Related
Introduzione
Nonostante la memoria sia sempre più economia e che quindi i computer hanno sempre più spazio a disposizione resta comunque molto importante gestirla.
Memoria = RAM
Naturalmente quando si parla di memoria si intende la memoria RAM (Random Access Memory), ovvero un tipo di memoria volatile utilizzata per memorizzare temporaneamente i dati e le istruzioni necessarie per l’esecuzione delle processi operazioni in corso.
Per evitare problemi nella scrittura di programmi, il sistema operativo si occupa della gestione della memoria, fornendo ai vari processi l’illusione di avere accesso all’intera memoria disponibile. Questo concetto è noto come memoria virtuale.
I processi operano come se avessero a disposizione tutta la memoria, mentre il sistema operativo si occupa di rendere realistica questa illusione. La gestione della memoria include anche lo swap di blocchi di dati dalla memoria secondaria. Tuttavia, questa operazione di input/output è ovviamente più lenta rispetto all’elaborazione del processore.
Pertanto, il sistema operativo deve pianificare lo swap in modo intelligente per massimizzare l’efficienza del processore. È fondamentale gestire la memoria in modo da mantenere un numero ragionevole di processi pronti all’esecuzione, evitando così di lasciare il processore inoperoso
Per ottenere tutto questo si devono rispettare questi requisiti:
Ci sono diversi metodi per la gestione della memoria:
Rilocazione
La rilocazione è un aspetto cruciale nella gestione della memoria da parte del sistema operativo, poiché consente ai programmi di essere eseguiti in posizioni di memoria diverse da quelle per cui sono stati originariamente progettati. Questo processo è fondamentale per garantire che i programmi possano funzionare correttamente, indipendentemente dalla loro posizione in memoria.
Traduzione degli Indirizzi
I riferimenti alla memoria nel codice sorgente, sia che si tratti di linguaggio assembly o di linguaggi compilati, sono detti logici e devono essere tradotti in indirizzi fisici “veri”. Questa traduzione può avvenire in due momenti:
- Preprocessing: Durante la fase di compilazione, gli indirizzi possono essere risolti e adattati in base alla posizione di caricamento prevista.
- Run-time: Se la traduzione avviene durante l’esecuzione, è necessario un supporto hardware, come un’unità di gestione della memoria.
Generazione del codice eseguibile
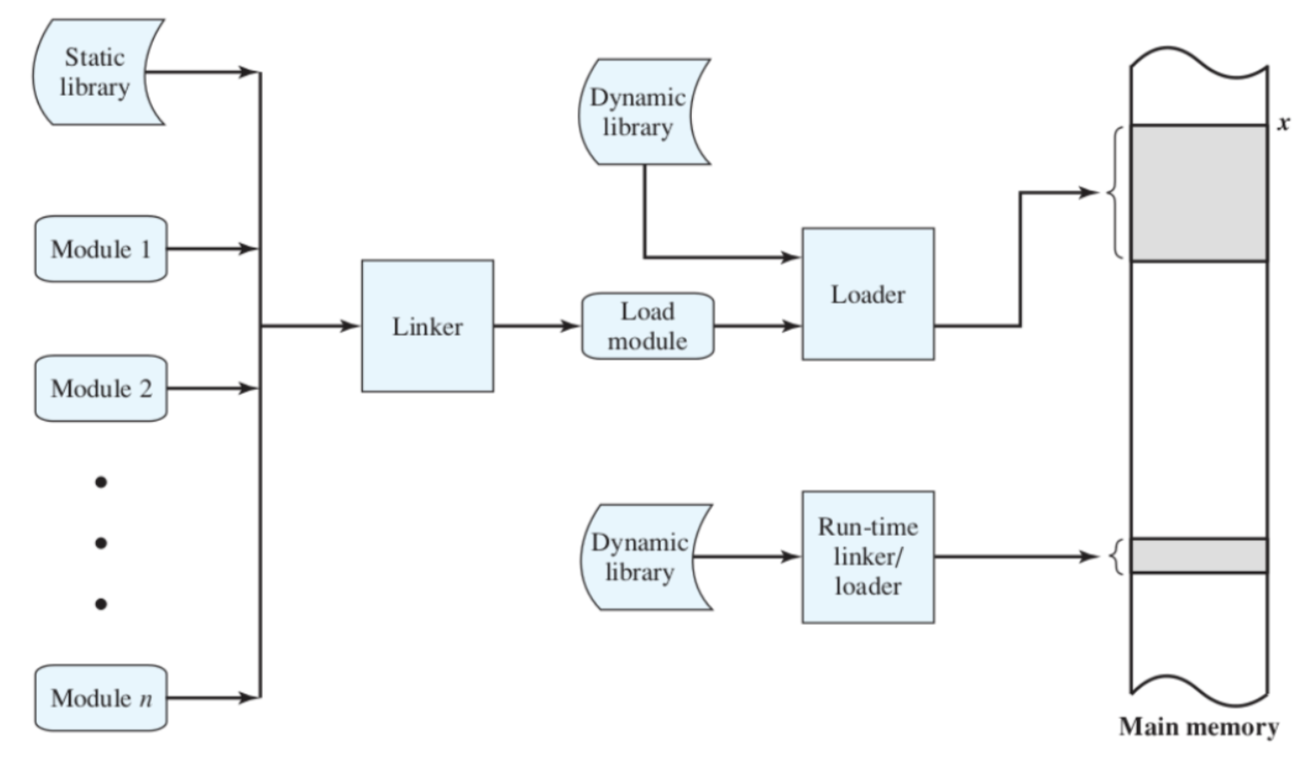
Il programmatore scrive i moduli e utilizza librerie statiche per creare programmi che vengono poi salvati nella memoria secondaria.
