Il routing si occupa di trovare il miglior percorso e inserirlo nella tabella di routing (o tabella di forwarding), in altre parole il routing costruisce le tabelle, il forwarding le utilizza.
I protocolli intra dominio come il RIP si occupano di instradare i datagramma all’interno della stessa rete, successivamente vedremo quelli inter dominio ovvero che mettono in comunicazione reti diverse.
Grafo di una rete
Quando si parala di routing la rete può essere vista come un grafo G dove:
I nodi rappresentano i router
Gli archi rappresentano i collegamenti (link) tra i nodi.
Solitamente si utilizzano grafi pesati, dove il peso può rappresentare un costo, ad esempio tempo di percorrenza, congestione o costo monetario.
con c(x,y) indichiamo il costo del collegamento tra il nodo x e y.
Quindi l’obbiettivo di un algoritmo di routing sarà trovare il percorso con costo minimo.
Algoritmo d’instradamento con vettore distanza (Distance Vector - DV)
Questo è un algoritmo di instradamento che utilizza l’Equazione di Bellman-Ford e il concetto di vettore delle distanze ed ha queste due caratteristiche:
Distribuito - ogni nodo riceve informazione dai vicini e opera su quelle
Asincrono - non richiede che tutti i nodi operino al passo con gli altri
Equazione di Bellman - Ford
Definisce con Dx(y) il costo del percorso con costo minimo dal nodo x al nodo y.
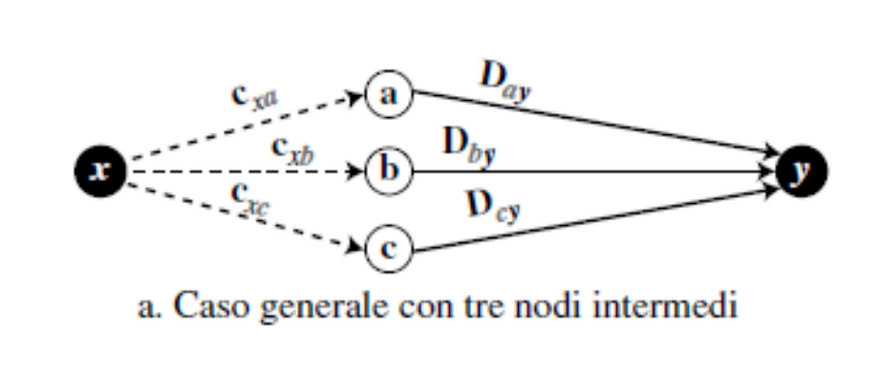
Dx(y)=minv(c(x,v)+Dv(y))
oss:v è un vicino di x e minv permette di prendere il vicino di x che minimizza c(x,v)+Dv(y).
In questo esempio i percorsi a->y, b->y, c->y sono percorsi a costo minimo precedentemente stabiliti e x->y è un nuovo percorso a costo minimo.
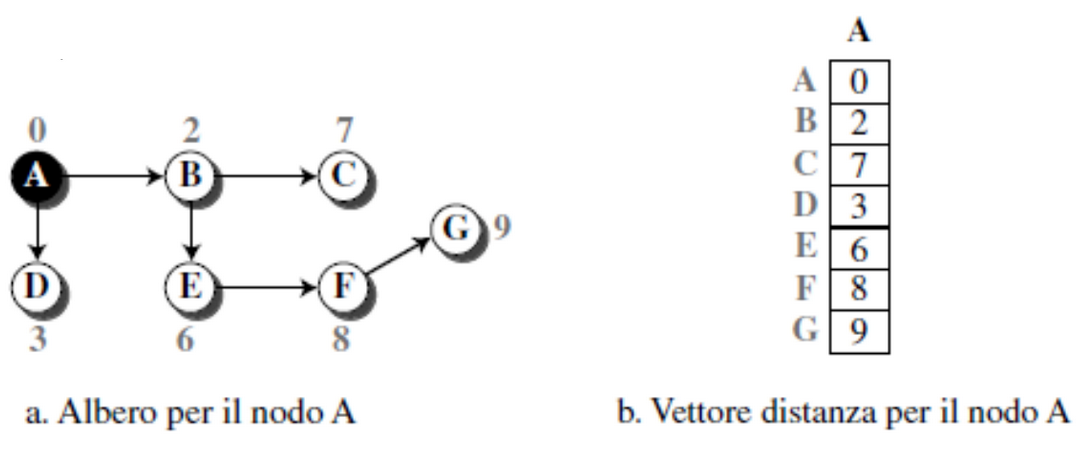
Vettore delle distanze
Un albero a costo minimo è una combinazione di percorsi a costo minimo dalla radice dell’albero verso tutte le destinazioni, un vettore di distanza è un array monodimensionale che rappresenta l’albero.
