Danger
Quello che diremo vale per gli hard drive disk (HDD), non per i solid state disk (SSD).
Introduzione agli HDD
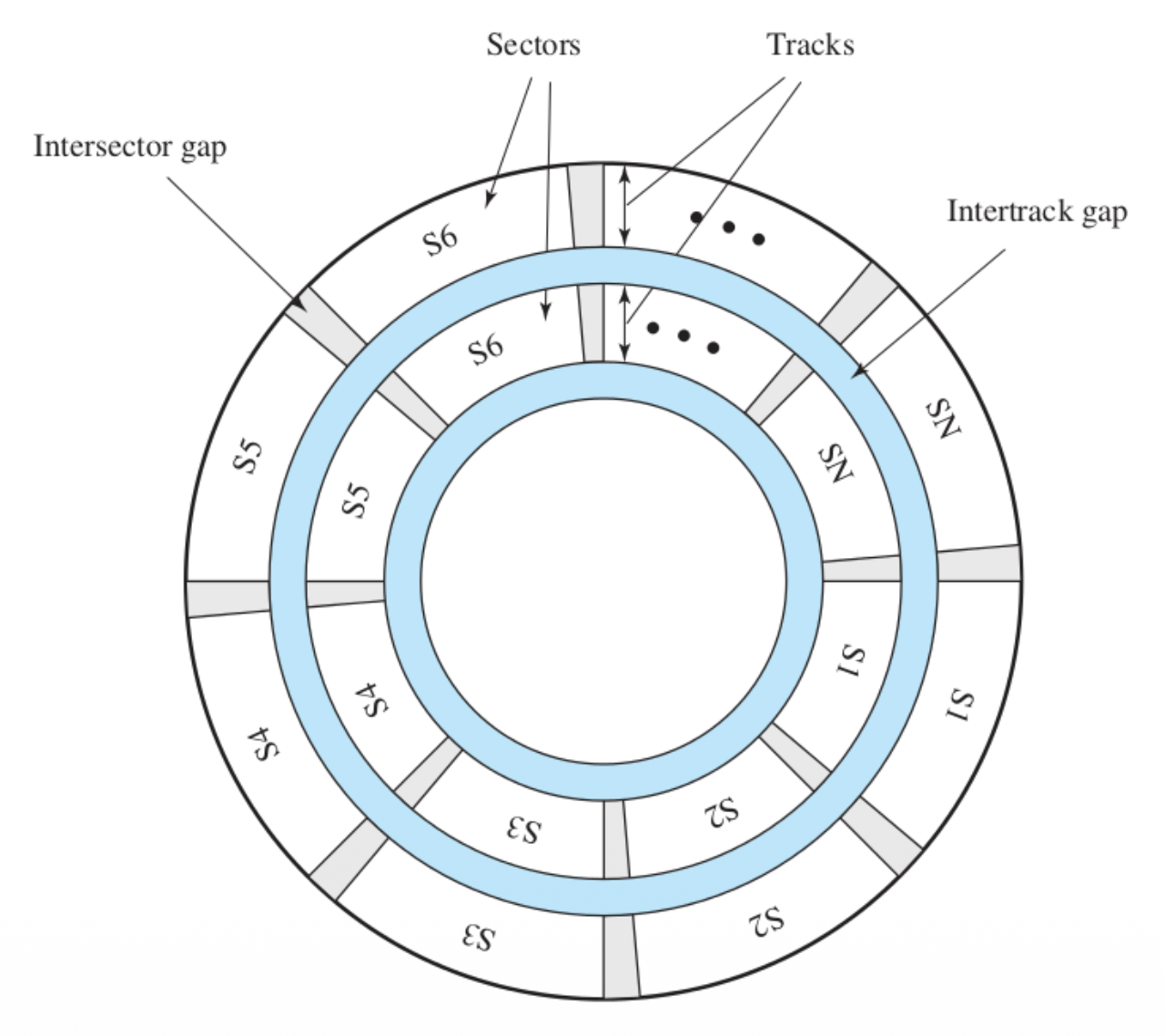
Un hdd è suddiviso in tracce, dove ogni traccia è un percorso intero circolare.
