Related
Introduzione
Uno dei primi metodi per la gestione della memoria antecedente all’introduzione della memoria virtuale.
Al giorno d’oggi non più molto usato ma è comunque molto utile per capire la memoria virtuale e l’evoluzione moderna delle tecniche di partizionamento.
Ci sono diversi tipi di partizionamento:
Partizionamento Fisso
Il partizionamento fisso può essere diviso in due categorie: uniforme e variabile.
Partizionamento Fisso Uniforme
Metodo molto semplice che consiste nel dividere la memoria in partizioni di ugual grandezza, ed assegnare le partizioni libere a processi in esecuzione.
Il sistema operativo ha il potere di rimuovere un processo dalla partizione, per esempio se il processo in memoria non è in stato ready.
Problemi
- Inefficienza: se un processo è una dimensione minore rispetto alla grandezza delle partizioni comunque ne occuperà una intera.
- Difficolta per il programmatore: se un processo ha una dimensione superiore alla grandezza delle partizioni deve essere il programmatore ad utilizzare tecniche di riduzione del consumo di memoria, come l’overlaying.
- Inflessibilità: una volta avviato il sistema e scelta la grandezza (e quindi anche il numero) delle partizioni non è più possibile cambiarle.
Partizionamento Fisso Uniforme
Metodo che prova mitigare i problemi del partizionamento fisso uniforme, in particolare invece di dividere la memoria in partizioni di dimensioni tutte uguali, suddivide la memoria in partizioni progressivamente sempre più grandi.
Questo permette a processi “piccoli” di utilizzare partizioni piccole e a processi “grandi” partizioni più grandi.
oss: è comunque partizionamento fisso quindi la grandezza delle partizioni non può essere cambiato una volta partizionata la memoria.
Problemi
Oltre hai problemi del partizionamento uniforme che in questo caso sono solamente mitigati ma non completamente risolti, questa tecnica introduce delle piccole complessità, in particolare si deve scegliere in che partizione inserire un determinato processo, per questo sono stati creati gli algoritmi di posizionamento.
Inoltre se ci sono molti processi di uguale grandezza (esempio molti piccoli e molti grandi) la memoria verrà usata in modo inefficente.
Algoritmo di Posizionamento
Partizionamento Fisso Uniforme: l’algoritmo è banale, essendo le partizioni tutte di uguale lunghezza si scegli la prima disponibile.
Partizionamento Fisso Uniforme: ogni processo va nella partizione più piccola che può contenerlo, questo minimizza la quantità di spazio sprecato. È possibile utilizzare una coda per ogni partizione, oppure una per tutte per scegliere i processi da inserire.
Partizionamento Dinamico
Il partizionamento dinamico permette di assegnare ad ogni processo esattamente la quantità di memoria di cui ha bisogno.
Questa tecnica permette di risolvere tutti i problemi del Partizionamento Fisso ma ne introduce 2 complessità
- il problema della frammentazione.
- Necessità di un algoritmo per decidere dove e quanto allocare per ogni processo.
Frammentazione
La frammentazione della memoria è un fenomeno indesiderato della partizionamento dinamico che porta alla ad uno speco di memoria.
Ci sono due tipi principali di frammentazione:
Frammentazione interna: il sistema operativo, durante l’allocazione di un blocco di memoria per un processo, tende a riservare una quantità di memoria superiore a quella effettivamente necessaria. Questa pratica è adottata per evitare la necessità di rilocare il processo in un nuovo spazio di memoria ogni qualvolta si verifichi un incremento nella richiesta di spazio. Tuttavia, la porzione non utilizzata di tale blocco, sommata a quella di altri processi che seguono la medesima logica, può comportare uno spreco significativo di memoria nel lungo periodo
Frammentazione esterna: a seguito di ripetute allocazioni, rilocazioni e deallocazioni, si creano spazi di memoria inutilizzati tra i blocchi di memoria allocati. Questi spazi, che possono essere troppo piccoli per soddisfare nuove richieste di allocazione, riducono l’efficienza dell’uso della memoria e possono portare a situazioni in cui, nonostante ci sia memoria disponibile, non è possibile allocarla in modo contiguo per nuovi processi
Soluzione:
- È possibile affrontare il problema della frammentazione attraverso la compattazione. In questo processo, il sistema operativo interviene quando rileva che la memoria è eccessivamente frammentata, riorganizzando i blocchi di memoria per creare spazi contigui. Tuttavia, questa operazione comporta un significativo overhead, poiché richiede tempo e risorse per spostare i dati e aggiornare le informazioni di allocazione.