Questo vettore non fornisce il percorso da seguire per giungere alla destinazione ma solo i costi minimi per le destinazioni:
Creazione del Vettore delle Distanze
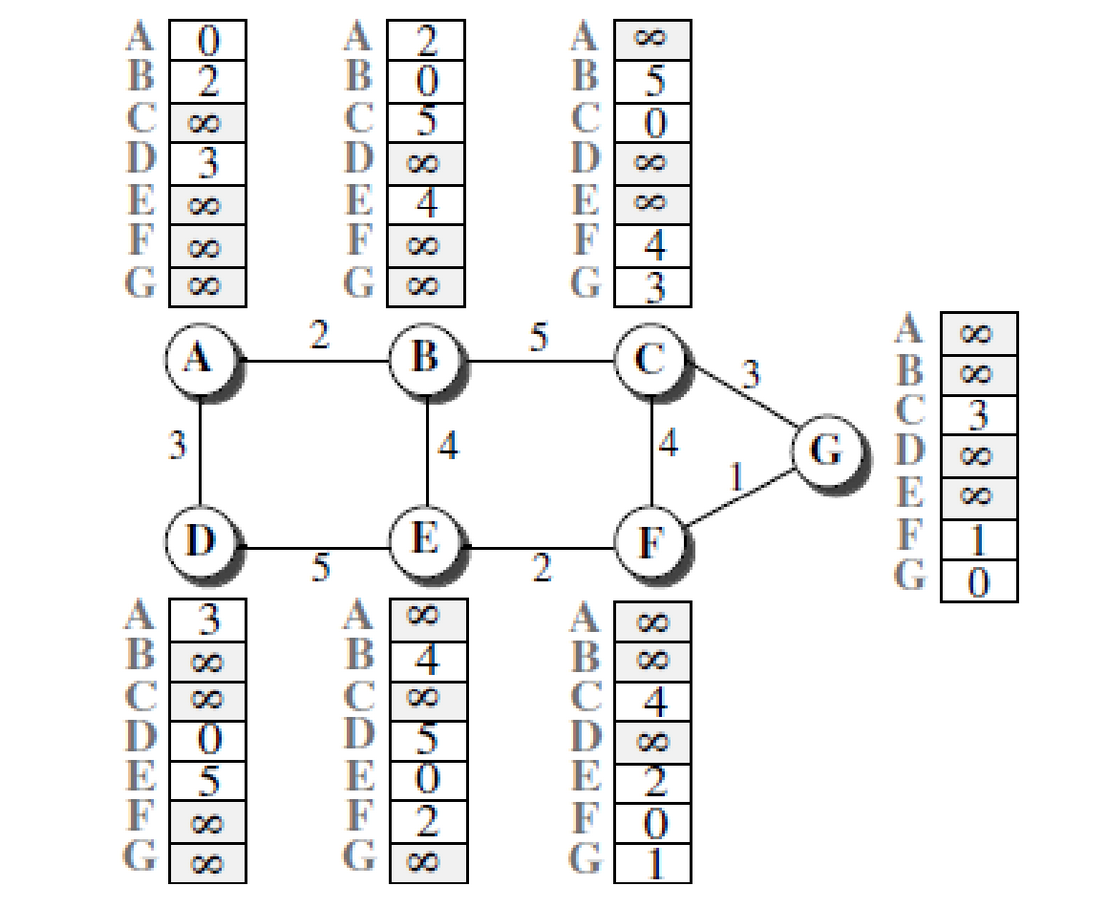
Ogni nodo della rete quando viene inizializzato crea un vettore distanza iniziale con le informazioni che riesce ad ottenere dai vicini. Per fare questo invia dei messaggi di hello attraverso tutte le sue interfacce e scopre l’identità e il costo per raggiungere i suoi vicini.
