Dizionari in c
- La struttura dizionario in C non esiste, per queste adesso la ricreeremo basandoci sulle caratteristiche dei dizionari Python
- Questo ci permetterà di capire come funziona un dizionario e il motivo pre cui la maggior parte delle operazioni su un dizionario richiedono tempo medio costante
Caratteristiche dei dizionari (python):
Funzioni:
- Creazione dizionario vuoto
- Inserimento di una coppia chiave valore (item)
- Modifica di un valore associato ad una chiave
- Cancellazione di una coppia (item)
- Lettura di un valore associato ad una chiave
- Ricerca, controllare se una chiave è presente o no
oss: in python tutte queste operazioni hanno costo costante nel caso medio tranne operatore di iterazione ha costo lineare, leggi Introduzione semplicistica alla complessità algoritmica in python
Struttura Dato:
oss: possiamo costruire un dizionario utilizzando sia un array “normale” sia utilizzando le liste concatenate Linked List (Struttura Dati),
- in entrambi i casi non sarebbe possibile avere un costo medio costante per la maggior parte delle operazioni)
Esempio utilizzando lista concatenata
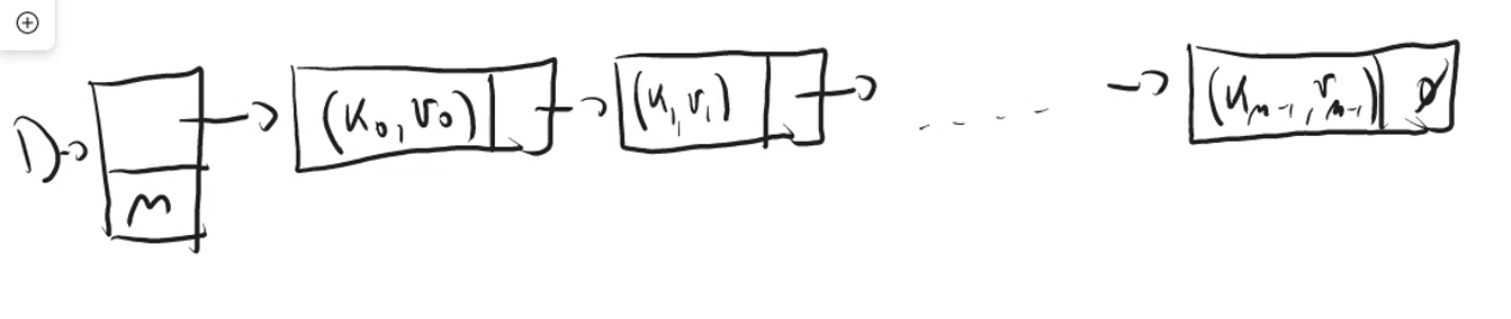
Nota
Costo medio è uguale a costo peggiore diviso numero di elementi
Costi:
-
search(k):
- input chiave, output se è presente o no
- Costo: peggiore: O(n^2), medio: O(n)
-
set(k ,v):
- input: chiave e valore, output: associa chiave a valore se chiave non presente nel dizionario, se presente cambia il valore associato alla chiave con quello nuovo
- Costo dipende dalla search
-
get(k):
- input: chiave, output valore associato alla chiave
- Costo: dipende dalla search
-
del(k):
- input: chiave, output cancella coppia associata alla chiave
- costo: dipende dalla search
Chiaramente in python i dizionari non sono implementati in questo modo
Implementazione Stile Python
Strutture:
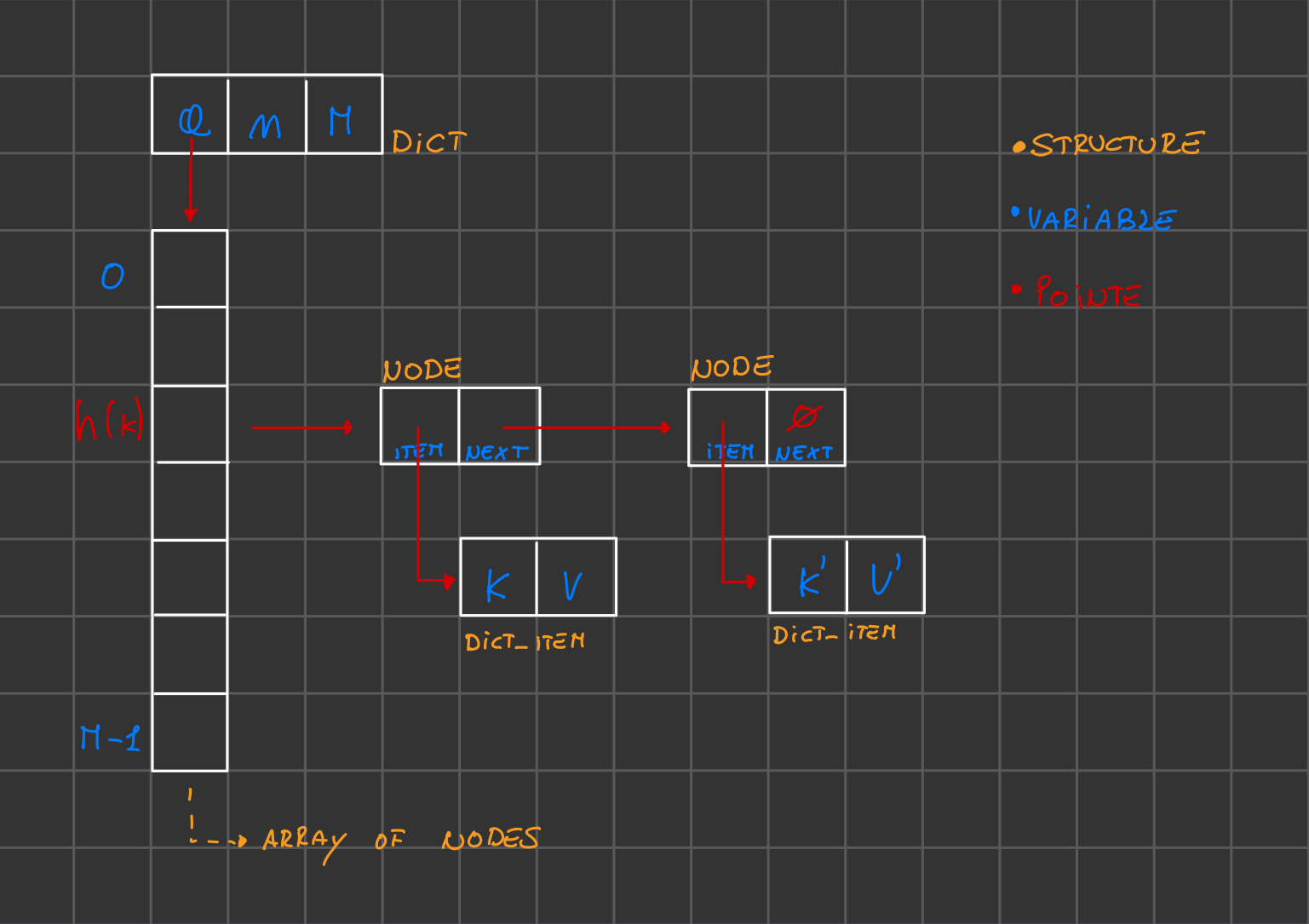
struct dict_item {
char *k; //key
float v; //value
}; typedef struct dict_item dict_item;
struct node {
dict_item info; // coppia di valori
struct node *next; // nodo successivo
}; typedef struct node node;
struct dict {
node **a; // array di nodi
int n; // dimensione
int M; // capacità dell'array
}; typedef struct dict dict;Funzioni
Funzione Hash
Caratteristiche di una funzione hash:
- deterministica: per uno stesso input restituisce lo stesso output
- veloce
- distribuisce bene le chiavi nell’array
oss: esistono diverse funzioni hash più o meno complesse, in questo caso utilizziamo una funzione hash molto basilare ma funzionale.
Descrizione: funzione che prendendo in input una chiave restituisce l’indice dell’array contenente il puntatore alla lista di trabocco associata a quella chiave
- Input: dizionario (d), stringa (chiave)
- Output: numero intero (ovvero l’indice della array )
- Costo:
Funzionamento:
- prendiamo la chiave e la dividiamo in caratteri
- facciamo l’ XOR bit a bit dei caratteri
- Calcoliamo il modulo del risultato per capacità dell’array in modo che non sia mai superiore all’indice massimo delle array (M)
