Related
Problemi
Quando si progetta una base di dati, è fondamentale ridurre la ridondanza dei dati, ovvero la ripetizione di informazioni già presenti nel database. La ridondanza può portare a errori e inconsistenze, specialmente se si utilizzano database non normalizzati. In questi casi, possono verificarsi diversi tipi di errori, tra cui:
Anomalia di aggiornamento: si verifica quando si tenta di aggiornare un dato e si rischia di creare inconsistenze tra le diverse copie del dato.
Anomalia di inserimento: si verifica quando si tenta di inserire un nuovo record e si rischia di creare inconsistenze tra i dati esistenti.
Anomalia di cancellazione: si verifica quando si tenta di cancellare un record e si rischia di creare inconsistenze tra i dati esistenti.
Ridondanza: si verifica quando lo stesso dato è memorizzato più volte in diverse parti del database.
Vincoli
I vincoli sono delle condizioni che devono essere soddisfatte dalla realtà che stiamo progettando. Ad esempio:
- Un voto deve essere compreso tra 18 e 30
- La matricola deve essere univoca
- ecc..
Quando rappresentiamo una realtà, è fondamentale rappresentare anche tutti i suoi vincoli. Un’istanza è considerata legale se soddisfa tutti i vincoli imposti. In questo contesto, ci interessano in particolare le Dipendenze Funzionali, che esprimono dei vincoli di dipendenza tra sottoinsiemi di attributi dello schema.
Le dipendenze funzionali di uno schema esprimono dei vincoli di dipendenza tra sottoinsiemi di attributi dello schema stesso. Questi vincoli devono essere soddisfatti da ogni istanza dello schema. Ad esempio, se abbiamo gli attributi Matricola e Codice Fiscale, nel caso di Matricola uguale, dovrà essere uguale anche il Codice Fiscale.
DBMS
Un sistema di gestione di basi di dati (DBMS) permette di:
- Definire i vincoli insieme allo schema della base di dati
- Verificare che un’istanza sia legale
- Impedire l’inserimento di tuple che violerebbero tali vincoli
Esempio
Vogliamo creare una base di dati per studenti universitari che contiene:
Dati Anagrafici e identificativa:
- Nome, cognome
- Data, comune e provincia di nascita
- Matricola
- Codice Fiscale
Dati curricolari, per ogni esame:
- Voto
- Data
- Codice, Titolo e Docente del corso
Metodo 1 (sbagliato)
Relazione
Creiamo una sola relazione con schema:
Problemi
Ridondanza dei dati: I dati relativi a uno studente vengono ripetuti ogni volta che egli sostiene un esame, mentre i dati relativi a un corso vengono ripetuti per ogni esame sostenuto in quel corso. Ciò comporta un inutile spreco di memoria e aumenta il rischio di errori durante le operazioni di aggiornamento, inserimento e cancellazione.
Anomalia di Aggiornamento: Se il docente di un corso cambia, è necessario aggiornare manualmente tutti gli esami sostenuti in quel corso, il che può essere un’operazione lunga e soggetta a errori.
Anomalia di Inserimento: Non è possibile inserire i dati di uno studente nella relazione se egli non ha ancora sostenuto alcun esame, a meno che non si inseriscano valori NULL per gli attributi relativi agli esami. Ad esempio, se uno studente non ha ancora sostenuto alcun esame, non è possibile inserire i suoi dati nella relazione senza inserire valori NULL per gli attributi relativi agli esami.
Anomalia di Cancellazione: La cancellazione dei dati di uno studente può comportare la cancellazione anche dei dati relativi a un corso, se lo studente è l’unico ad aver sostenuto l’esame di quel corso. Ad esempio, se si cancellano i dati di uno studente che è l’unico ad aver sostenuto l’esame di un corso, si cancellano anche i dati del corso stesso.
Tutti questi problemi sono causati dalla combinazione di informazioni relative a tre entità diverse: corsi, esami e studenti.