Dopo che un nodo ha creato il suo vettore invia una copia ai suoi vicini.
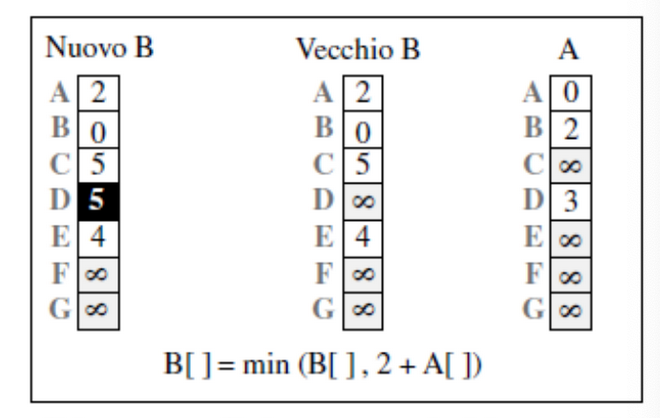
A questo punto, quando un nodo riceve un vettore da un suo vicino aggiorna il suo vettore applicando l’equazione di Bellman-Ford.
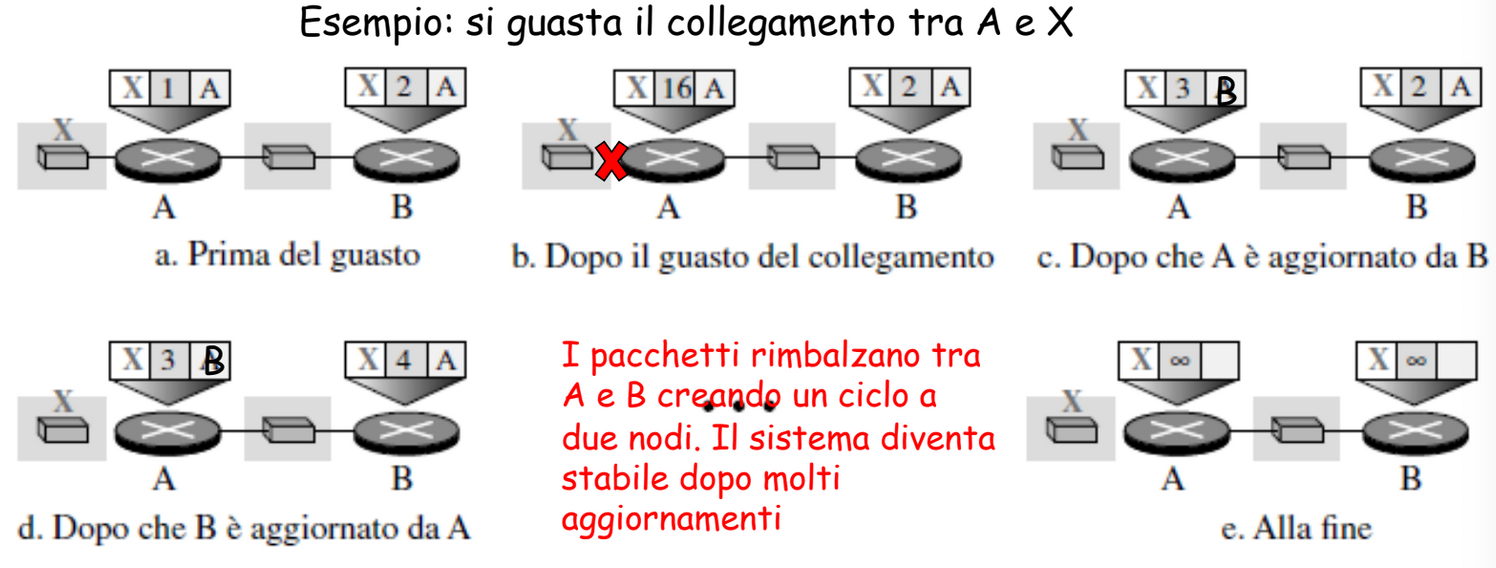
Esempio:
Cosa succede quando B riceve una copia del vettore di A?
