Introduzione
Quando le chiavi ammettono un ordine, è più conveniente utilizzare un organizzazione fisica che tenga conto di questa caratteristica dei dati.
Ordinamenti
La maggior parte dei data type hanno un ordinamento
- Valori numerici per confronto
- Stringhe ordine lessicografico
Se abbiamo dati composti da campi multipli, si ordina il primo campo, poi il secondo e cosi via (oss: l’ordinamento lessicografo si comporta allo stesso modo in cui i vari simboli rappresentano i campi)
Algoritmo di Ordinamento
Le condizioni appena viste sono equivalenti al seguente algoritmo:
- Si pone n=1
- Si confrontano i simboli nella posizione n-esima della stringa:
- Se una delle due non possiede l’elemento n-esimo allora è minore dell’altra e terminiamo
- Se entrambe le stringhe non possiedono l’elemento n-esimo allora sono uguali e l’algoritmo termina
- Se i simboli sono uguali si passa alla posizione successiva
- Se questi sono diversi, il loro ordine è l’ordine delle stringhe
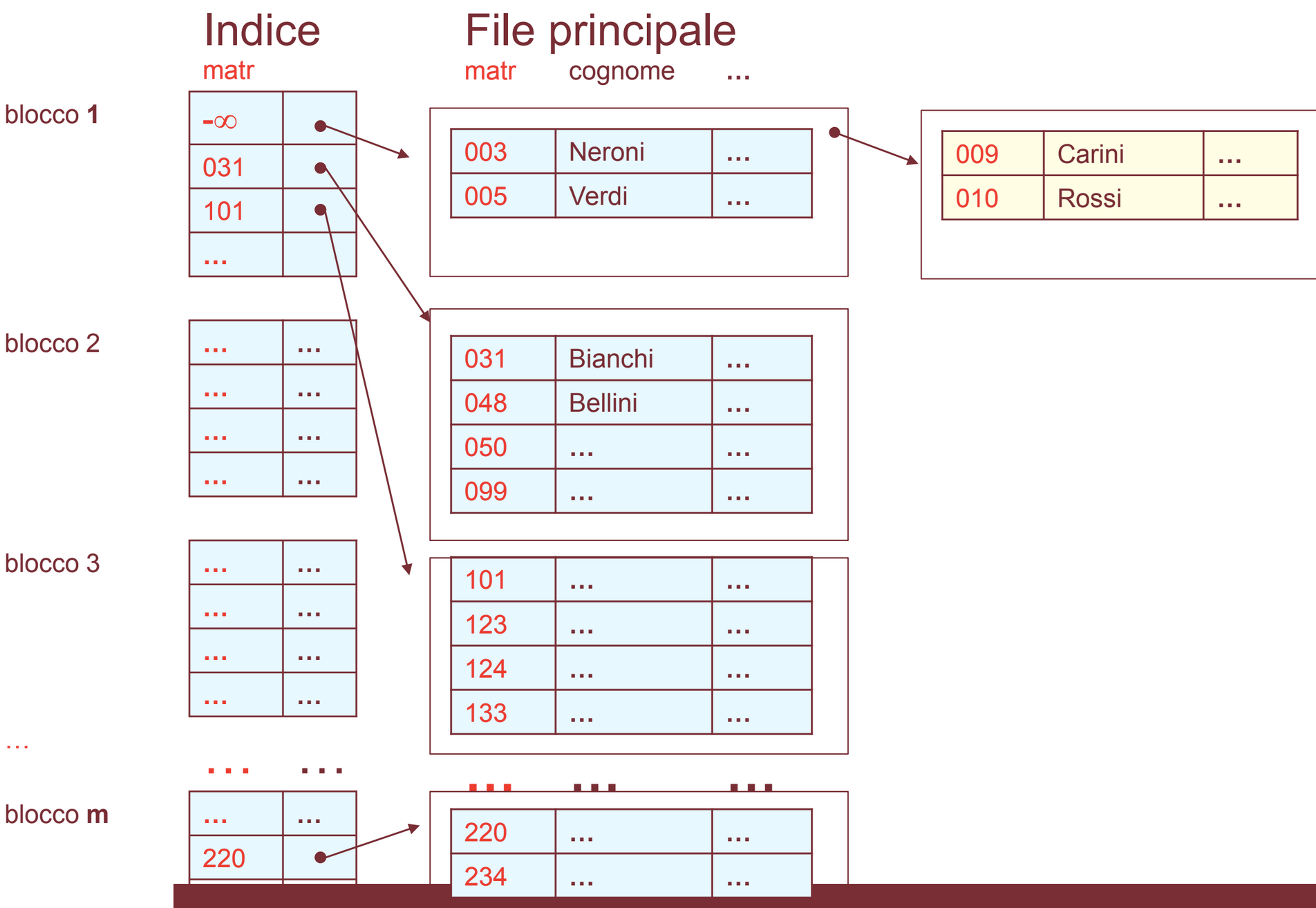
File con Indice Sparso
Un esempio di file and indice sparso può essere un file ISAM (Indexed Sequential Access Method)
Questa struttura è composta da due file:
File Principale
In questo file i record sono ordinato in base alle chiave, dalla più piccola alla più grande.
