Introduzione
Le operazioni collettive sono operazioni che coinvolgono tutti i processi di un gruppo di comunicazione (comunicatore), queste operazioni permettono di eseguire azioni coordinate tra tutti i processi, come la comunicazione di dati o la sincronizzazione.
Queste operazioni sono diventate particolarmente importanti nell’ultimo periodo in quanto sono utilizzate nella stragrande maggioranza dei programmi paralleli che vengono eseguiti per il training delle reti neurali odierne. Le grosse aziende di cup/gpu e di informatica, hanno iniziato a produrre delle proprie librerie proprietarie:
- NCCL (Nvidia)
- RCCL (AMD)
- OneCCL (Intel)
- MSCCL (Microsoft)
Infatti MPI durante le operazioni aggregate utilizza delle euristiche per stimare quale sia il miglior modo di condividere i dati fra i nodi, è possibile forzare tale decisione attraverso delle opportune variabili d’ambiente. Il punto è che MPI non è consapevole dell’hardware sul quale i processi sono eseguiti, per questo le aziende hanno iniziato a produrre librerie proprietarie, appositamente ottimizzate per girare sulle piattaforme dedicate.
Attenzione a questo errore
Quando viene chiamata una funzione collettiva, è importante che ogni processo del comunicatore la chiami, altrimenti l’esecuzione rimane bloccata in uno stato di attesa, dato che ogni processo attende che tutti gli altri siano arrivati a tale operazione.
MPI_Reduce
MPI_Reduce permette di eseguire operazioni di aggregazione di risultati senza preoccuparci della logica di comunicazione per il trasferimento dei dati parziali.
- Esempio esaustivo: Calcolo Integrale (MPI)
L’output è un int, in input prende i seguenti parametri:
void* input_data_ppuntatore all’area di memoria in contenente i dati parziali da aggregarevoid* output_data_ppuntatore all’area di memoria in cui verranno salvati il totale dei valori aggregatiint countin numero di elementi da aggregareMPI_Datatype datatypeil tipo dei valoriMPI_Op operatorè l’operazione di aggregazioneint dest_processè il rank del processo che riceverà il risultatoMPI_Comm commè il comunicatore
Nota:
output_data_ppuò essere impostato aNULLin tutti rank diversi dadest_process.
Le operazioni di aggregazione supportate da MPI sono le seguenti:
| Operazione | Significato |
|---|---|
| MPI_MAX | Massimo |
| MPI_MIN | Minimo |
| MPI_SUM | Somma |
| MPI_PROD | Prodotto |
| MPI_LAND | AND logico |
| MPI_BAND | AND bit a bit |
| MPI_LOR | OR logico |
| MPI_BOR | OR bit a bit |
| MPI_LXOR | XOR logico |
| MPI_BXOR | XOR bit a bit |
| MPI_MAXLOC | Massimo insieme al suo indice |
| MPI_MINLOC | Minimo insieme al suo indice |
È possibile anche definire delle operazioni personalizzate tramite la chiamata MPI_Op_create.
MPI_Bcast
PI_Bcast che si occupa di eseguire il broadcast da un processo verso tutti gli altri. I parametri sono i seguenti :
void* data_ppuntatore all’area di memoria:- contenente i dati da condividere, se il processo è il
source_process - che conterrà i dai ricevute, se il processo non è il
source_process
- contenente i dati da condividere, se il processo è il
int countè il numero di elementi da condividereMPI_Datatype datatypeè il tipo dei valori in questioneint source_processè il rank del processo che condivide il valoreMPI_Comm commè il comunicatore
Nota
Utilizza una struttura ad albero che permette di suddividere il carico del lavoro su tutti i nodi e di non pesare solamente sul nodo mittente, creando un albero di condivisione.
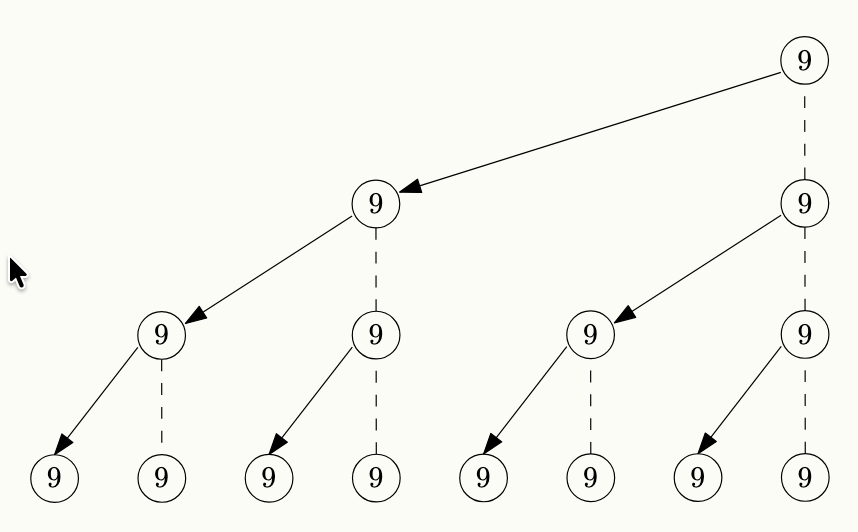
Un caso specifico in cui la MPI_Bcast è molto utile è quando si vuole leggere un input dell utente, infatti soltanto il processo radice (con rank 0) può interagire con l’stdin, e per questo una volta letto l’input molto spesso dovra poi essere condiviso con tutti gli altri nodi, esempio: User Input in MPI.
MPI_Allreduce
Se si vuole fare un operazione di aggregato, per poi avere il risultato condiviso fra tutti i processi, concettualmente, ciò equivale ad eseguire una MPI_Reduce seguita da una MPI_Bcast.
MPI fornisce una funzione, ottimizzata per fare proprio questo ossia MPI_Allreduce , con i seguenti parametri:
void* input_data_ppuntatore all’area di memoria in contenente i dati parziali da aggregarevoid* output_data_ppuntatore all’area di memoria in cui verranno salvati il totale dei valori aggregati (e condivisi)int countin numero di elementi da aggregare (e condividere)MPI_Datatype datatypeil tipo dei valoriMPI_Op operatorè l’operazione di aggregazioneMPI_Comm commè il comunicatore
I parametri sono identici alla MPI_Reduce, eccetto per l’assenza del processo di destinazione, dato che in questo caso, ogni processo avrà il risultato.