Algoritmo
Idea Base: Quando un nodo riceve una copia di un vettore e questo porta a degli aggiornamenti all’interno del suo vettore, allora anche questo nodo rinvierà il suo nuovo vettore a tutti i vicini.
Quindi, ciascun nodo:
Attende un messaggio da parte di un vicino
Effettua il calcolo
Se il vettore cambia notifica i vicini e torna in attesa
Questa funzionalità, è descritta dal seguente algoritmo:
per tutte le destinazioni y in N: se y è un vicino D_x (y) = c(x,y) else D_x (y) = infper ciascun vicino w invia il vettore D_x = [D_x(y): y in N] a w
Questo algoritmo presenta il problema del conteggio all’infinito:
Ovvero, è richiesto molto tempo prima che un guasto sulla rete venga notificato, questo perché le informazioni devono propagarsi tra tutti i nodi, ed in questa implementazione una “cattiva” notizia viaggia più lentamente rispetto ad una “buona notizia”.
Possibili soluzioni a questo problema:
Split Horizon - Si invia solo una parte della propria tabella di routing, se il nodo B ritiene che il percorso ottimale per raggiungere un nodo X passi attraverso A, allora non deve fornire questa informazione ad A, infatti lui la conosce già. Nell’esempio di prima quindi B dovrebbe eliminare la riga di X prima di inviare la tabella ad A.
