Gli insiemi sono collezioni prive di duplicati che estendono la classe AbstractSet ed implementano l’interfaccia Set. Gli oggetti inseriti nei set devono implementare correttamente i metodi hashCode() ed equals().
Esistono diversi tipi di set con diverse caratteristiche:
HashSet
Gli elementi della collezione sono memorizzai in una tabella di hash, questo implica costi di ricerca ed inserimento veloci, e l’assenza di un ordinamento degli elementi.
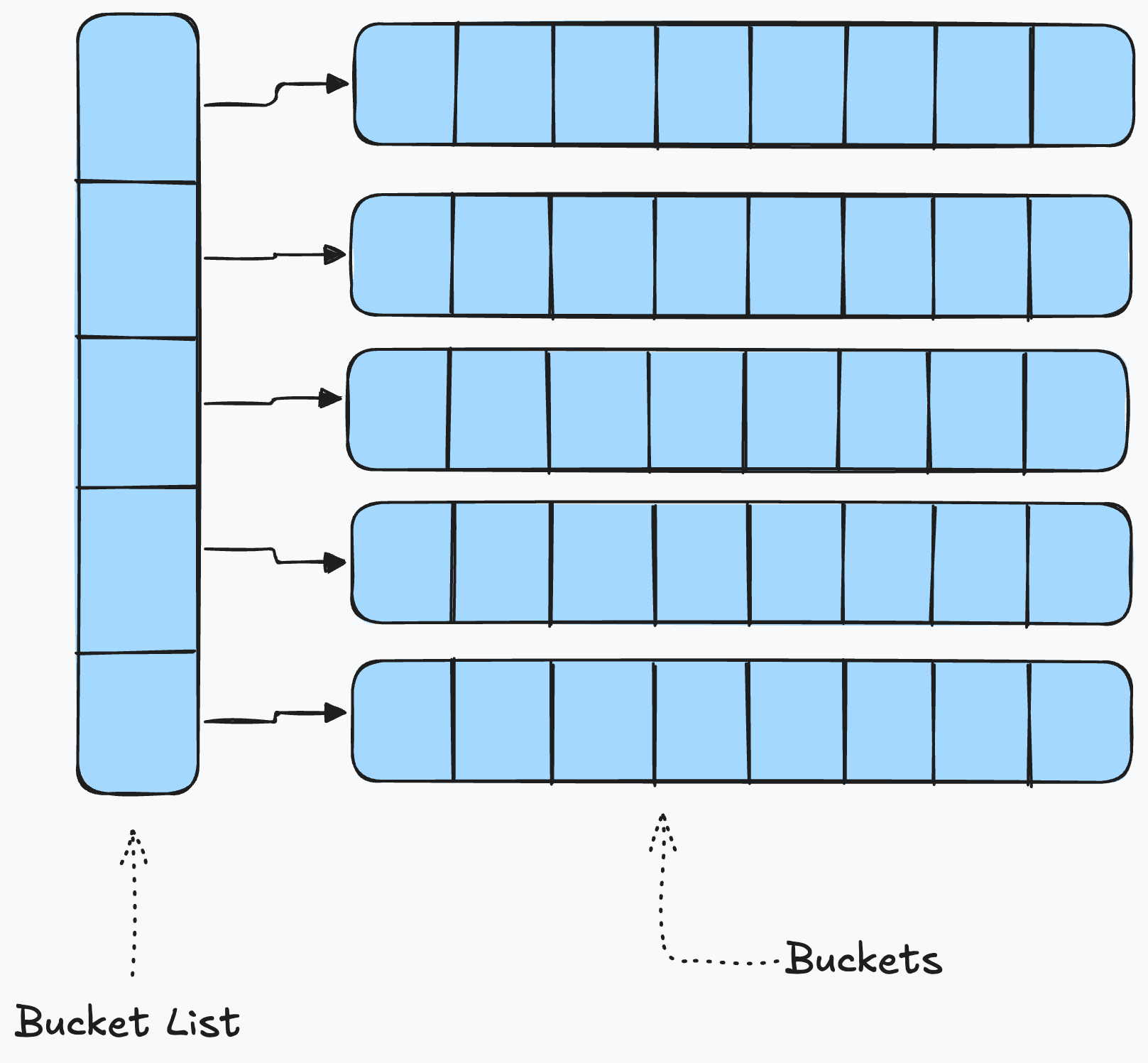
Hash Table
Una tabella di hash è composta da un array principale chiamato bucket list contenete puntatori a delle liste chiamate bucket. La funzione di hash utilizza l’hash code dell oggetto che vogliamo cercare per determinare l’indice della bucket list contenente il puntatore all bucket in cui dovrebbe essere l’oggetto che stiamo cercando. Ora basterà cercare in quel bucket per cercare l’oggetto.
É quindi necessario che elementi uguali abbiano lo stesso hash code che vengano cercati nello stesso bucket e poi confrontati con
equals().
TreeSet
Memorizza gli elementi della collezione in una struttura ad albero mantenendo il loro ordine naturale tramite compareTo(). Questa struttura ci permette di cercare, rimuovere e inserire con costo log(n), dato che è possibile utilizzare la ricerca binaria.
Alberi
LinkedHashSet
Memorizza gli elementi in una tabella hash proprio come un HashSet ma allo stesso tempo mantiene una copia dei dati in una struttura simile ad una LinkedList.
Questo permette di avere le prestazioni del HashSet e allo stesso tempo mantenere l’ordinamento di inserimento attraverso la LinkedList.
Naturalmente questa struttura dati richiede più memoria ed overhead per il mantenimento della due strutture dati.