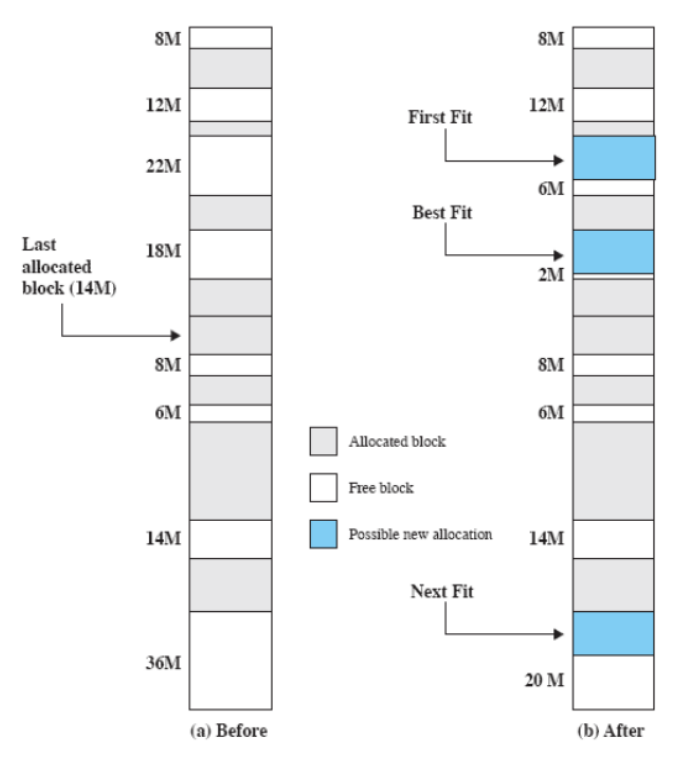
Algoritmo di Inserimento
Il sistema operativo deve decidere a quale blocco di memoria libero assegnare un processo. Esistono diversi algoritmi per gestire questa allocazione:
- Algoritmo Best-Fit: Questo algoritmo seleziona il blocco la cui dimensione è la più vicina (in eccesso) a quella richiesta dal processo da allocare. Nonostante sembri una scelta ragionevole, in realtà produce risultati peggiori, poiché tende a lasciare frammenti di memoria molto piccoli. Di conseguenza, può costringere il sistema a effettuare compattazioni più frequentemente.
- Algoritmo First-Fit: Questo metodo scorre la memoria dall’inizio e seleziona il primo blocco che offre sufficiente spazio per il processo. È molto veloce e tende a riempire principalmente la parte iniziale della memoria. A conti fatti, si è dimostrato essere uno dei migliori algoritmi in termini di prestazioni.
- Algoritmo Next-Fit: Simile al First-Fit, ma anziché partire sempre dall’inizio, inizia dall’ultima posizione in cui è stato assegnato un processo. Questo approccio tende ad allocare più frequentemente i blocchi situati verso la fine della memoria, che sono generalmente più grandi. Tuttavia, ciò può portare alla suddivisione di blocchi di memoria più grandi in porzioni più piccole, rendendo necessaria l’implementazione della compattazione.
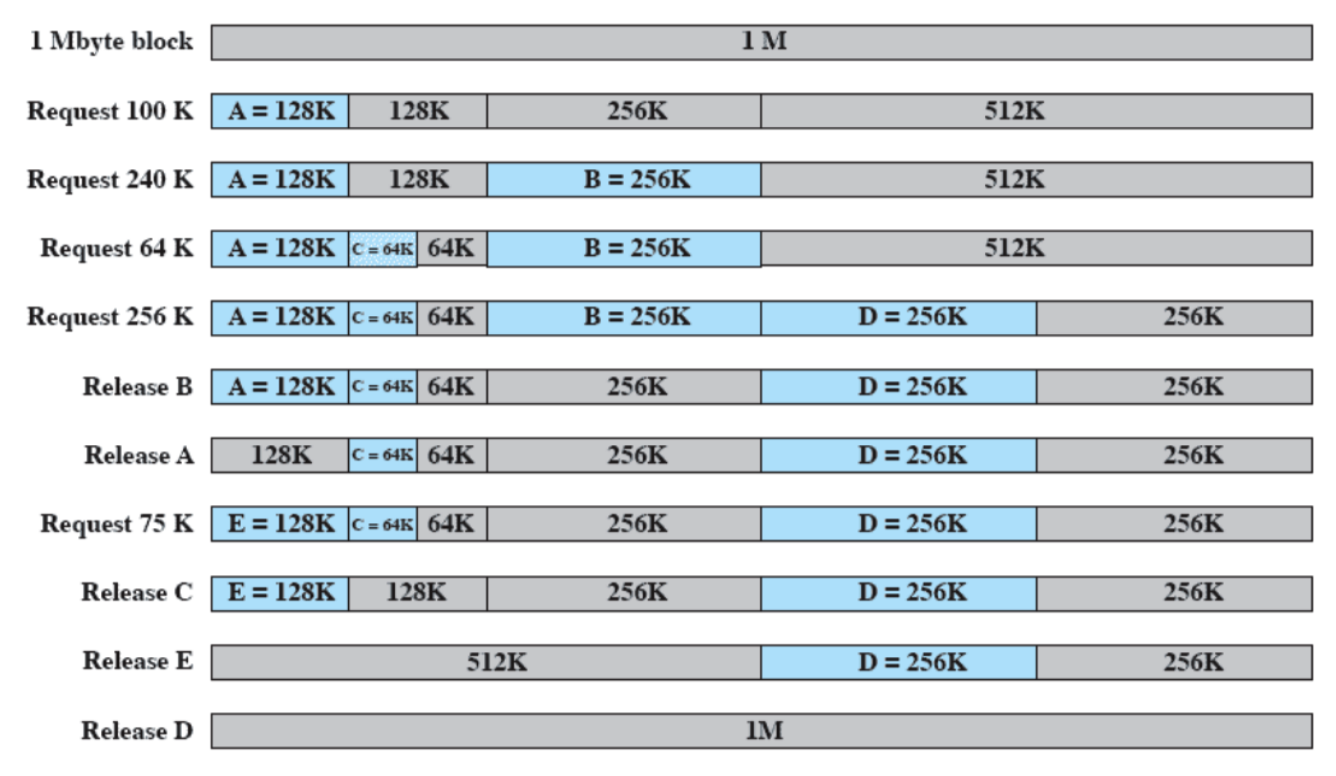
Buddy System
Il Buddy System è un algoritmo di gestione della memoria che utilizza una strategia di allocazione basata su blocchi di dimensioni potenza di due. Questo sistema è progettato per ridurre la frammentazione della memoria e semplificare l’allocazione e la deallocazione.