Poisoned Reverse - Si pone a infinito il valore del costo del percorso che passa attraverso il vicino a cui si sta inviando il vettore. Nell’esempio quindi B deve porre a infinito il costo verso X quando invia il vettore ad A.
Protocollo RIP (Routing Information Protocol)
Il protocollo RIP è l’implementazione del algoritmo appena visto, quindi si basa sul vettore delle distanze.
In particolare non è utilizzabile su reti di gradi dimensione dove il numero di salti non è maggiore di 15 (16 indica infinito), questo perché richiede che i router comunichino tra di loro.
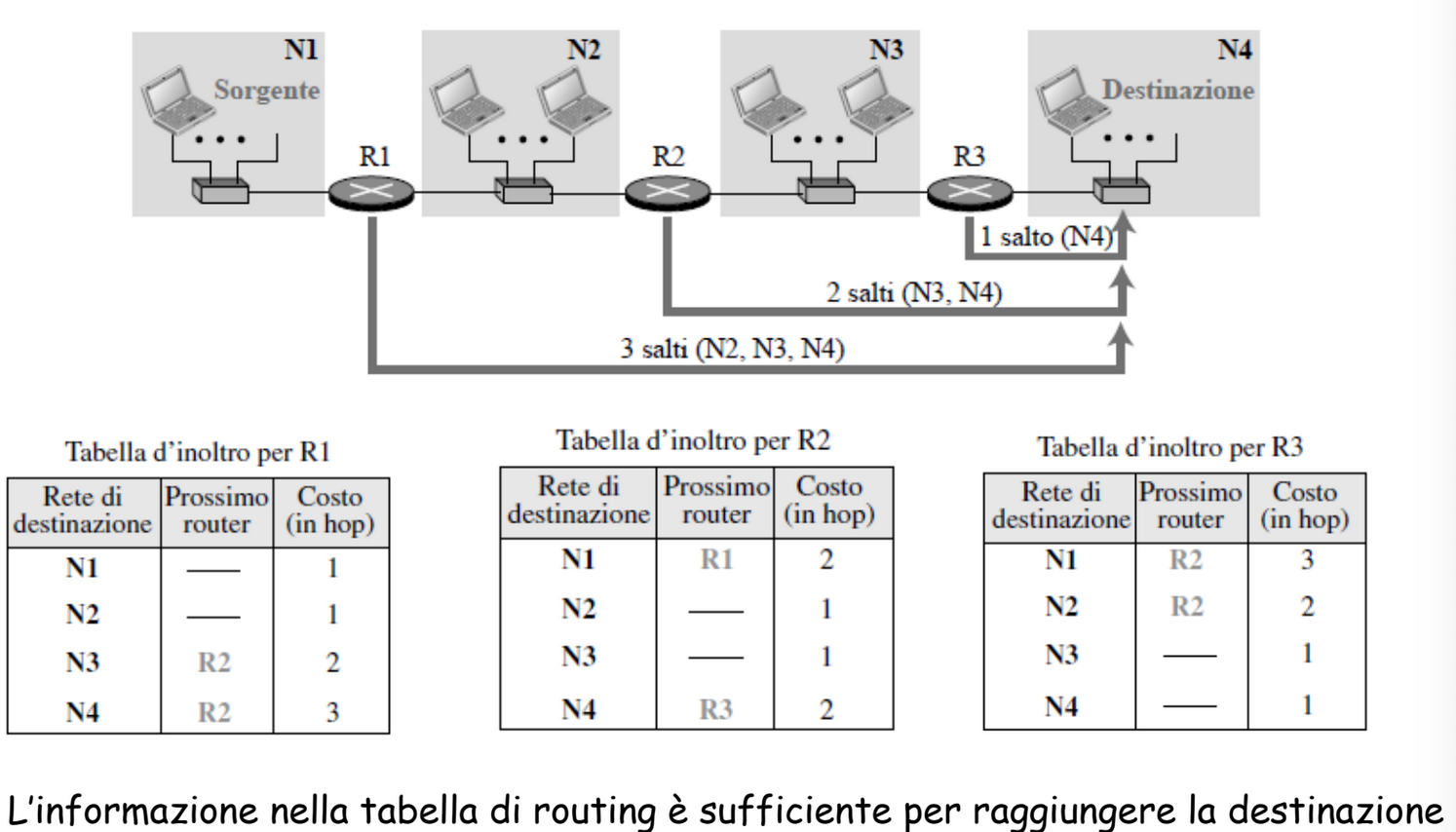
Tabelle di Routing
Ogni router, ad intervalli di tempo, invia la sua tabella di routing agli altri router. In questo modo gli altri possono aggiornare le proprie tabelle e notificare a loro volta altri router.
Messaggi e Timers
il Routing Information Protocol si basa su una coppia di processi client-server e sul loro scambio di messaggi.
RIP Request - Inviato quando un nuovo router viene inserito nella rete, è utilizzato per richiedere informazioni di routing.
RIP Response (advertisements) - Inviate in risposta ad una request oppure periodicamente ogni 30 secondi.
Ogni messaggio contiene un elenco comprendente fino a 25 sottoreti di destinazione all’interno del sistema autonomo nonché la distanza del mittente rispetto a ciascuna di tali sottoreti.
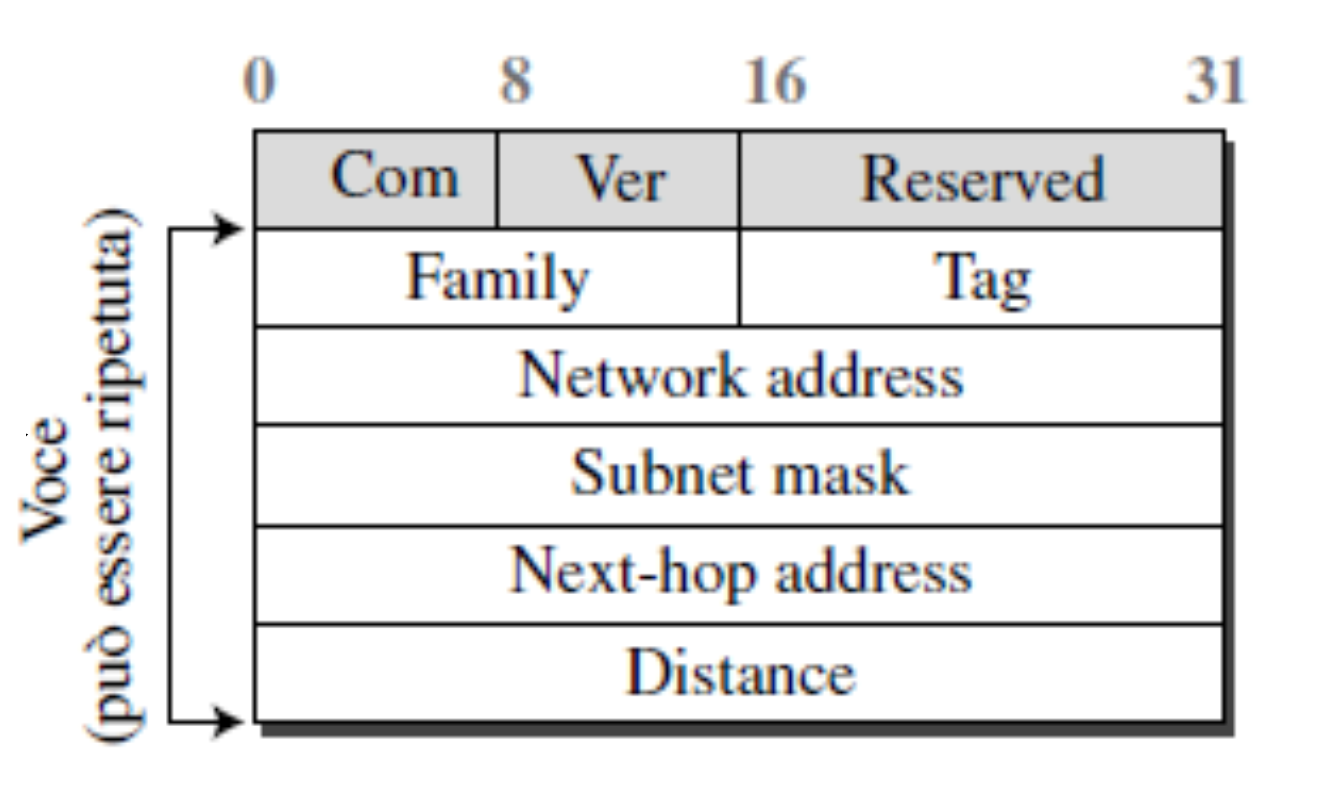
Struttura messaggi
Com: comando, indica se è una richiesta o una risposta
Ver: versione del protocollo utilizzato
Family: famiglia del protocollo, per il TCP/IP il valore è 2
Tag: informazioni sul sistema autonomo
Network address: indirizzo di destinazione
Subnet mask: maschera di sottorete (lunghezza del prefisso)
Next-hop address: indirizzo del prossimo hop
Distance: numero di hop fino alla destinazione
Timers
Il RIP inoltre utilizza alcuni timer:
Timer periodico: Gestisce l’invio dei messaggi di aggiornamento, di solito ogni 25-35 secondi
Timer di scadenza: Regola la validità dei percorsi (ogni 180 secondi), se non riceve aggiornamenti da un router entro lo scadere del timer imposta il costo verso esso a 16
Timer per garbage collection: Elimina i percorsi dalla tabella (ogni 120 secondi), elimina i percorsi con costo 16.
Gestione Guasti
Se un router A non riceve notizie dal suo vicino per 180 secondi (timer) il nodo il collegamento viene considerato spento o guasto.
Conseguenze:
Viene modificata la tabella d’istradamento del nodo A.