Le tracce sono suddivise in settori, delimitati uno dall’altro con delle aree di “demarcazione” chiamate Intersector Gaps.
Lettura dei Dati
I dati si trovano quindi sulle tracce e sui settori, per leggere e scrivere quindi devo sapere su quale traccia e su quale settore di questa traccia si trovano i dati.
Per selezionare una traccia bisogna:
- Spostare una testina se il disco ha testine mobili (ci focalizziamo su queste)
- Selezionare una testina se il disco ha testine fisse
Per selezionare un settore:
- Dobbiamo aspettare che il disco ruoti (a velocità costante)
Se i dati sono tanti, potrebbero essere su più settori o addirittura su più tracce.
Note: una tipica misura di un settore è 512 bytes
Prestazioni
Un’operazione sul disco dipende da molti dettagli:
- Il SO chiede al disco se é libero per essere utilizzato.
- Se i dischi hanno più canali (più dischi) aspettare anche che il canale sia libero.
- Adesso che siamo nel disco interessato dobbiamo muovere la testina sulla traccia (seek).
- Aspettare il tempo di rotazione per il settore (Rotational Delay)
- Trasferimento dati, qui il disco continua a girare ma la testina legge o scrive dati.
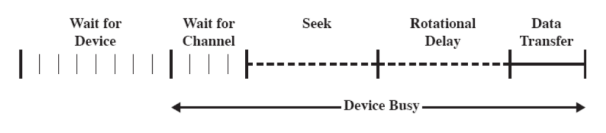
Abbiamo il tempo di accesso che é dato dalla somma di:
- Seek Time ovvero il tempo di posizionamento della testina sulla traccia
- Rotational Delay ovvero il tempo necessario affinché l’inizio del settore raggiunga la testina.
- Tempo di trasferimento, il tempo richiesto per trasferire i dati che scorrono sotto la testina.
Abbiamo inoltre anche i tempi di:
- Wait for device: Il tempo di attesa che il dispositivo sia assegnato alla richiesta
- Wait for channel: Attesa che il sotto dispositivo sia assegnato alla richiesta (ad esempio se ci sono più dischi sullo stesso canale di comunicazione)
Politiche di Scheduling per il Disco
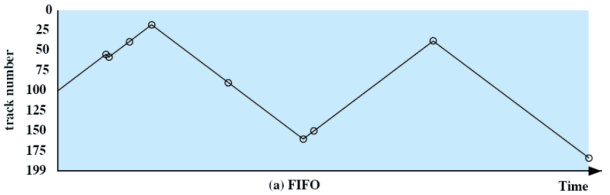
FIFO
Le richieste sono servite in modo sequenziale è equo nei confronti dei processi.
Se ci sono molti processi in esecuzione, le prestazioni sono simili allo scheduling random.
Priorità
Politica di scheduling dove i processi hanno una priorità assegnata, e in base a questa si decide l’ordine di accesso al disco.
Con questo tipo di politica l’obiettivo non è ottimizzare il disco, ma raggiungere altri obiettivi.
Quindi non va bene per DBMS.
LIFO
Politica di scheduling dove il disco è dato al processo più che ha effettuato la richiesta più recentemente.