oss: È importante lasciare dello spazio libero in ogni blocco, ad esempio 20%, per permettere di inserire nuovi elementi in futuro.
File Indice
Il file indice contiene un record per ogni blocco del file principale, questi record sono composti da due campi:
- un puntatore
pad un blocco del file indice (indirizzo del blocco)- un valore
vche ricopre tutte le chiavi presenti nel blocco puntato dapQuesto a due implicazioni:
vdeve essere minore uguale di tutte le chiavi presenti nel blocco puntato dap- tutte le chiavi presenti nel blocco precedente a
pdevo essere inferiori avAnche i record del file indice sono ordinati dal più piccolo al più grande, utilizzando come valore di ordinamento la chiave.
Da Sapere:
- è una convenzione per la chiave del primo record del file indce.
- È importante lasciare dello spazio libero in ogni blocco, ad esempio 20%, per permettere di inserire nuovi elementi in futuro.
- Solitamente questo file ha una dimensione tale possa essere mantenuto tutto in memoria principale

Creazione dell’Indice
Il file indice viene creato nel modo seguente. Per ogni blocco del file principale viene creata una coppia costituita dal valore della chiave del primo record nel blocco e dall’indirizzo del blocco; l’unica eccezione è rappresentata dal primo blocco per il quale viene preso anziché il valore della chiave del primo record, un valore (denotato con ) che è più piccolo di qualsiasi valore che può essere assunto dalla chiave.
Accesso al File Principale
Per accedere ad un record del file principale con chiave k occorre ricercare nel file indice il record con il più grande valore v che ricopre k, cioè tale che:
v <= k
Questo significa che v deve rispettare una tra queste due condizioni:
- o
vla chiave dell l’ultimo il record del file indice - oppure la chiave del record successivo (
v') deve essere tale chek < v'
Una volta trovato il record del file indice con valore v utilizziamo il suo puntatore per ottenere il blocco del file principale. Ora è possibile ricercare nel blocco il record con chiave k.
Esempio
Ad esempio il record del file principale con chiave
090deve trovarsi nel blocco del blocco che ha come chiave del record più piccola031, dato che:
- il blocco precedente ha come chiave più piccola
003- e tutti i blocchi successivi hanno record chiavi superiori o uguali a
101Oppure il record con chiave
234deve trovarsi nell’ultimo blocco del file principale dato che nei precedenti i valori della chiave sono minori220.
Ricerca su file indice
Ricerca Binaria
Dato che il file indice è ordinato in base ai valori, la ricerca di un valore
vdel indice che ricopre una chiavakdel file principale può essere effettuata tramite la ricerca binaria, sui blocchi del file indice.Definiamo i blocchi del file indice con
Si fa un accesso al blocco e si confronta il valore
vdel primo record del blocco conk:
- Se
k = vabbiamo finito- Se
k < vallora si ripete il procedimento sui blocchi da a - Se
k > vallora si ripete il procedimento sui blocchi da (ricontrolliamo anche questo blocco dato che prima abbiamo controllato solo la prima chiave e non il resto del blocco)Ci si ferma quando troviamo
K = Voppure quando lo spazio di ricerca è ridotto ad un unico blocco, a questo punto si scansiona il blocco per trovare un valore nei record che ricoprek.Nel caso peggiore dopo accessi a memoria per la ricerca nel indice
+ 1accesso al blocco trovato.