Funzionamento
- Divisione in blocchi: La memoria disponibile viene inizialmente suddivisa in un blocco di dimensione massima, che è una potenza di due. Quando un processo richiede memoria, il sistema cerca il blocco più piccolo che possa soddisfare la richiesta.
- Suddivisione dei blocchi: Se il blocco trovato è più grande della richiesta, viene suddiviso in due “buddy” (cioè due blocchi di dimensioni uguali). Questo processo può continuare fino a ottenere un blocco della dimensione desiderata.
- Allocazione e deallocazione: Quando un processo termina e libera un blocco di memoria, il sistema verifica se il suo “buddy” (il blocco adiacente) è anch’esso libero. Se lo è, i due blocchi vengono uniti per formare un blocco più grande, riducendo così la frammentazione
Esempio
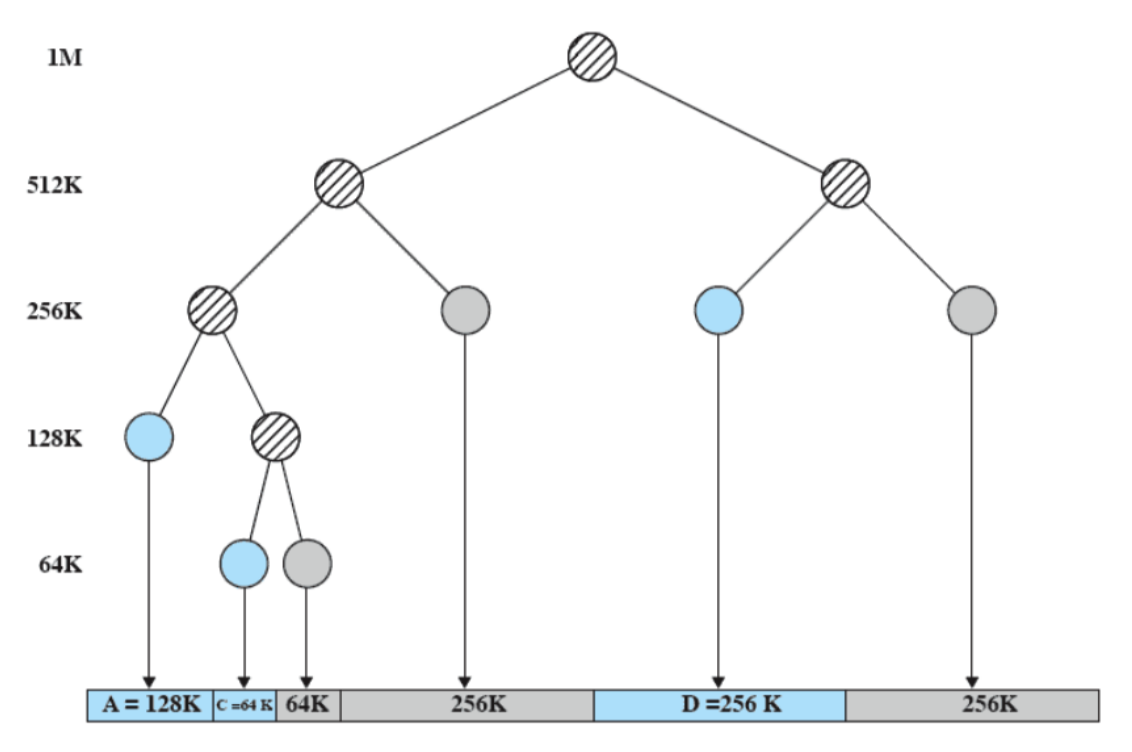
Questo sistema si presta per essere rappresentato da un albero binario: