Gli algoritmi greedy sono una classe di algoritmi che effettuano scelte ottimali a livello locale nella speranza di trovare una soluzione ottimale globale.
Le decisioni vengono prese in base ad un criterio “locale”, ovvero ad ogni step dell’algoritmo, si effettua la miglior scelta possibile al momento.
Una volta effettuata una decisione non è possibile revocarla.
Esempio 1 (selezione di attività)
Per illustrare il progetto e l’analisi di un algoritmo greedy consideriamo ora un problema piuttosto semplice chiamato selezione di attività.
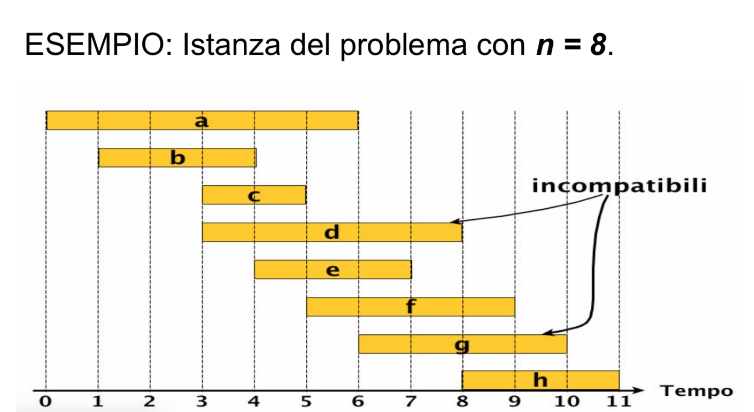
In questo problema abbiamo una lista di n attività:
Ogni attività è rappresentata da una coppia che indica il suo tempo di inizio e fine
Due attività si dicono compatibili se la loro esecuzione non si sovrappongono
Il nostro obiettivo è trovare un sottoinsieme di attività da eseguire che abbia la massima cardinalità.
Prendiamo il seguente insieme:
In questo caso osservando l’esempio è facile convincersi che l’insieme di attività compatibili di cardinalità maggiore è {b,e,h}.
Volendo utilizzare il paradigma greedy dovremmo trovare una regola, semplice da calcolare, che ci permetta di effettuare ogni volta la scelta giusta. Per questo problema ci sono diverse potenziali regole di scelta:
Prendere l’attività compatibile che inizia prima.
Prendere l’attività compatibile che dura di meno.
Prendere l’attività compatibile che ha meno conflitti con quelle ancora da prendere.
La regola giusta da scegliere in questo caso è scegliere l’attività compatibile che finisce prima.
Dimostrazione
Implementazione
def selezione_a(lista): lista.sort( key = lambda x: x[1] ) libero = 0 sol = [] for inizio, fine in lista: if libero < inizio: sol.append((inizio, fine)) libero = fine return sol
Complessità:
Ordinare la lista delle attività costa .
Il for viene eseguito n volte e il costo di ogni iterazione è O(1).
Quindi il costo totale è Θ(nlogn).
Pre-Processing
In questa implementazione, effettuiamo un pre-processing.
Invece di cercare, ad ogni iterazione, l’attività che finisce prima nella lista - operazione che richiede O(n) - effettuiamo un pre-processamento ordinando le attività nella lista da quelle che finiscono prima a quelle che finiscono più tardi, con un costo di Θ(nlogn).
Poi, in ogni iterazione, basta prendere il primo elemento nella lista che non abbiamo già visto.
Esempio 2 (assegnazione di attività)
Consideriamo ora questo nuovo problema noto come assegnazione di attività:
Abbiamo una lista di attività, ciascuna caratterizzata da un tempo di inizio ed un tempo di fine. Le attività vanno tutte eseguite e vogliamo assegnarle al minor numero di aule tenendo conto che in una stessa aula non possono eseguirsi più attività in parallelo.
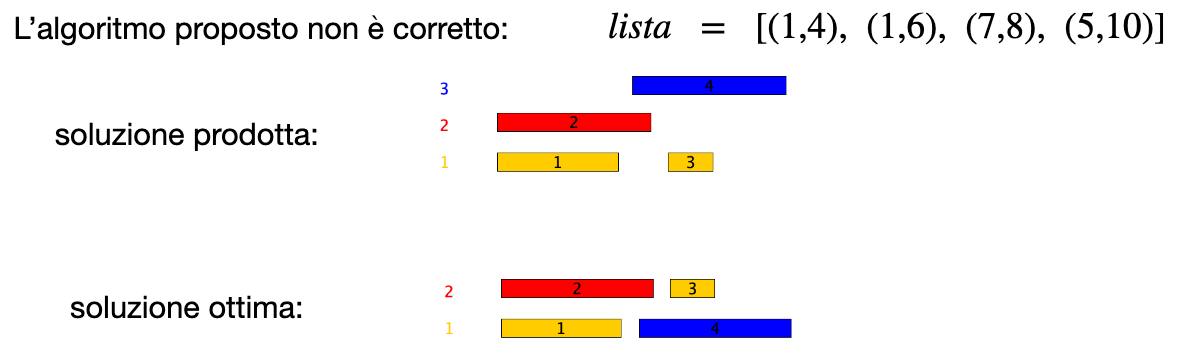
Soluzione non Ottima
Un possibile algoritmo greedy si basa sull’idea occupare aule finché ci sono attività da assegnare. Ogni aula, una volta inaugurata, assegnamo il maggior numero di attività non ancora assegnate che è in grado di contenere.
Soluzione Ottima
Una possibile soluzione che produce l’output ottimale è:
Creiamo una lista di liste dove ogni lista corrisponde ad un’aula, inizialmente conterrà una sola aula senza lezioni.
Iteriamo sulla lista di attività ed ad ogni iterazione estraiamo da questa l’attività che inizia prima.
Se è presente un’aula che può contenerla la assegnamo a quell’aula, altrimenti ne creiamo una nuova
Per contenere i costi utilizziamo una Heap:
from heapq import heappop, heappushdef assegnazioneAule(lista): Sol = [[]] H = [(0,0)] lista.sort() for inizio, fine in lista: libera, aula = H[0] if libera < inizio: Sol[aula].append((inizio, fine)) heappop(H) heappush(H, (fine, aula)) else: Sol.append([(inizio, fine)]) heappush(H, (fine, len(Sol)-1)) return Sol
Come complessità abbiamo:
Ordinare la lista costa Θ(nlogn)
Eseguiamo il for n volte e all’interno del for al caso pessimo eseguiamo un’estrazione dall’heap e un inserimento nell’heap entrambe che costano \Theta (\log n)$$ quindi anche il for richiede \Theta (n \log n)$