volta trovata una versione ricorsiva può aver senso cercarne una iterativa. Solitamente nelle versione iterative si utilizza un approccio bottom-up al problema, partendo dai sotto problemi più piccoli per arrivare al problema principale.
def esI(A, C): T = [ [0]*(C+1) for i in range(len(A)+1) ] for i in range(1, n+1): for c in range(C+1): if c < A[i-1]: T[i][c] = T[i-1][c] else: T[i][c] = max( T[i-1][c], A[i-1] + T[i-1][c-A[i-1]] ) return T[len(A)][C]
Utilizzo della tabella per determinare la soluzione
Fino ad ora abbiamo utilizzato la tabella come uno strumento d’appoggio per memorizzare i risultati dei sotto problemi. Possiamo utilizzare per ricavare i passaggi che abbiamo effettuato per determinare la soluzione.
L’idea consist nel partire dall’elemento che rappresenta il valore ottimo del problema e di percorrere all’indietro la tabella, di elemento in elemento seguendo a ritroso le ”decisioni” che hanno portato a determinare quel valore.
Esempio
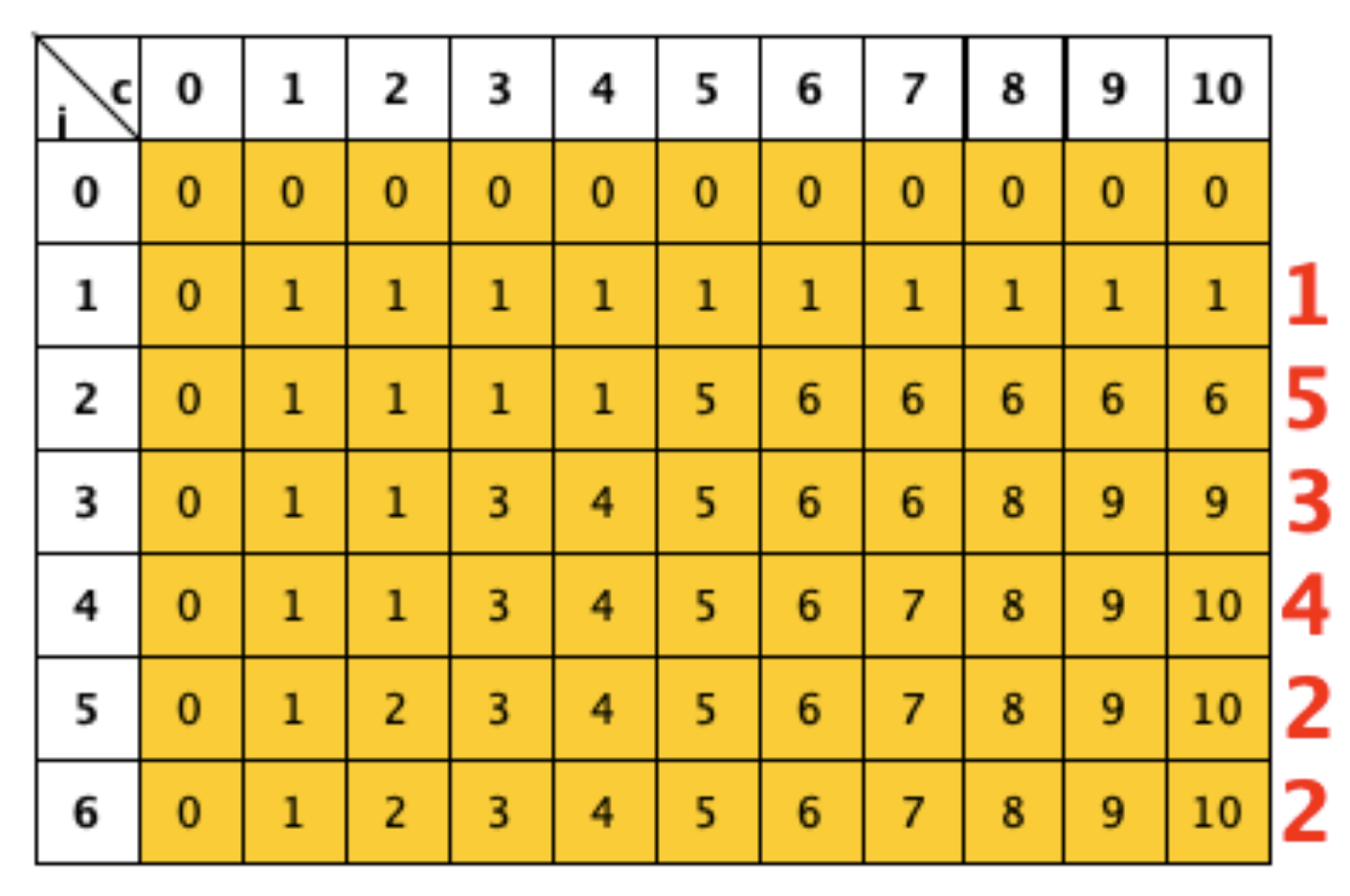
Come esempio consideriamo la tabella T del problema FILE relativamente all’istanza C = 10 e 6 file di dimensioni A = [1, 5, 3, 4, 2, 2].