int h(dict d, char *k){
// funzione hash
int hash_val = 0; //inizializziamo valore a 0
for(int i=0; k[i] != '\0'; i++){ //divione dei caratteri
hash_val = hash_val ^ k[i]; //XOR bit-a-bit
}
return hash_val % d.M;
// Modulo hash_value per la dimensione dell'array(M)
// sicurezza di non avere inice superiore alla dimensione dell array
}Funzione ridimensionamento del dizionario:
-
Descrizione:
- funzione che prende in input un dizionario e la nuova dimensione che gli vogliamo dare
- deve creare un nuovo dizionario, e spostare tutti gli elementi del vecchio nel nuovo (calcolando i nuovi indici hash)
-
Input: dizionario (d), int (nuova dimensione del dizionario)
-
Output: puntatore alla nuovo dizionario
-
Costo:
- h costo costante
- il resto della funzione ha comunque costo costante se la funzione hash distribuisce uniformemente le coppie di valori nelle liste di trabocco
-
*Funzionamento:
- Calcoliamo l’indice del primo nodo della lista di trabocco con la funzione hash
- Troviamo il puntatore al primo nodo della lista di trabocco (attraverso l’indice precedentemente calcolato)
- Scorriamo tutta la lista di trabocco finche non troviamo la chiave
- return = puntatore al nodo in cui è contenuta la chiave interessata
node *dict_search(dict d, char *k){
int p = h(d, k);
// troviamo posizione della lista nell array
node *q = d.a[p];
// troviamo il puntatore al primo nodo della lista
while(q != NULL && strcmp(k, q->info.k)){
//scorriamo la lista finche non raggiongiamo la fine (NULL) o finche non troviamo la chiave
q = q->next;
}
return q;
}dict_search:
-
Descrizione: funzione che restituisca un puntatore al nodo in cui è contenuta la chiave che stiamo cercando o NULL se non presente
-
Input: dizionario (d), stringa (chiave)
-
Output: puntatore al nodo in cui è contenuta la chiave o NULL se non presente
-
Costo:
- h costo costante
- il resto della funzione ha comunque costo costante se la funzione hash distribuisce uniformemente le coppie di valori nelle liste di trabocco
-
*Funzionamento:
- Calcoliamo l’indice del primo nodo della lista di trabocco con la funzione hash
- Troviamo il puntatore al primo nodo della lista di trabocco (attraverso l’indice precedentemente calcolato)
- Scorriamo tutta la lista di trabocco finche non troviamo la chiave
- return = puntatore al nodo in cui è contenuta la chiave interessata
node *dict_search(dict d, char *k){
int p = h(d, k);
// troviamo posizione della lista nell array
node *q = d.a[p];
// troviamo il puntatore al primo nodo della lista
while(q != NULL && strcmp(k, q->info.k)){
//scorriamo la lista finche non raggiongiamo la fine (NULL) o finche non troviamo la chiave
q = q->next;
}
return q;
}dict_init:
- Descrizione: funzione che inizializza un dizionario vuoto di capacità dichiarata (M)
- Input: capacità dell’array
- Output: puntatore al dizionario
- Costo:
oss: ho deciso che sia obbligatorio inserire una capacità maggiore di zero
dict dict_init(int M){