Ricerca per Interpolazione
Questo metodo di ricerca è utile quando si conosce la distribuzione dei valori della chiave. A differenza della ricerca binaria, che divide sempre l’intervallo a metà, la ricerca per interpolazione cerca di stimare dove potrebbe trovarsi il valore cercato in base alla distribuzione dei dati.
Funzione f: La funzione
f(v1, v2, v3)è fondamentale per la ricerca per interpolazione. Essa calcola una posizione stimata div1all’interno dell intervallo[v2, v3]:
v1: il valore che stai cercando.v2: il valore della chiave dell’inizio dell’intervallov3: il valore della chiave della fine dell’intervalloLa funzione restituisce un indice
iche indica in quale bloccoBipotrebbe trovarsiv1.Procedura Ricerca:
Definiamo i blocchi del file indice con e
kcome la chiave del record del file principale da trovare.Per effettuare la ricerca per interpolazione del valore
ktra il bloccoB1eBn, prima di tutto utilizziamof(v1, v2, v3) con:
v1=kv2= la chiave del primo record contenuto inB1v3= la chiave del primo record contenuto inBnIl risultato della funzione è un indice
idi un blocco (Bi), ora confrontiamo il risultato conk:
- se
kè minore del valore della chiave nel primo record diBi, si ripete il procedimento sui blocchi precedenti ovvero su- Se
kè maggiore del valore della chiave nel primo record diBi, si ripete il procedimento sui blocchi successivi, ovvero suQuesto processo continua fino a quando non si restringe la ricerca a un unico blocco, a questo punto si scansiona il blocco per trovare un valore nei record che ricopre
k.Costo: È stato calcolato che la ricerca per interpolazione ha una costo sotto forma di accessi a memoria di circa dove è il numero di blocchi del file indice.
Osservazioni: Questo tecnica può essere utilizzata soltanto se si conosce una funzione
fche descrive la distribuzione dei valori, e questo è particolarmente difficile, ed inoltre questa tecnica non è compatibile con utilizzi che alterano la composizione dei dati nel tempo.
Inserimento
Per inserire un nuovo record con chiave k all interno del file principale, prima di tutto dobbiamo ricercare in quale blocco Bi del file principale va in inserito il nuovo record. Per questo possiamo effettuare una ricerca.
Se lo spazio nel blocco è sufficiente allora il record viene inserito in modo tale da rispettare l’ordinamento (quindi spostando eventualmente record con chiave maggiore).
Se lo spazio nel blocco é in-sufficiente allora possiamo usare 3 strategie:
1. se nel blocco successivo () c’è spazio allora spostiamo in il più grande record presente in (tenendo in considerazione anche il nuovo record). Il record spostato diventa il primo record di e, pertanto, il record del file indice che contiene il puntatore a deve essere modificato con il nuovo valore.
2. se nel il blocco successivo () non c’è spazio o non esiste ( è l’ultimo blocco) e nel blocco precedente () c’è spazio, allora spostiamo in il piccolo record presente in . Il record del file indice che contiene il puntatore a deve essere modificato con il nuovo valore.
3. se nel il blocco successivo () non c’è spazio o non esiste ( è l’ultimo blocco) e nel blocco precedente () non c’è spazio o non esiste ( è il primo blocco) allora è necessario richiedere un nuovo blocco che seguirà e ripartire i record di tra e il nuovo blocco; occorre anche inserire nel file indice il record relativo al nuovo blocco.