Tenendo conto che la tabella è stata calcolata per mezzo della seguente formula ricorsiva:
Possiamo determinare che il percorso effettuato per arrivare alla soluzione ottima è stato:
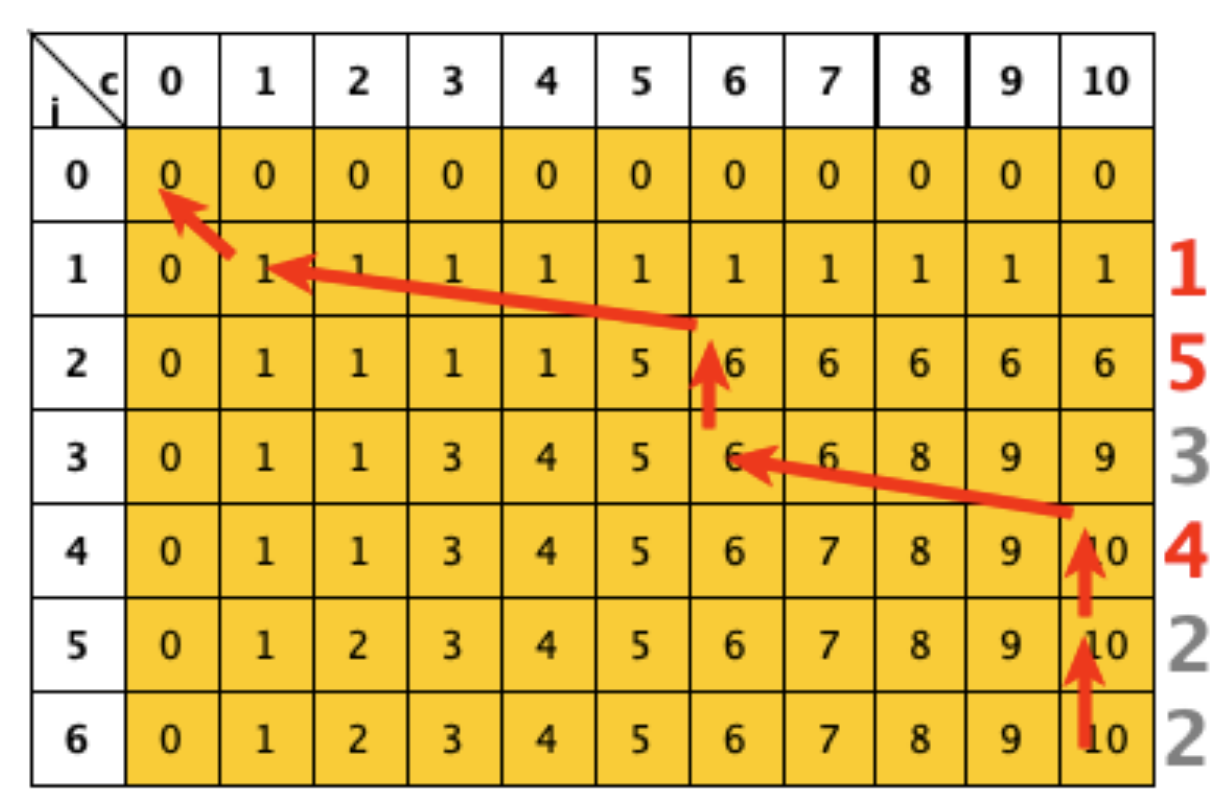
Nella figura a partire da T[n,C] (elemento in basso a destra) da ogni elemento toccato della tabella T[i,c] è tracciata una freccia verso l’elemento in base al quale è stato calcolato T[k, c]:
se la freccia è verso T[i-1,c] (una freccia verticale) vuol dire che il k-esimo file non è stato scelto.
se la freccia è verso T[i-1, c-A[i]] (una freccia obliqua) vuol dire che il k-esimo file è stato scelto.
Quindi le frecce rosse evidenziano le decisione prese a partire dall’elemento T[n,C] che fornisce il valore della soluzione ottima. In base a questo nell esempio è possibile determinare che la soluzione ottima sono i file di dimensione 4,5,1.
Implementazione:
def esI(A, C): n = len (A) T = [ [0]*(C+1) for i in range(n+1) ] for i in range(1, n+1): for c in range(C+1): if c < A[i-1]: T[i][c] = T[i-1][c] else: T[i][c] = max( T[i-1][c], A[i-1] + T[i-1][c - A[i-1]] ) # Determinare soluzione ottima: valore = T[n] [C] sol = [] i = n while i > 0: if T[i][valore] != T[i-1][valore]: sol.append(i-1) valore -= A[i-1] i -= 1 return T[n][C], sol
Costo:
Nella prima parte viene pagato O(nC) per il calcolo della tabella.
Nella seconda parte, alla ricerca dei file presenti nella soluzione ottima, la tabella viene visitata a partire dall’ultima cella T[n, C], un riga in meno per volta. Il costo di questa visita è O(n).