L’albero minimo di copertura è un albero che collega tutti i nodi di un grafo con il minor costo possibile, dove costo si intende la somma del peso di tutti gli archi che uilizziamo.
Nel mondo reale sarebbe come creare una rete ferroviaria che collega tutte le stazioni usando il minor numero possibile di kilometri di ferrovie, questo non assicura che si colleghino le stazioni con i percorsi più brevi, ma ci permette di risparmiare sulle ferrovie utilizzate.
Osservazioni
Potrebbe contenere cammini non minimi.
Albero dei cammini minimi assicura che tutti i nodi siano connessi con i percorsi con il costo più basso, invece l’albero di copertura minima assicura che tutti i nodi sono connessi tra di lore e che questo venga fatto con il minor costo possibile.
L’albero è un grafo aciclico, se ci fosse un ciclo significherebbe che si potrebbe ridurre il costo rimuovendo un arco superfluo.
Algoritmo di Kruskal
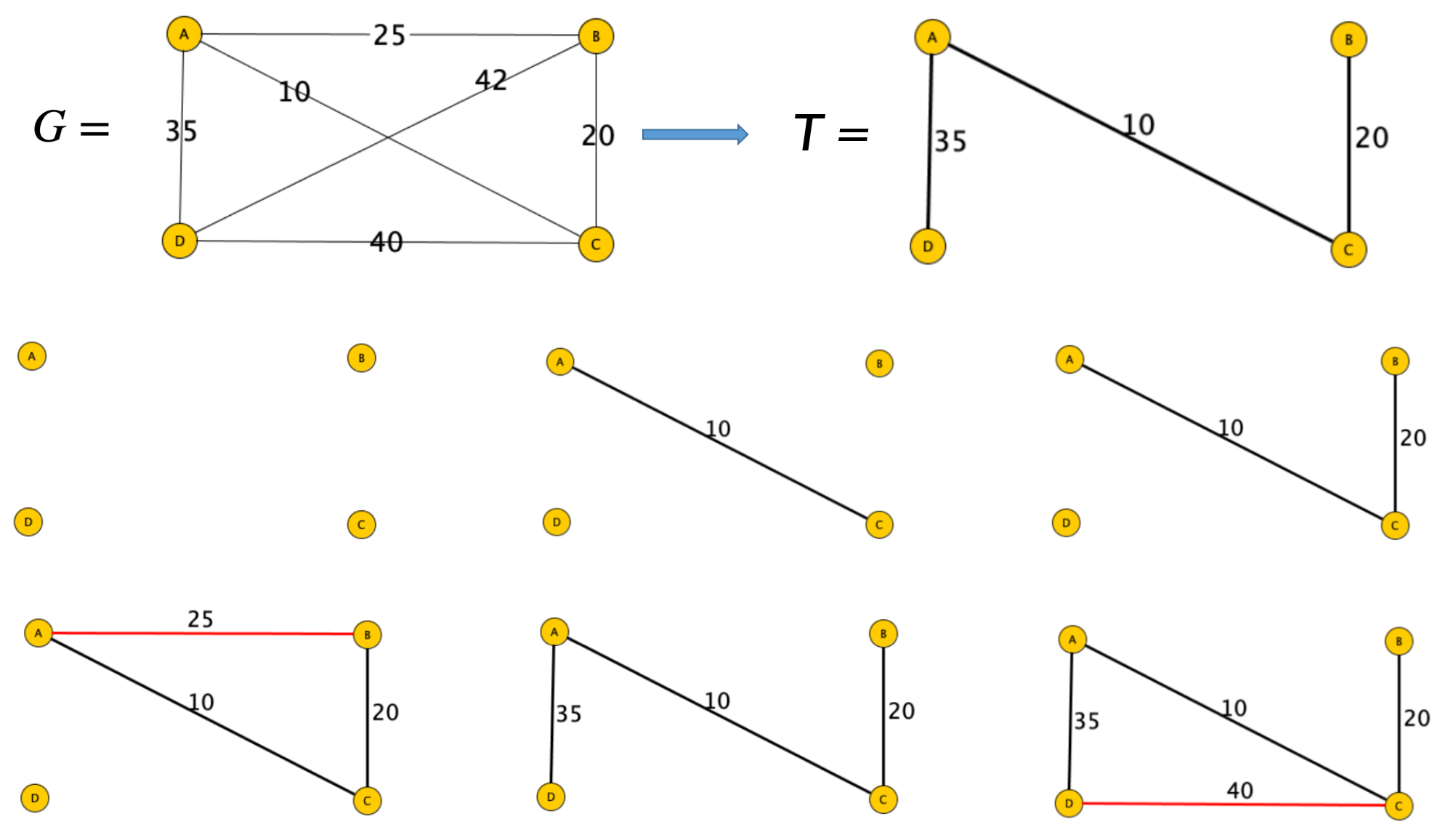
Un algoritmo utilizzato per risolvere questo problema è l’algoritmo di Kruskal:
Partendo dal grafo in input G creiamo un grafo T che contiene tutti i nodi di G ma nessun arco.