// inizializza un dizionario vuoto con capacità M
if (M < 1) M < 1; // se M < 1, la capacità dell'array è 1
dict d;
d.a = malloc(M*sizeof(node*));
d.n = 0;
d.M = M;
for (int i = 0; i < M; i++){
// inizializzo tutti i puntatori a NULL (dizionario vuoto)
d.a[i] = NULL;
}
return d;
}in0:
- Descrizione: funzione che inserisce un nuovo nodo all’inizio di una lista a trabocco, nodo che contiene una coppia di chiave valore (e)
- Input: primo nodo di una lista trabocco (nd), dict_item (e)
- Output: nuovo primo nodo della lista a trabocco
- Costo: costante
node *in0(node *nd, dict_item e){ //costo: O(1)
//un nuovo nodo all'inizzio di una lista a trabocco
node *p = malloc(sizeof(node));
// alloco spazio per il nuovo nodo
p->info = e;
//oss: stiamo creando un alias di dict_item (e) e non una copia
p->next = nd;
// il nuovo nodo punta al primo elemento della lista
nd = p;
// il primo elemento della lista diventa il nuovo nodo
return nd;
}dict_set:
- Descrizione: funzione che inserisce una coppia chiave valore nel dizionario se non presente, se la chiave è già presente aggiorna il valore associato alla chiave
- Input: dizionario (d), coppia chiave valore (item)
- Output: ---
- Costo:
- h costo costante
- dict_search costo costante (se liste del dizionario sono di dimensione costante)
- in0 costo costante
- resize lineare con il numero di elementi dell’ dizionario(n)
void dict_set(dict d, dict_item e){
int p = h(d, e.k);
// calcolo l'indice dell'array in cui inserire l'elemento
node *nd = dict_search(d, e.k);
// cerco se la chiave è già presente nel dizionario
if (nd != NULL) // se la chiave è presente nel dizionario
nd->info.v = e.v; // aggiorno il valore
else { // se la chiave non è presente nel dizionario
d.a[p] = in0(d.a[p], e);
//inserisco un nuovo nodo
d.n++; // aggiornamento numero di elementi
}
if(d.n/d.M > 4) // se il fattore di carico è maggiore di 4
d = dict_resize(d, 2*d.M+1);
// raddoppio la dimensione dell'array
return d;
}dict_del:
- Descrizione: funzione elimina una coppia chiave valore associata a una specifica chiave
- Input: dizionario (d), chiave (k)
- Output: ---
- Costo:
- h costo costante
- ricerca posizione chiave nella lista costante se elementi ben suddivisi nelle liste di trabocco
- cancellazioni costanti
void dict_del(dict d, char *k){
int p = h(d, k); // calcolo l'indice dell'array i
node *q = d.a[p]; // puntatore al primo nodo della lista
node *q_prec = NULL; // inizializzazione puntatore al nodo precedente a q
while(q != NULL && strcmp(k, q->info.k)){
//scorriamo la lista finche non raggiongiamo la fine (NULL) o finche non troviamo la chiave
q_prec = q;
q = q->next;
}
if(q != NULL){ // se la chiave è presente nel dizionario
if(q_prec == NULL)
// se il nodo da eliminare è il primo della lista
d.a[p] = q->next;
// il primo nodo diventa il successivo di q
else // se il nodo da eliminare non è il primo della lista
q_prec->next = q->next;
// il nodo precedente punta al successivo
free(q); // libero lo spazio occupato dal nodo eliminato
d.n--;
}
}