A propaga la nuova tabella ai sui vicini.
I vicini di A aggiornano le loro e propagano le propagano le tabelle nella rete.
Triggered Updates - Riduce il problema della convergenza lenta, quando una rotta cambia non si aspetta la fine del timer ma si inviano subito le tabelle.
Hold-down - Fornisce robustezza, quando si riceve una informazione di una rotta non più valida si avvia un timer e tutti gli advertisement che arriveranno riguardanti quella rotta verrano ignorati.
Protocollo Livello Applicazione
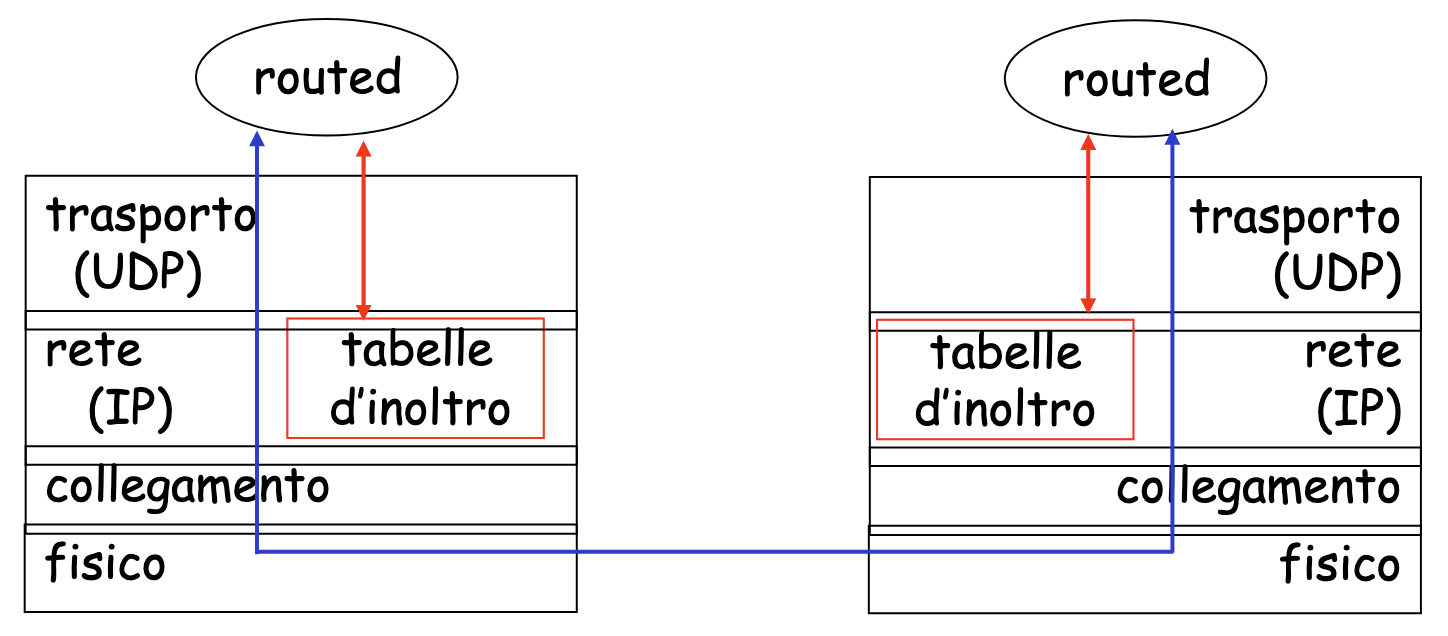
Il protocollo RIP anche se protocollo di rete è implementato a livello applicazione, usa il protocollo UDP sulla porta 520.
Tramite un processo chiamato routed si mantengono le informazioni d’instradamento e lo scambio dei messaggi con i processi dei router vicini.
Dato che ci troviamo sul livello applicazione per quanto riguarda l’implementazione, possiamo inviare e ricevere messaggi su una socket standard e utilizzare un protocollo di trasporto standard.