Metodo 2 (sbagliato)
Relazione
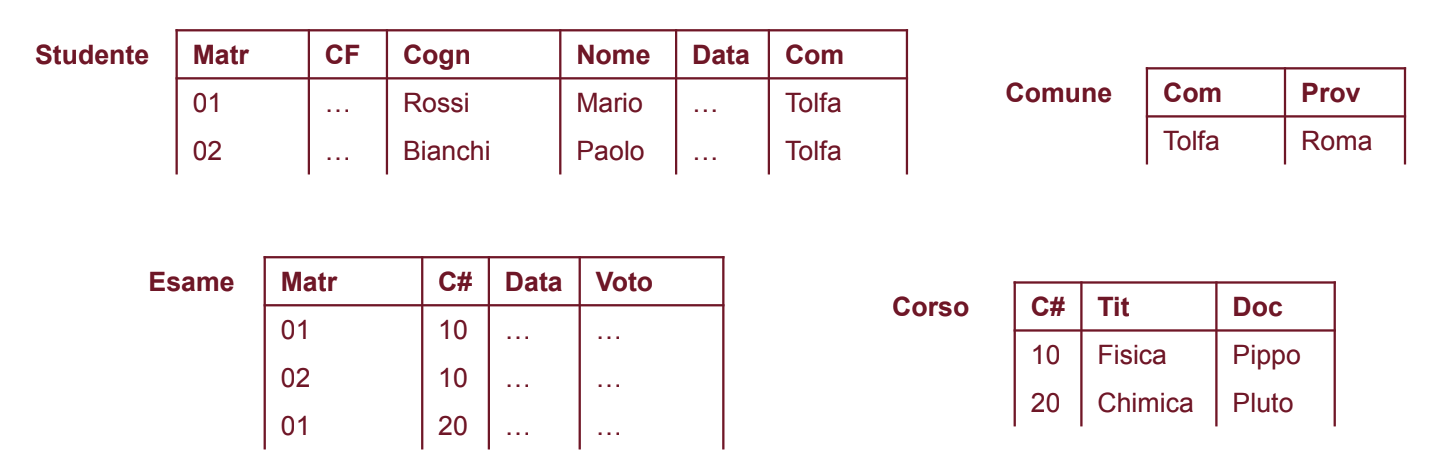
Possiamo dividere le informazioni in tre relazioni separate:
Problemi
Ridondanza: La relazione “Studente” contiene informazioni ridondanti relative ai comuni e alle province, poiché ogni studente di un comune ripete le stesse informazioni sulla provincia di appartenenza.
Anomalia di aggiornamento: Se un comune cambia provincia, è necessario aggiornare manualmente tutte le tuple relative agli studenti di quel comune, il che può essere un’operazione lunga e soggetta a errori.
Anomalia di Inserimento: Non è possibile memorizzare le informazioni relative a un comune e alla sua provincia se non abbiamo almeno uno studente di quel comune, il che limita la nostra capacità di gestire le informazioni relative ai comuni.
Anomalia di Cancellazione: La cancellazione di studenti potrebbe comportare la perdita di informazioni relative ai comuni e alle province, poiché le informazioni relative ai comuni sono legate agli studenti.
Sebbene abbiamo risolto i problemi precedenti (vedi Metodo 1), emerge un nuovo problema relativo alla relazione tra Comune e Provincia, poiché il Comune determina la Provincia e quindi le informazioni relative alla Provincia sono ridondanti.
Metodo 3 (corretto)
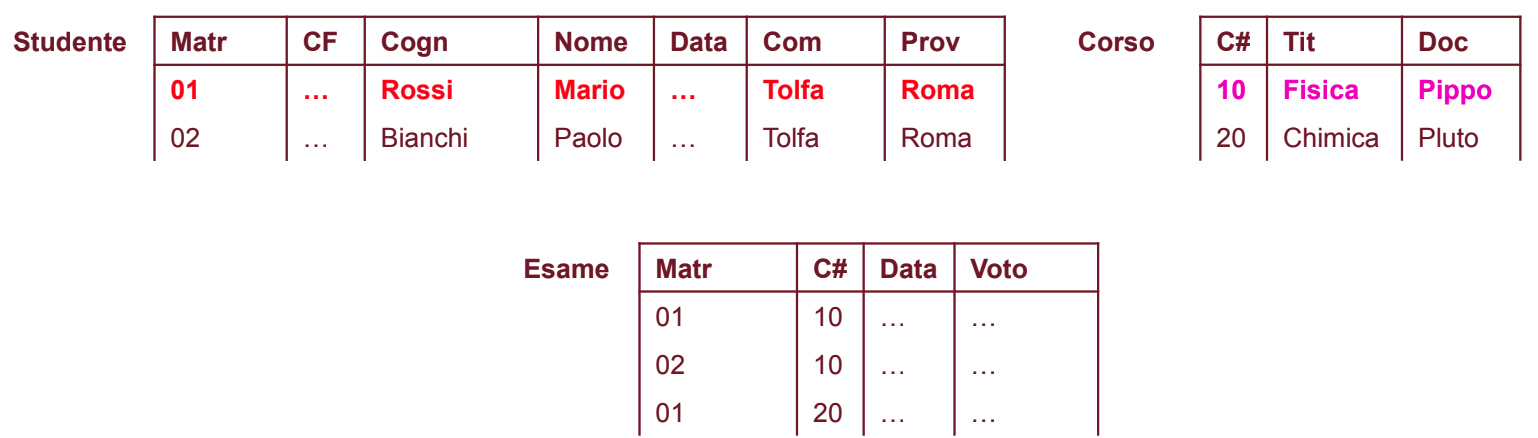
Per risolvere il problema della ridondanza e delle anomalie relative al comune e alla provincia (vidi metodo 2), possiamo creare una nuova relazione “Comune” che contenga le informazioni relative ai comuni e alle province. In questo modo, possiamo eliminare la dipendenza tra la relazione “Studente” e la provincia, e ridurre la ridondanza dei dati.
Relazione:
In questo modo non abbiamo più ridondanze e anomalie.