Il linker si occupa di compilare il codice, ovvero si occupa di collegare tutti questi moduli e librerie statiche, creando un load module che può essere salvato nella memoria secondaria.
Questo load module, può essere caricato in memoria principale per essere eseguito attraverso il loader, in questo procedimento potrebbe esserci il bisogno di utilizzare librerie dinamiche che vengono chiamate a tempo di esecuzione.
Vedi esempio C per Librerie Dinamiche: C Dynamic Libraries
Indirizzi
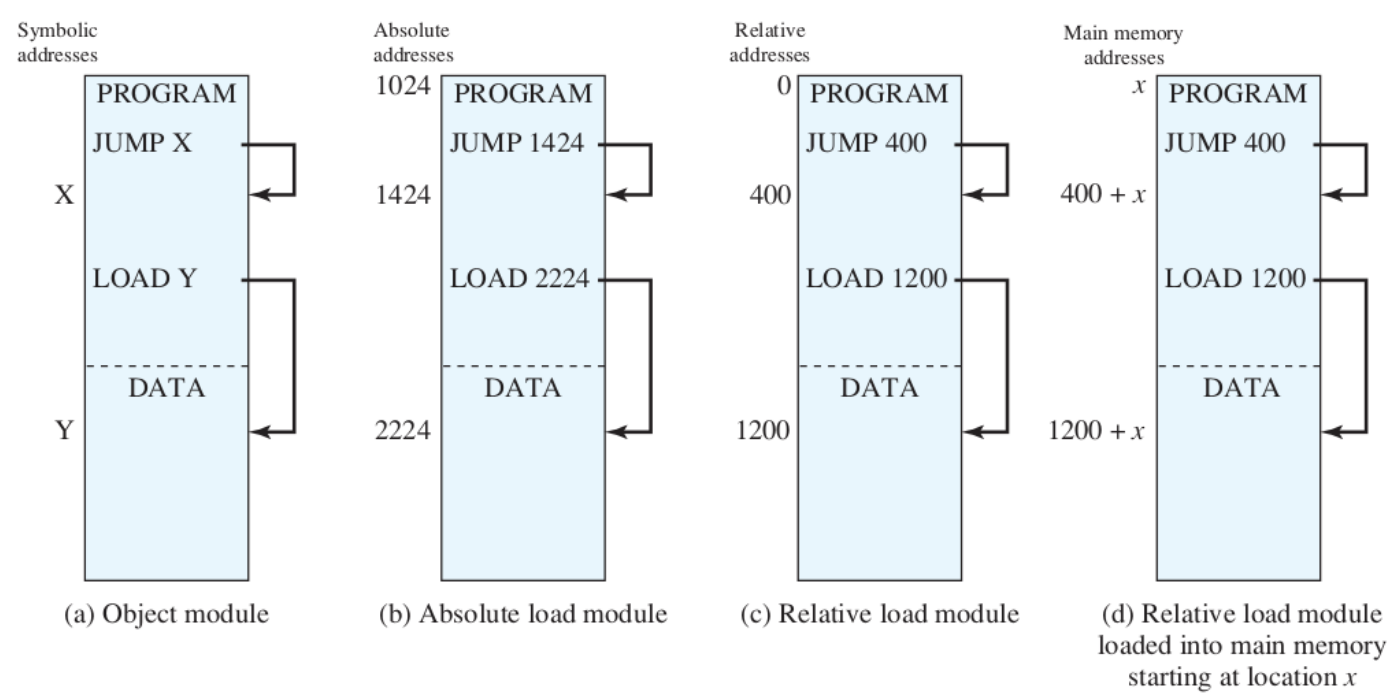
Indirizzi Logici (Simbolici):
- I riferimenti alla memoria sono rappresentati dal programmatore attraverso simboli (variabili), rendendo il programma indipendente dall’attuale posizionamento in memoria.