Utile quando:
- se si tratta dello stesso utente, probabilmente sta accedendo sequenzialmente ad un file quindi, è più efficiente mandare avanti lui
- Ottimo per DBMS con transazioni
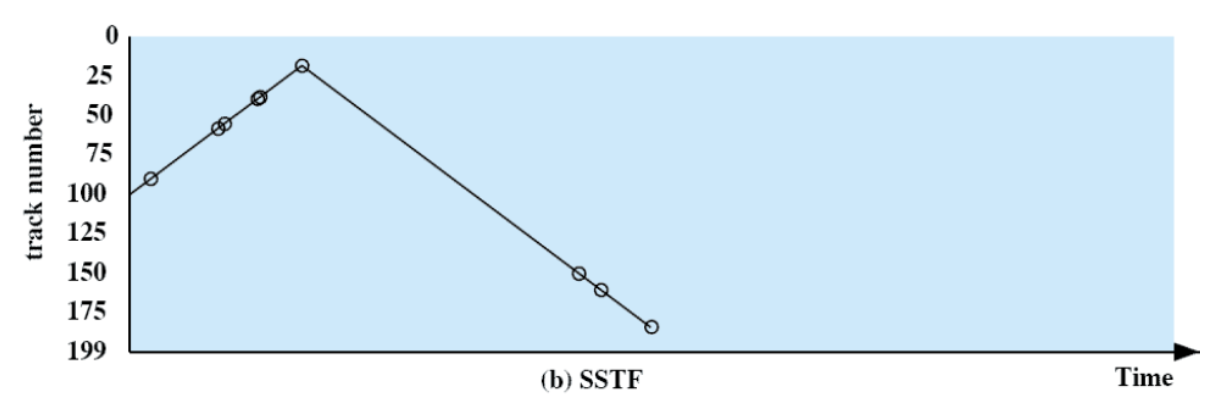
SSTF (Shortest Seek Time First)
Politica di scheduling utilizzata per la gestione delle richieste di I/O nei dischi rigidi. Questo approccio mira a ottimizzare le prestazioni minimizzando il tempo di ricerca della testina del disco.
É necessario conoscere la posizione della testina per determinare l’ordine corretto di operazioni per ridurre il movimento della testina.
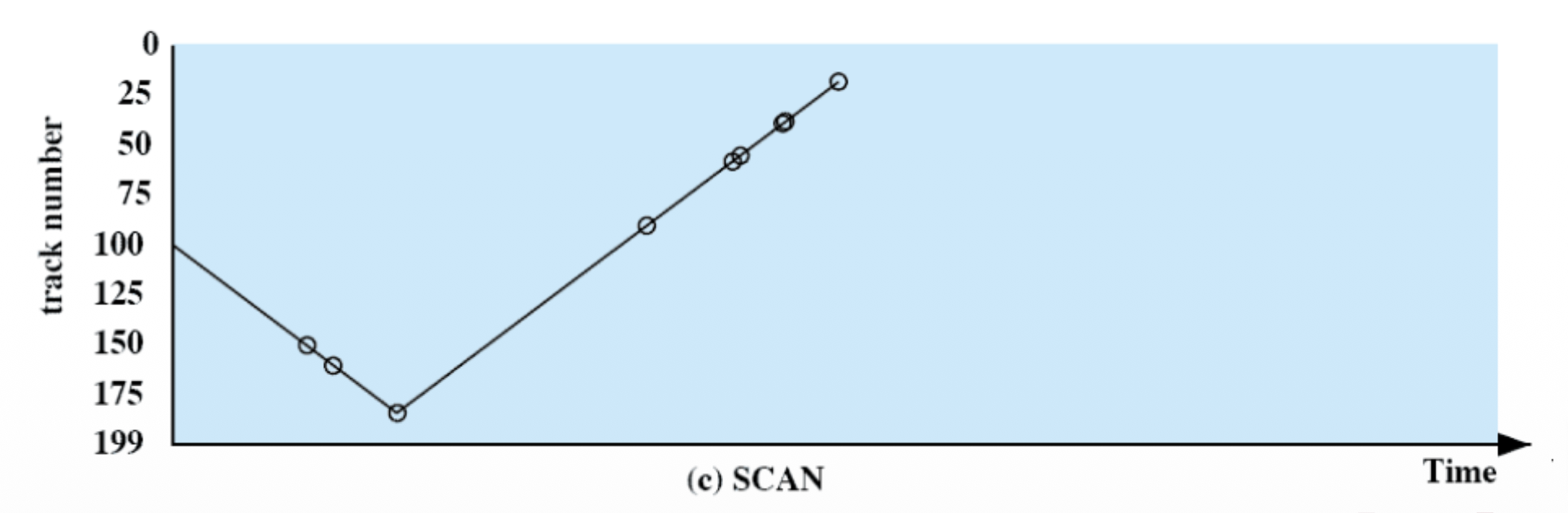
SCAN
Anche noto come algoritmo “Elevator”, è un metodo di scheduling dei dischi per ottimizzare l’accesso alle richieste di lettura e scrittura nei dischi rigidi.