Considera uno dopo l’altro gli archi di G in ordine di costo crescente.
Partendo da un nodo iniziale percorriamo gli archi del grafo G creando un percorso di costo crescente.
Ad ogni iterazione controlliamo se è possibile aggiungere a T l’arco che stiamo analizzando senza creare un ciclo.
Se il nuovo arco non crea un ciclo allora lo inseriamo in T.
L’algoritmo rientra perfettamente nel paradigma della tecnica greedy:
La sequenza di decisioni irrevocabili, infatti per ciascun arco di G si decide se inserirlo o meno in T. Una volta effettuata la decisione non è possibile revocarla.
Le decisioni vengono prese in base ad un criterio “locale”, se l’arco preso in analisi crea ciclo in T non viene inserito, in caso contrario lo prendi in quanto è il meno costoso a non creare cicli tra gli archi che restano da considerare.
Implementazione non Ottimizzata
def kruskal(G): # Creare una lista con gli archi pesati di `G` E = [(c, u, v) for u in range(len(G)) for v,c in G[u] if u<v] # Ordinare gli archi in ordine crescente di peso E.sort() # Per ogni arco, inseriamolo nel grafo se non crea un ciclo T = [[] for _ in G] for c, u, v in E: if not conessi(u, v, T): T[u].append(v) T[v].append(u) return T
def conessi(u, v, T): ''' esegue una visita nel garfo `T` a partire da `u` e restituisce True se nel corso della visita raggiunge `v`, False altrimenti ''' visitati = [0]*len(T) return DFSr(u, v, T, visitati)def DFSr(a, b, T, visitati): visittai[a] = 1 for z in T[a]: if z == b: return True if not visitati[z]: if DFSr(z, b, T, visitati): return True return False
Costo
L’ordinamento costa O(mlogm) che nel caso peggiore è O(mlogn2)=O(mlogn).
Il for è ripetuto m volte e determinare se i due nodi u e v sono connessi (funzione connessi) ha costo O(n), portando il costo totale del for a O(n⋅m)
Quindi il costo totale è O(mlogn)+O(m⋅n)=O(m⋅n)
UNION-FIND
Il costo elevato della versione appena vista dipende fatto che utilizziamo la funzione connessi per determinare se due nodi sono uniti da un percorso.
Per ridurre questo costo utilizziamo la struttura dati UNION-FIND per determinare efficientemente se i due nodi appartengono alla stessa componente connessa. Grazie a questa tecnica possiamo ridurre il costo a O(mlogn).
Definizione
La UNION-FIND è una struttura dati utilizzata per rappresentare una collezione C di componenti connesse, permette di effettuare le due seguenti operazioni:
Union(A,B,C) modifica la struttura dati C fondendo la componente A alla componente B e ritorna il “nome” della nuova componente connessa, in tempoO(1).
Find(x, C) restituisce il nome della componente connessa in C contente il nodo x, in tempoO(logn).
Create(HG) inizializza la struttura dati Union-Find generata partendo da un grafo, in tempoΘ(n) .
def kruskal1(G): E = [(c,u,v) for u in range(len(G)) for v,c in G[u] if u<v] E.sort() # sort degli archi dal meno costosa al più costoso T = [[] for _ in G] C = Crea(T) for c, u, v in E: cu = FIND(u, C) cv = FIND(v, C) if cu != cv: T[u].append(v) T[v].append(u) Union(cu, cv, C) return T
Funzione Crea
Funzione che partendo da un grafo G crea la struttura dati Union-Find ovvero un vettore C.
La funzione inizializza un albero per ogni componente connessa, ogni elemento del vettore C in posizione i rappresenta il padre che il nodo i del grafo ha nel albero della sua componete connessa.
def Crea(G): C = [ (i, p) for i in range(len(G))] return C
Funzione Find
Funzione che data un nodo x e una Union-Find C ritorna il “nome” della componente connessa a cui x appartiene.
Per nome della componente connessa si intende il nodo radice del albero che rappresenta la componente connessa di x.
Per trovare questa radice ci bassa “inseguire” i padri in C (C può essere visto come un vettore dei padri) fino a quando troviamo un nodo che ha come padre se stesso.
def Find(u, C): while u != C[u]: u = C[u] return u
Funzione Union
def Union(a, b ,C) tota, totb = C[a][1], C[b][1] if tota >= totb: C[a] = (a, tota + totb) C[b] = (a, totb) else: C[a] = (b, tota) C[b] = (b, tota + totb)