- Quando il codice viene eseguito, questi indirizzi devono essere “trasformati” in indirizzi “reali”. Possono essere utilizzati due metodi: indirizzi relativi o indirizzi fisici.
- Nell’immagine, questo è rappresentato dal caso
a.Indirizzi Relativi:
- Gli indirizzi relativi si riferiscono a posizioni di memoria in base a una distanza da un punto di riferimento noto, chiamato “base”. Ad esempio, se il punto di riferimento è 1000 e un indirizzo relativo è 20, l’indirizzo effettivo sarà 1020 (1000 + 20).
- Questa tecnica è particolarmente utile nei sistemi operativi moderni perché consente la rilocazione del codice. Ciò significa che un programma può essere caricato in diverse posizioni di memoria senza dover modificare il codice sorgente. Se un programma viene spostato in memoria, gli indirizzi relativi possono essere facilmente adattati per riflettere la nuova posizione, semplicemente aggiornando il punto di riferimento.
- Nell’immagine, il caso
cpotrebbe rappresentare un modulo isolato, dove gli indirizzi relativi sono calcolati rispetto all’inizio di quel modulo. Il casod, invece, rappresenta un modulo che è stato caricato in memoria in una posizione iniziale .Indirizzi Assoluti (Fisici):
I riferimenti sono espressi con la posizione effettiva in memoria.
Questa tecnica funziona soltanto se conosciamo esattamente dove posizionare il programma in memoria (e non può mai essere spostato), quindi non è utilizzata dai sistemi operativi moderni.
Nell’immagine, questo è il caso
b.oss: in realtà nei sistemi operativi moderni si utilizza la Paginazione e Segmentazione (semplice) e non gli indirizzi relativi.
Conversione in indirizzi assoluti
Per eseguire un codice c’è bisogni di “tradurre” gli indirizzi logici o relativi in indirizzi assoluti abbiamo due metodi:
Vecchissima soluzione (CTSS): gli indirizzi assoluti vengono determinati nel momento in cui il programma viene caricato (nuovamente o per la prima volta) in memoria.
- si può fare senza hardware dedicato
- non avviene in run-time
Soluzione più recente: Gli indirizzi assoluti vengono determinati nel momento in cui si fa un riferimento alla memoria.
- Serve hardware dedicato
- Avviene in run-time
Rilocazione a run-time
Base Register: indirizzo di partenza del processo Bounds Register: indirizzo di fine del processo
I valori di Base e Bounds Register (indirizzo fine processo) si trovano all’interno del PCB del processo e i loro valori vengono impostati durante il process switch, va sempre mantenuto il valore iniziale corretto del processo in esecuzione.

Protezione
I processi non devono poter accedere a locazioni di memoria di altri processi a meno che non siano autorizzati.
A causa della rilocazione non sappiamo in che zona di memoria si troverà il processo al momento di esecuzione e quindi anche qui abbiamo bisogno di un supporto hardware per effettuarlo a run-time.
Condivisione
Contrariamente alla Protezione, la Condivisione deve permettere la comunicazione tra alcuni processi per la condivisone di informazioni quando necessario. Per fare ciò si utilizzano zone di memoria condivise trai più processi.
In alcuni casi la condivisione è prevista dallo sviluppatore del programma, mentre in altri è il sistema operativo a deciderlo. Ad esempio quando eseguiamo lo stesso programma più volte (processi con lo stesso codice sorgente), conviene caricare il codice sorgente una sola volta in memoria e far accedere tutte le istanze a quel blocco.
Organizzazione Logica
A Livello Hardware la memoria è organizzata in modo lineare, ovvero blocco 1, blocco 2, ecc.
A Livello Software è tutto più astratto, i programmi sono scritti in moduli ed accedono alla memoria tramite variabili. Ogni modulo ha permessi diversi che possono vietarli operazioni come la scrittura o lettura e tanto altro.
Il Sistema operativo ha il compito di fare “da ponte” tra come è organizzata la memoria nell’hardware e come il software ad alto livello la vuole vedere.
Organizzazione Fisica
L’organizzazione fisica si occupa di gestire il flusso di dati tra la memoria principale (piccola e veloce) e la memoria secondaria (grande e lenta).
Questo compito non può essere lasciato al programmatore, poiché la memoria potrebbe non essere sufficientemente grande per contenere il programma e tutti i suoi dati. Per questo motivo, è necessario ricorrere all’overlaying.
Overlaying
L’overlaying è una tecnica che consente di posizionare più moduli nella stessa area di memoria, utilizzando il memory swap.
Consiste nell’alternare i programmi tra la memoria principale e quella secondaria, creando l’illusione di eseguire più programmi nella stessa zona della memoria principale.
Naturalmente, questo è un compito complesso che può essere gestito solo dal sistema operativo.