Si scelgono le richieste in modo tale che il braccio si muova sempre in un verso, e poi torni indietro
Nota: movimento simile al funzionamento di un ascensore.
Caratteristiche:
- Niente starvation delle richieste
- Poco Fair
Poco Fair perché favorisce le le richieste che si trovano nelle vicinanze della testina, e specialmente quelle vicino ai bordi del disco (visto che questo movimento porta la testina a spende più tempo lungo i bordi).
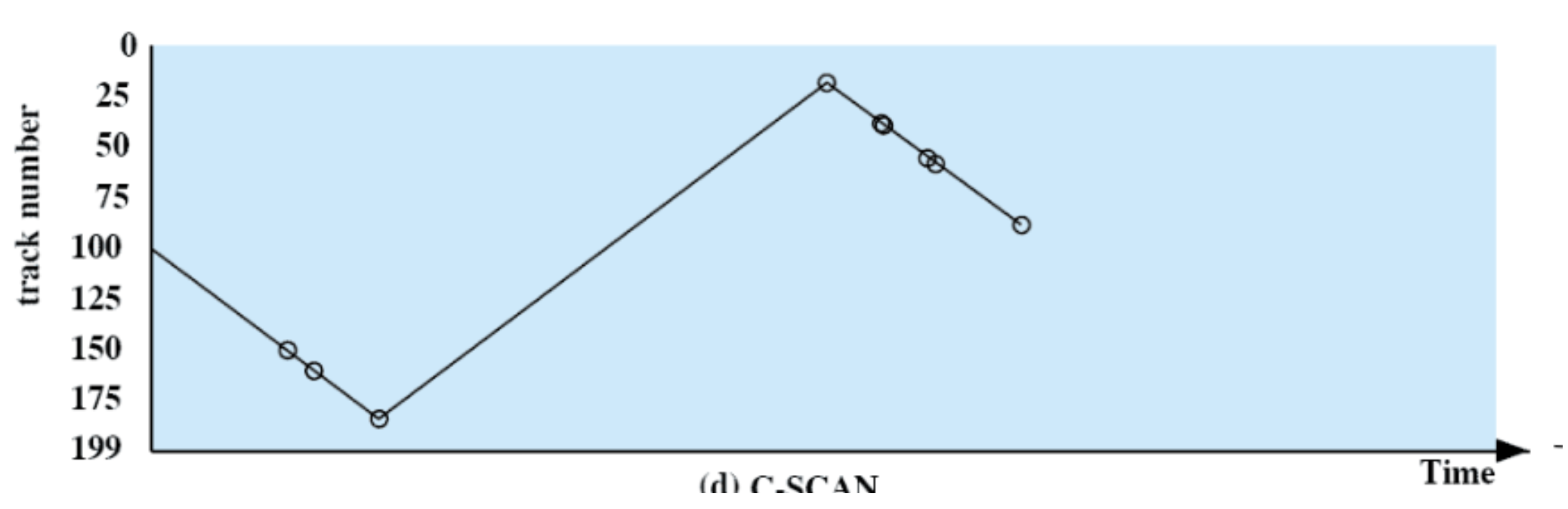
C-SCAN
Politica di Scheduling simile a SCAN ma che è fair.
Per fare ciò nella marcia indietro non si accettano richieste.
FSCAN
Politica di Scheduling che evolve SCAN rendendolo fair, introducendo due code anziché una sola.