Cancellazione
Per cancellare un record dal file principale, occorre:
- Ricercare il record
- Cancellarlo
- Spostare i record nel blocco in modo da recuperare lo spazio lasciato libero
- Modificare i bit di “usato/non usato” nell’intestazione del blocco
Se il record cancellato è il primo record del blocco, occorre:
- Modificare nel file indice il record relativo al blocco
Se il record cancellato era l’unico record del blocco, occorre:
- Restituire il blocco al sistema
- Cancellare nel file indice il record relativo al blocco
In ogni caso, occorrerà modificare i bit di “usato/non usato” nelle intestazioni dei blocchi coinvolti.
Modifica
La procedura di modifica di un record del file indice varia in base a se dobbiamo modificare campi che coinvolgono la chiave oppure no.
Se la modifica riguarda campi non chiave allora dobbiamo:
- Il record viene semplicemente modificato
Se la modifica riguarda campi chiave allora dobbiamo:
- Cancellare il record
- Inserire un nuovo record nel file principale con i campi modificati
File principale con record puntati
Inizializzazione:
La fase di inizializzazione non differisce dal caso precedente, salvo che è preferibile lasciare più spazio libero nei blocchi per successivi inserimenti.
Ciò è dovuto al fatto che i record sono puntati e non possono essere spostati per mantenere l’ordinamento quando si inseriscono nuovi record.
Inserimento di nuovi record:
Se non c’è spazio sufficiente in un blocco B per l’inserimento di un nuovo record, occorre richiedere al sistema un nuovo blocco che viene collegato a B tramite un puntatore.
In tal modo, ogni record del file indice punta al primo blocco di un bucket e il file indice non viene mai modificato (a meno che le dimensioni dei bucket non siano diventate tali da richiedere una riorganizzazione dell’intero file).
Ricerca di un record:
La ricerca di un record con chiave v richiede la ricerca sul file indice di un valore della chiave che ricopre v e quindi la scansione del bucket corrispondente.
Cancellazione di un record:
La cancellazione di un record richiede la ricerca del record e quindi la modifica dei bit di cancellazione nell’intestazione del blocco.
Modifica di un record:
La modifica di un record richiede prima di tutto una ricerca del record poi il procedimento cambia si deve modificare un campo chiave oppure no.
Se la modifica non coinvolge campi della chiave, il record viene modificato e il blocco riscritto.
Se la modifica coinvolge campi delle chiave allora equivale ad una cancellazione seguita da un inserimento. In quest’ultimo caso, non è sufficiente modificare il bit di cancellazione del record cancellato, ma è necessario inserire in esso un puntatore al nuovo record inserito in modo che questo sia raggiungibile da qualsiasi record che contenga un puntatore al record cancellato.
Ordinamento del file principale:
Poiché non è possibile mantenere il file principale ordinato, se si vuole avere la possibilità di esaminare il file seguendo l’ordinamento della chiave, occorre inserire in ogni record un puntatore al record successivo nell’ordinamento.
Ecco le informazioni riguardanti i file ISAM con record puntati, riformattate per una maggiore leggibilità:
Caratteristiche dei record puntati
- Immobilità dei record: una volta inseriti, i record del file principale non possono essere spostati per mantenere l’ordinamento. Ciò significa che l’ordinamento stretto dei record è valido solo all’inizializzazione.
- Stabilità dei record indice: a differenza dell’ISAM classico, i record dei blocchi indice non vengono mai modificati. Ciò significa che la ripartizione degli intervalli delle chiavi rimane valida.
Gestione degli intervalli delle chiavi
- Condizione di validità: se un record indice punta ad un’area di dati con valori di chiave comprese tra
k1ek2, questa condizione deve rimanere valida. - Gestione degli overflow: se il blocco originario si riempie e arrivano nuovi record con valori di chiave compresi sempre tra
k1ek2, dobbiamo allocare un nuovo blocco che sarà linkato al blocco originario. Ciò crea una lista di blocchi di overflow che partono da quello originario, dove ognuno punta al successivo.
In sintesi, i record puntati non possono essere spostati per mantenere l’ordinamento, ma la ripartizione degli intervalli delle chiavi rimane valida. Quando si verificano degli overflow, si creano nuovi blocchi che sono linkati al blocco originario, creando una lista di blocchi di overflow.